 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractional Naive Bayes (FNB): non-convex optimization for a parsimonious weighted selective naive Bayes classifier
Sep 17, 2024


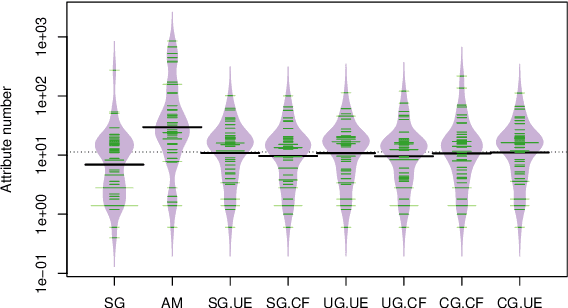
We study supervised classification for datasets with a very large number of input variables. The na\"ive Bayes classifier is attractive for its simplicity, scalability and effectiveness in many real data applications. When the strong na\"ive Bayes assumption of conditional independence of the input variables given the target variable is not valid, variable selection and model averaging are two common ways to improve the performance. In the case of the na\"ive Bayes classifier, the resulting weighting scheme on the models reduces to a weighting scheme on the variables. Here we focus on direct estimation of variable weights in such a weighted na\"ive Bayes classifier. We propose a sparse regularization of the model log-likelihood, which takes into account prior penalization costs related to each input variable. Compared to averaging based classifiers used up until now, our main goal is to obtain parsimonious robust models with less variables and equivalent performance. The direct estimation of the variable weights amounts to a non-convex optimization problem for which we propose and compare several two-stage algorithms. First, the criterion obtained by convex relaxation is minimized using several variants of standard gradient methods. Then, the initial non-convex optimization problem is solved using local optimization methods initialized with the result of the first stage. The various proposed algorithms result in optimization-based weighted na\"ive Bayes classifiers, that are evaluated on benchmark datasets and positioned w.r.t. to a reference averaging-based classifier.
An Efficient Shapley Value Computation for the Naive Bayes Classifier
Jul 31, 2023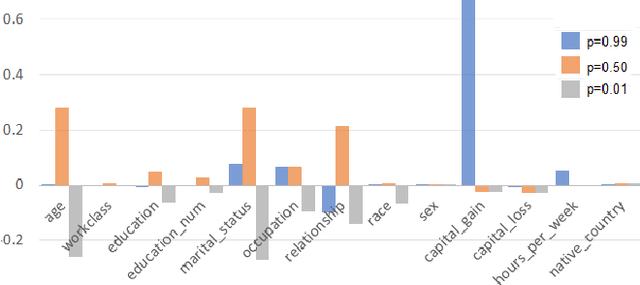
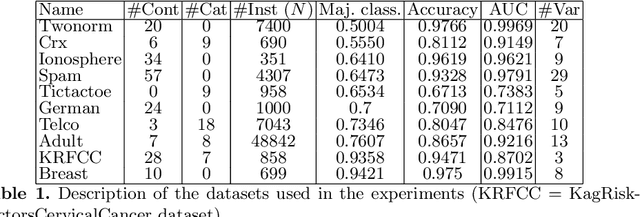
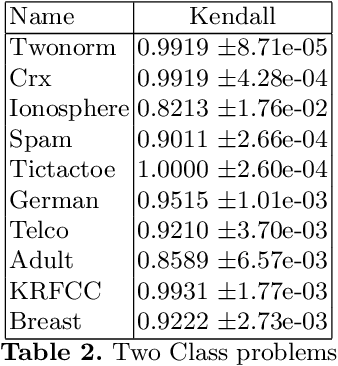
Variable selection or importance measurement of input variables to a machine learning model has become the focus of much research. It is no longer enough to have a good model, one also must explain its decisions. This is why there are so many intelligibility algorithms available today. Among them, Shapley value estimation algorithms are intelligibility methods based on cooperative game theory. In the case of the naive Bayes classifier, and to our knowledge, there is no ``analytical" formulation of Shapley values. This article proposes an exact analytic expression of Shapley values in the special case of the naive Bayes Classifier. We analytically compare this Shapley proposal, to another frequently used indicator, the Weight of Evidence (WoE) and provide an empirical comparison of our proposal with (i) the WoE and (ii) KernelShap results on real world datasets, discussing similar and dissimilar results. The results show that our Shapley proposal for the naive Bayes classifier provides informative results with low algorithmic complexity so that it can be used on very large datasets with extremely low computation time.
Two-level histograms for dealing with outliers and heavy tail distributions
Jun 09, 2023Histograms are among the most popular methods used in exploratory analysis to summarize univariate distributions. In particular, irregular histograms are good non-parametric density estimators that require very few parameters: the number of bins with their lengths and frequencies. Many approaches have been proposed in the literature to infer these parameters, either assuming hypotheses about the underlying data distributions or exploiting a model selection approach. In this paper, we focus on the G-Enum histogram method, which exploits the Minimum Description Length (MDL) principle to build histograms without any user parameter and achieves state-of-the art performance w.r.t accuracy; parsimony and computation time. We investigate on the limits of this method in the case of outliers or heavy-tailed distributions. We suggest a two-level heuristic to deal with such cases. The first level exploits a logarithmic transformation of the data to split the data set into a list of data subsets with a controlled range of values. The second level builds a sub-histogram for each data subset and aggregates them to obtain a complete histogram. Extensive experiments show the benefits of the approach.
Fast and fully-automated histograms for large-scale data sets
Dec 27, 2022G-Enum histograms are a new fast and fully automated method for irregular histogram construction. By framing histogram construction as a density estimation problem and its automation as a model selection task, these histograms leverage the Minimum Description Length principle (MDL) to derive two different model selection criteria. Several proven theoretical results about these criteria give insights about their asymptotic behavior and are used to speed up their optimisation. These insights, combined to a greedy search heuristic, are used to construct histograms in linearithmic time rather than the polynomial time incurred by previous works. The capabilities of the proposed MDL density estimation method are illustrated with reference to other fully automated methods in the literature, both on synthetic and large real-world data sets.
Model Based Co-clustering of Mixed Numerical and Binary Data
Dec 22, 2022Co-clustering is a data mining technique used to extract the underlying block structure between the rows and columns of a data matrix. Many approaches have been studied and have shown their capacity to extract such structures in continuous, binary or contingency tables. However, very little work has been done to perform co-clustering on mixed type data. In this article, we extend the latent block models based co-clustering to the case of mixed data (continuous and binary variables). We then evaluate the effectiveness of the proposed approach on simulated data and we discuss its advantages and potential limits.
Co-clustering based exploratory analysis of mixed-type data tables
Dec 22, 2022Co-clustering is a class of unsupervised data analysis techniques that extract the existing underlying dependency structure between the instances and variables of a data table as homogeneous blocks. Most of those techniques are limited to variables of the same type. In this paper, we propose a mixed data co-clustering method based on a two-step methodology. In the first step, all the variables are binarized according to a number of bins chosen by the analyst, by equal frequency discretization in the numerical case, or keeping the most frequent values in the categorical case. The second step applies a co-clustering to the instances and the binary variables, leading to groups of instances and groups of variable parts. We apply this methodology on several data sets and compare with the results of a Multiple Correspondence Analysis applied to the same data.
Interpretable Feature Construction for Time Series Extrinsic Regression
Mar 15, 2021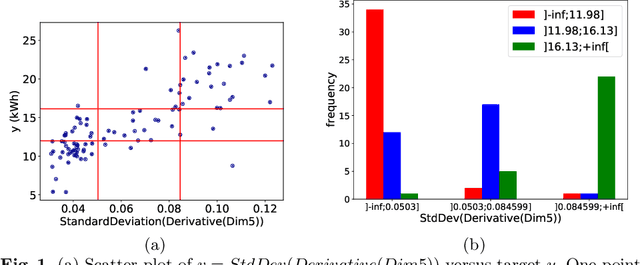
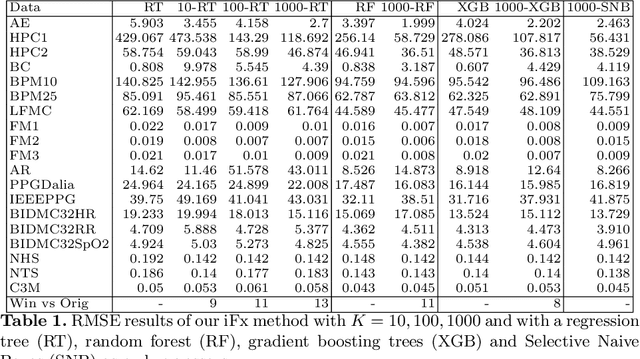
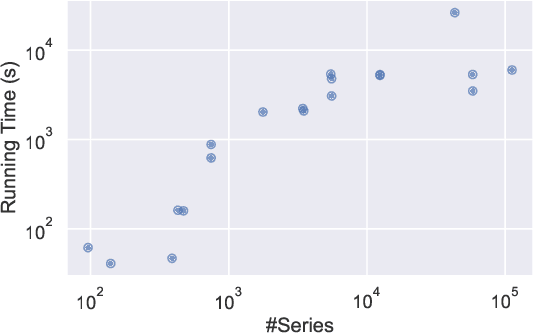
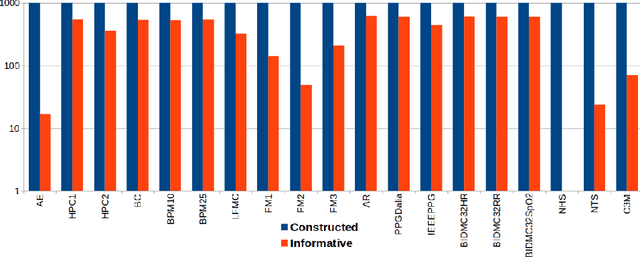
Supervised learning of time series data has been extensively studied for the case of a categorical target variable. In some application domains, e.g., energy, environment and health monitoring, it occurs that the target variable is numerical and the problem is known as time series extrinsic regression (TSER). In the literature, some well-known time series classifiers have been extended for TSER problems. As first benchmarking studies have focused on predictive performance, very little attention has been given to interpretability. To fill this gap, in this paper, we suggest an extension of a Bayesian method for robust and interpretable feature construction and selection in the context of TSER. Our approach exploits a relational way to tackle with TSER: (i), we build various and simple representations of the time series which are stored in a relational data scheme, then, (ii), a propositionalisation technique (based on classical aggregation / selection functions from the relational data field) is applied to build interpretable features from secondary tables to "flatten" the data; and (iii), the constructed features are filtered out through a Bayesian Maximum A Posteriori approach. The resulting transformed data can be processed with various existing regressors. Experimental validation on various benchmark data sets demonstrates the benefits of the suggested approach.
Un modèle Bayésien de co-clustering de données mixtes
Feb 06, 2019
We propose a MAP Bayesian approach to perform and evaluate a co-clustering of mixed-type data tables. The proposed model infers an optimal segmentation of all variables then performs a co-clustering by minimizing a Bayesian model selection cost function. One advantage of this approach is that it is user parameter-free. Another main advantage is the proposed criterion which gives an exact measure of the model quality, measured by probability of fitting it to the data. Continuous optimization of this criterion ensures finding better and better models while avoiding data over-fitting. The experiments conducted on real data show the interest of this co-clustering approach in exploratory data analysis of large data sets.
* in French
Discovering Patterns in Time-Varying Graphs: A Triclustering Approach
Aug 29, 2016


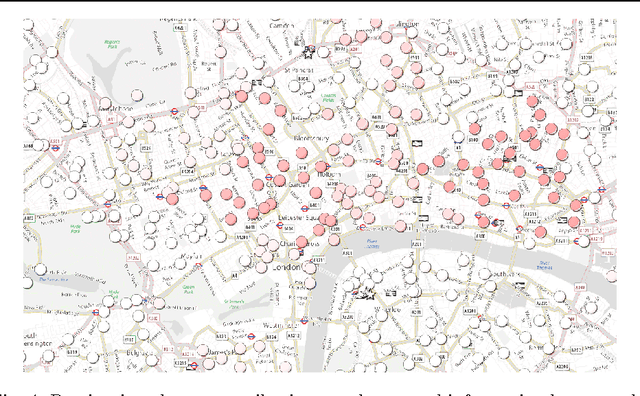
This paper introduces a novel technique to track structures in time varying graphs. The method uses a maximum a posteriori approach for adjusting a three-dimensional co-clustering of the source vertices, the destination vertices and the time, to the data under study, in a way that does not require any hyper-parameter tuning. The three dimensions are simultaneously segmented in order to build clusters of source vertices, destination vertices and time segments where the edge distributions across clusters of vertices follow the same evolution over the time segments. The main novelty of this approach lies in that the time segments are directly inferred from the evolution of the edge distribution between the vertices, thus not requiring the user to make any a priori quantization. Experiments conducted on artificial data illustrate the good behavior of the technique, and a study of a real-life data set shows the potential of the proposed approach for exploratory data analysis.
Co-Clustering Network-Constrained Trajectory Data
Nov 04, 2015

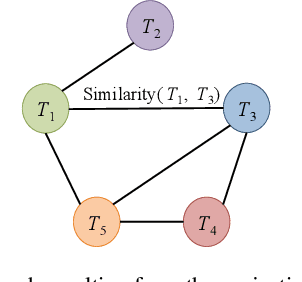

Recently, clustering moving object trajectories kept gaining interest from both the data mining and machine learning communities. This problem, however, was studied mainly and extensively in the setting where moving objects can move freely on the euclidean space. In this paper, we study the problem of clustering trajectories of vehicles whose movement is restricted by the underlying road network. We model relations between these trajectories and road segments as a bipartite graph and we try to cluster its vertices. We demonstrate our approaches on synthetic data and show how it could be useful in inferring knowledge about the flow dynamics and the behavior of the drivers using the road network.