 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpportunistic Target Selection: Early Directional Commitment for Query-Efficient Black-Box Adversarial Attacks
May 25, 2026Black-box adversarial attacks that minimize only the ground-truth confidence suffer from class drift: perturbations wander through the feature space without committing to a specific adversarial class, wasting queries on diffuse, undirected progress. We introduce Opportunistic Target Selection (OTS), a lightweight wrapper that switches an untargeted attack to a targeted objective early in its trajectory, locking onto whichever non-true class currently leads. OTS requires no architectural modification to the underlying attack, no gradient access, and no a priori target-class knowledge. We validate OTS on three score-based attacks (SimBA, Square Attack with cross-entropy loss, and Bandits) across five standard ImageNet classifiers (4,500 runs). On random-search attacks, OTS closely tracks oracle performance, with gains up to +27 pp in success rate and 43% relative reduction in censored-mean iterations on ResNet-50. On gradient-estimation attacks (Bandits) and attacks with margin loss, OTS is redundant, a negative result that reinforces our interpretation of OTS as a margin-loss surrogate. On adversarially-trained models, a bimodal difficulty distribution eliminates the regime where targeting helps.
A probabilistic view on Riemannian machine learning models for SPD matrices
May 05, 2025The goal of this paper is to show how different machine learning tools on the Riemannian manifold $\mathcal{P}_d$ of Symmetric Positive Definite (SPD) matrices can be united under a probabilistic framework. For this, we will need several Gaussian distributions defined on $\mathcal{P}_d$. We will show how popular classifiers on $\mathcal{P}_d$ can be reinterpreted as Bayes Classifiers using these Gaussian distributions. These distributions will also be used for outlier detection and dimension reduction. By showing that those distributions are pervasive in the tools used on $\mathcal{P}_d$, we allow for other machine learning tools to be extended to $\mathcal{P}_d$.
Identifying Obfuscated Code through Graph-Based Semantic Analysis of Binary Code
Apr 02, 2025Protecting sensitive program content is a critical issue in various situations, ranging from legitimate use cases to unethical contexts. Obfuscation is one of the most used techniques to ensure such protection. Consequently, attackers must first detect and characterize obfuscation before launching any attack against it. This paper investigates the problem of function-level obfuscation detection using graph-based approaches, comparing algorithms, from elementary baselines to promising techniques like GNN (Graph Neural Networks), on different feature choices. We consider various obfuscation types and obfuscators, resulting in two complex datasets. Our findings demonstrate that GNNs need meaningful features that capture aspects of function semantics to outperform baselines. Our approach shows satisfactory results, especially in a challenging 11-class classification task and in a practical malware analysis example.
Wrapped Gaussian on the manifold of Symmetric Positive Definite Matrices
Feb 03, 2025


Circular and non-flat data distributions are prevalent across diverse domains of data science, yet their specific geometric structures often remain underutilized in machine learning frameworks. A principled approach to accounting for the underlying geometry of such data is pivotal, particularly when extending statistical models, like the pervasive Gaussian distribution. In this work, we tackle those issue by focusing on the manifold of symmetric positive definite matrices, a key focus in information geometry. We introduced a non-isotropic wrapped Gaussian by leveraging the exponential map, we derive theoretical properties of this distribution and propose a maximum likelihood framework for parameter estimation. Furthermore, we reinterpret established classifiers on SPD through a probabilistic lens and introduce new classifiers based on the wrapped Gaussian model. Experiments on synthetic and real-world datasets demonstrate the robustness and flexibility of this geometry-aware distribution, underscoring its potential to advance manifold-based data analysis. This work lays the groundwork for extending classical machine learning and statistical methods to more complex and structured data.
Meta-survey on outlier and anomaly detection
Dec 12, 2023



The impact of outliers and anomalies on model estimation and data processing is of paramount importance, as evidenced by the extensive body of research spanning various fields over several decades: thousands of research papers have been published on the subject. As a consequence, numerous reviews, surveys, and textbooks have sought to summarize the existing literature, encompassing a wide range of methods from both the statistical and data mining communities. While these endeavors to organize and summarize the research are invaluable, they face inherent challenges due to the pervasive nature of outliers and anomalies in all data-intensive applications, irrespective of the specific application field or scientific discipline. As a result, the resulting collection of papers remains voluminous and somewhat heterogeneous. To address the need for knowledge organization in this domain, this paper implements the first systematic meta-survey of general surveys and reviews on outlier and anomaly detection. Employing a classical systematic survey approach, the study collects nearly 500 papers using two specialized scientific search engines. From this comprehensive collection, a subset of 56 papers that claim to be general surveys on outlier detection is selected using a snowball search technique to enhance field coverage. A meticulous quality assessment phase further refines the selection to a subset of 25 high-quality general surveys. Using this curated collection, the paper investigates the evolution of the outlier detection field over a 20-year period, revealing emerging themes and methods. Furthermore, an analysis of the surveys sheds light on the survey writing practices adopted by scholars from different communities who have contributed to this field. Finally, the paper delves into several topics where consensus has emerged from the literature. These include taxonomies of outlier types, challenges posed by high-dimensional data, the importance of anomaly scores, the impact of learning conditions, difficulties in benchmarking, and the significance of neural networks. Non-consensual aspects are also discussed, particularly the distinction between local and global outliers and the challenges in organizing detection methods into meaningful taxonomies.
Structure-Preserving Transformers for Sequences of SPD Matrices
Sep 25, 2023


In recent years, Transformer-based auto-attention mechanisms have been successfully applied to the analysis of a variety of context-reliant data types, from texts to images and beyond, including data from non-Euclidean geometries. In this paper, we present such a mechanism, designed to classify sequences of Symmetric Positive Definite matrices while preserving their Riemannian geometry throughout the analysis. We apply our method to automatic sleep staging on timeseries of EEG-derived covariance matrices from a standard dataset, obtaining high levels of stage-wise performance.
Challenges in anomaly and change point detection
Dec 27, 2022This paper presents an introduction to the state-of-the-art in anomaly and change-point detection. On the one hand, the main concepts needed to understand the vast scientific literature on those subjects are introduced. On the other, a selection of important surveys and books, as well as two selected active research topics in the field, are presented.
Is the U-Net Directional-Relationship Aware?
Jul 06, 2022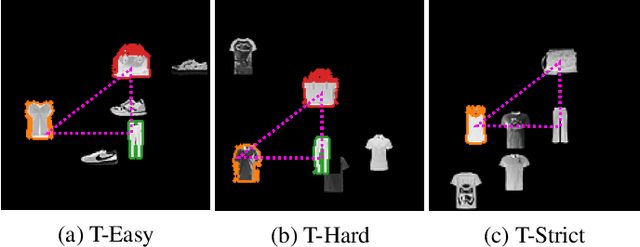
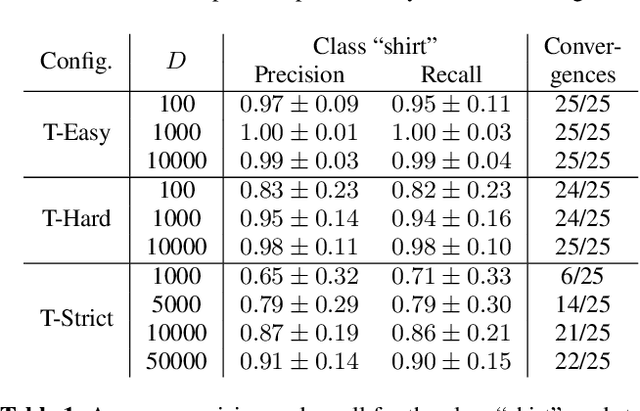
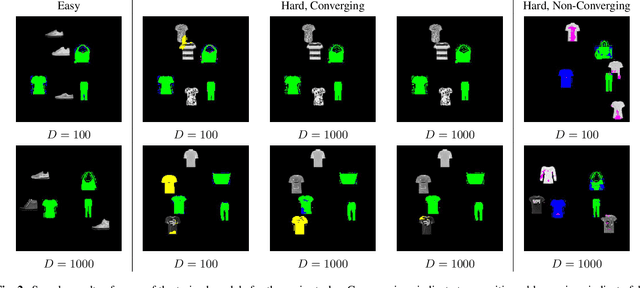
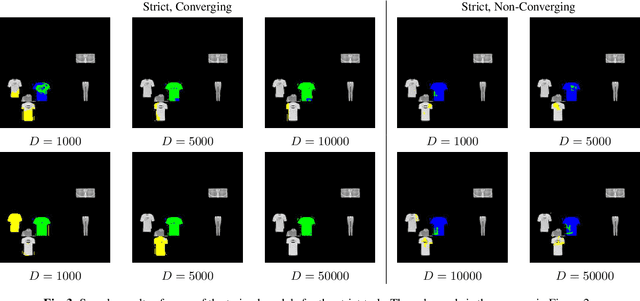
CNNs are often assumed to be capable of using contextual information about distinct objects (such as their directional relations) inside their receptive field. However, the nature and limits of this capacity has never been explored in full. We explore a specific type of relationship~-- directional~-- using a standard U-Net trained to optimize a cross-entropy loss function for segmentation. We train this network on a pretext segmentation task requiring directional relation reasoning for success and state that, with enough data and a sufficiently large receptive field, it succeeds to learn the proposed task. We further explore what the network has learned by analysing scenarios where the directional relationships are perturbed, and show that the network has learned to reason using these relationships.
Multi-winner Approval Voting Goes Epistemic
Jan 17, 2022

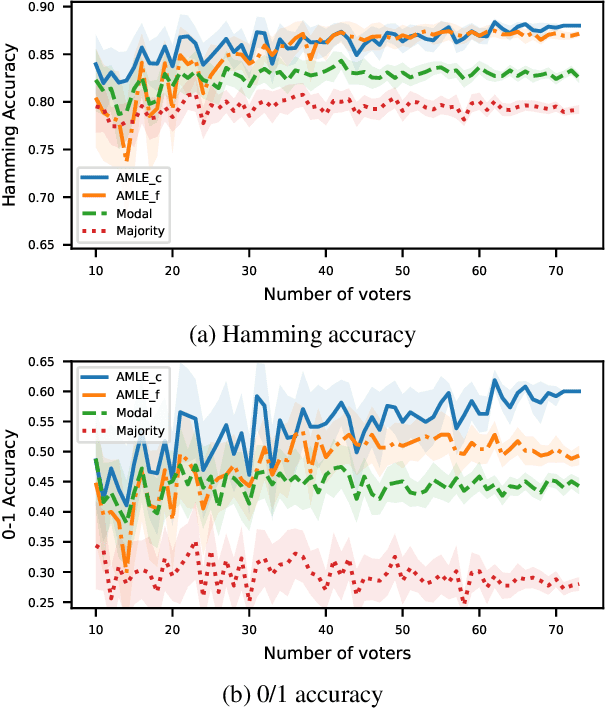
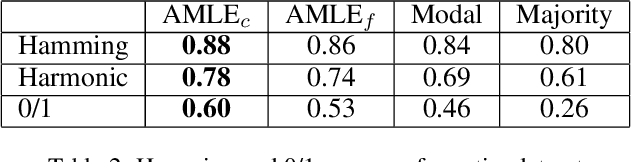
Epistemic voting interprets votes as noisy signals about a ground truth. We consider contexts where the truth consists of a set of objective winners, knowing a lower and upper bound on its cardinality. A prototypical problem for this setting is the aggre-gation of multi-label annotations with prior knowledge on the size of the ground truth. We posit noisemodels, for which we define rules that output an optimal set of winners. We report on experiments on multi-label annotations (which we collected).
Non parametric estimation of causal populations in a counterfactual scenario
Dec 08, 2021

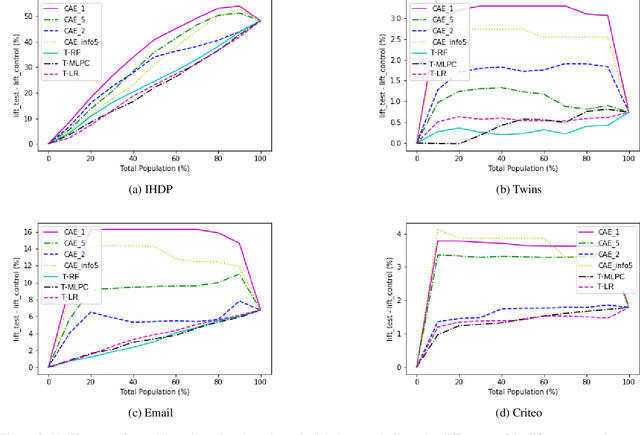
In causality, estimating the effect of a treatment without confounding inference remains a major issue because requires to assess the outcome in both case with and without treatment. Not being able to observe simultaneously both of them, the estimation of potential outcome remains a challenging task. We propose an innovative approach where the problem is reformulated as a missing data model. The aim is to estimate the hidden distribution of \emph{causal populations}, defined as a function of treatment and outcome. A Causal Auto-Encoder (CAE), enhanced by a prior dependent on treatment and outcome information, assimilates the latent space to the probability distribution of the target populations. The features are reconstructed after being reduced to a latent space and constrained by a mask introduced in the intermediate layer of the network, containing treatment and outcome information.