 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Reinforcement Learning Agents with Local Guides
Feb 21, 2024



This paper addresses the problem of integrating local guide policies into a Reinforcement Learning agent. For this, we show how to adapt existing algorithms to this setting before introducing a novel algorithm based on a noisy policy-switching procedure. This approach builds on a proper Approximate Policy Evaluation (APE) scheme to provide a perturbation that carefully leads the local guides towards better actions. We evaluated our method on a set of classical Reinforcement Learning problems, including safety-critical systems where the agent cannot enter some areas at the risk of triggering catastrophic consequences. In all the proposed environments, our agent proved to be efficient at leveraging those policies to improve the performance of any APE-based Reinforcement Learning algorithm, especially in its first learning stages.
Improving a Proportional Integral Controller with Reinforcement Learning on a Throttle Valve Benchmark
Feb 21, 2024
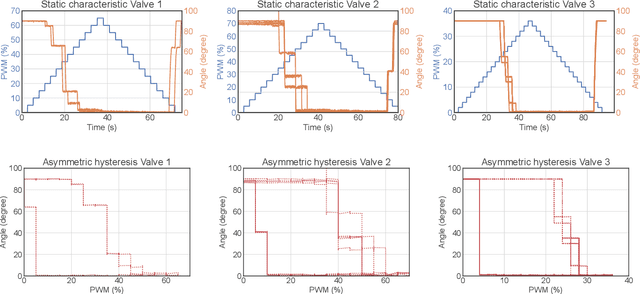
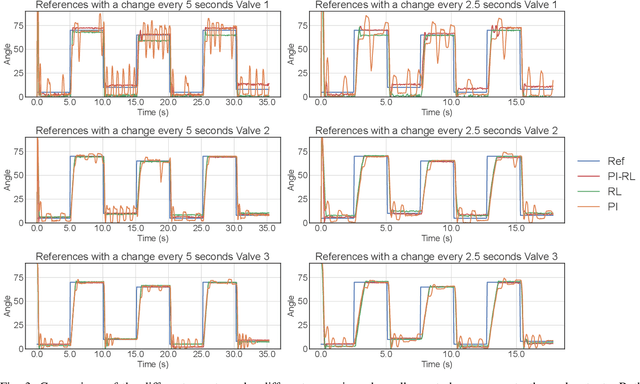
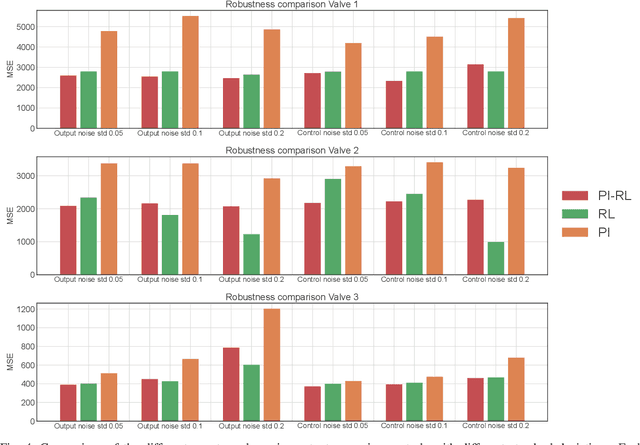
This paper presents a learning-based control strategy for non-linear throttle valves with an asymmetric hysteresis, leading to a near-optimal controller without requiring any prior knowledge about the environment. We start with a carefully tuned Proportional Integrator (PI) controller and exploit the recent advances in Reinforcement Learning (RL) with Guides to improve the closed-loop behavior by learning from the additional interactions with the valve. We test the proposed control method in various scenarios on three different valves, all highlighting the benefits of combining both PI and RL frameworks to improve control performance in non-linear stochastic systems. In all the experimental test cases, the resulting agent has a better sample efficiency than traditional RL agents and outperforms the PI controller.
Conservative Exploration for Policy Optimization via Off-Policy Policy Evaluation
Dec 24, 2023



A precondition for the deployment of a Reinforcement Learning agent to a real-world system is to provide guarantees on the learning process. While a learning algorithm will eventually converge to a good policy, there are no guarantees on the performance of the exploratory policies. We study the problem of conservative exploration, where the learner must at least be able to guarantee its performance is at least as good as a baseline policy. We propose the first conservative provably efficient model-free algorithm for policy optimization in continuous finite-horizon problems. We leverage importance sampling techniques to counterfactually evaluate the conservative condition from the data self-generated by the algorithm. We derive a regret bound and show that (w.h.p.) the conservative constraint is never violated during learning. Finally, we leverage these insights to build a general schema for conservative exploration in DeepRL via off-policy policy evaluation techniques. We show empirically the effectiveness of our methods.
A Trust Region Approach for Few-Shot Sim-to-Real Reinforcement Learning
Dec 24, 2023



Simulation-to-Reality Reinforcement Learning (Sim-to-Real RL) seeks to use simulations to minimize the need for extensive real-world interactions. Specifically, in the few-shot off-dynamics setting, the goal is to acquire a simulator-based policy despite a dynamics mismatch that can be effectively transferred to the real-world using only a handful of real-world transitions. In this context, conventional RL agents tend to exploit simulation inaccuracies resulting in policies that excel in the simulator but underperform in the real environment. To address this challenge, we introduce a novel approach that incorporates a penalty to constrain the trajectories induced by the simulator-trained policy inspired by recent advances in Imitation Learning and Trust Region based RL algorithms. We evaluate our method across various environments representing diverse Sim-to-Real conditions, where access to the real environment is extremely limited. These experiments include high-dimensional systems relevant to real-world applications. Across most tested scenarios, our proposed method demonstrates performance improvements compared to existing baselines.