 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClarifying Ambiguities: on the Role of Ambiguity Types in Prompting Methods for Clarification Generation
Apr 16, 2025



In information retrieval (IR), providing appropriate clarifications to better understand users' information needs is crucial for building a proactive search-oriented dialogue system. Due to the strong in-context learning ability of large language models (LLMs), recent studies investigate prompting methods to generate clarifications using few-shot or Chain of Thought (CoT) prompts. However, vanilla CoT prompting does not distinguish the characteristics of different information needs, making it difficult to understand how LLMs resolve ambiguities in user queries. In this work, we focus on the concept of ambiguity for clarification, seeking to model and integrate ambiguities in the clarification process. To this end, we comprehensively study the impact of prompting schemes based on reasoning and ambiguity for clarification. The idea is to enhance the reasoning abilities of LLMs by limiting CoT to predict first ambiguity types that can be interpreted as instructions to clarify, then correspondingly generate clarifications. We name this new prompting scheme Ambiguity Type-Chain of Thought (AT-CoT). Experiments are conducted on various datasets containing human-annotated clarifying questions to compare AT-CoT with multiple baselines. We also perform user simulations to implicitly measure the quality of generated clarifications under various IR scenarios.
Does constituency analysis enhance domain-specific pre-trained BERT models for relation extraction?
Nov 25, 2021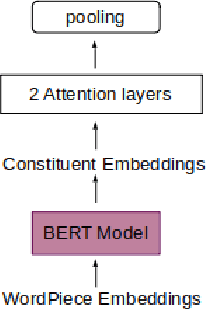
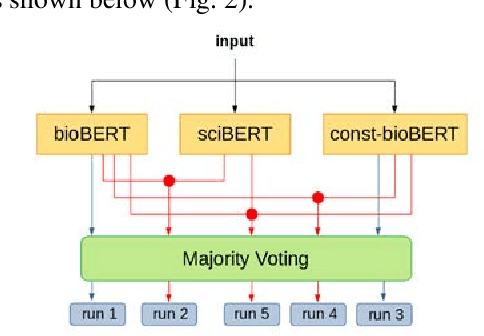
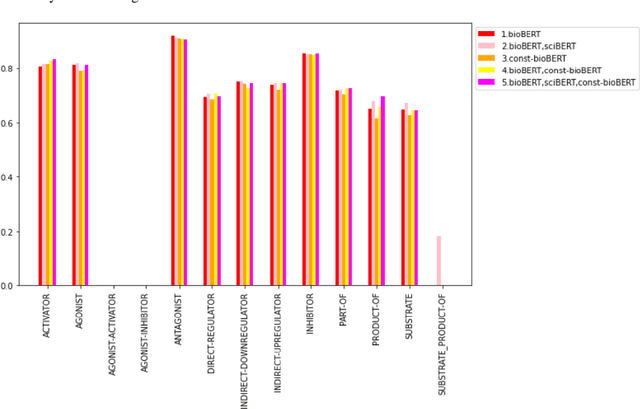
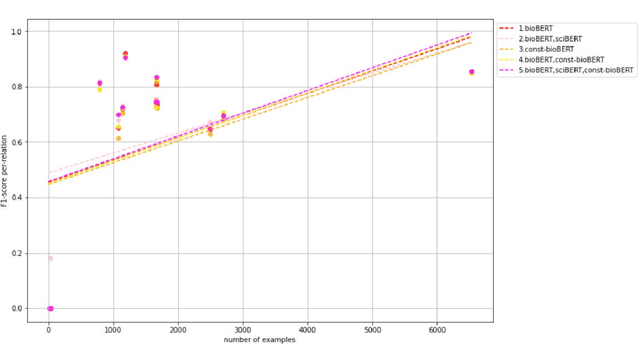
Recently many studies have been conducted on the topic of relation extraction. The DrugProt track at BioCreative VII provides a manually-annotated corpus for the purpose of the development and evaluation of relation extraction systems, in which interactions between chemicals and genes are studied. We describe the ensemble system that we used for our submission, which combines predictions of fine-tuned bioBERT, sciBERT and const-bioBERT models by majority voting. We specifically tested the contribution of syntactic information to relation extraction with BERT. We observed that adding constituentbased syntactic information to BERT improved precision, but decreased recall, since relations rarely seen in the train set were less likely to be predicted by BERT models in which the syntactic information is infused. Our code is available online [https://github.com/Maple177/drugprot-relation-extraction].
Global alignment for relation extraction in Microbiology
Nov 25, 2021
We investigate a method to extract relations from texts based on global alignment and syntactic information. Combined with SVM, this method is shown to have a performance comparable or even better than LSTM on two RE tasks.