 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularization-based Pruning of Irrelevant Weights in Deep Neural Architectures
Apr 11, 2022


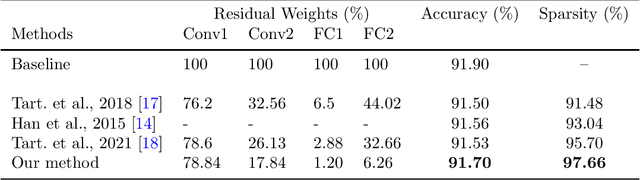
Deep neural networks exploiting millions of parameters are nowadays the norm in deep learning applications. This is a potential issue because of the great amount of computational resources needed for training, and of the possible loss of generalization performance of overparametrized networks. We propose in this paper a method for learning sparse neural topologies via a regularization technique which identifies non relevant weights and selectively shrinks their norm, while performing a classic update for relevant ones. This technique, which is an improvement of classical weight decay, is based on the definition of a regularization term which can be added to any loss functional regardless of its form, resulting in a unified general framework exploitable in many different contexts. The actual elimination of parameters identified as irrelevant is handled by an iterative pruning algorithm. We tested the proposed technique on different image classification and Natural language generation tasks, obtaining results on par or better then competitors in terms of sparsity and metrics, while achieving strong models compression.