 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-QuestEval: A Referenceless Metric for Data to Text Semantic Evaluation
Apr 15, 2021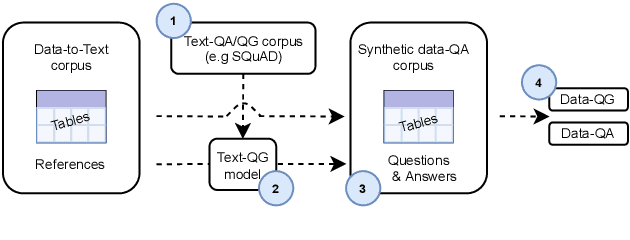
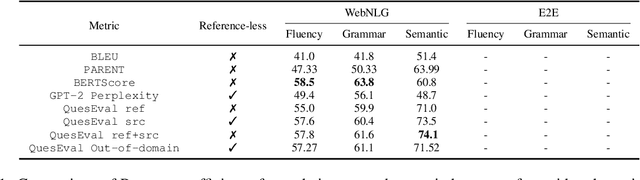

In this paper, we explore how QuestEval, which is a Text-vs-Text metric, can be adapted for the evaluation of Data-to-Text Generation systems. QuestEval is a reference-less metric that compares the predictions directly to the structured input data by automatically asking and answering questions. Its adaptation to Data-to-Text is not straightforward as it requires multi-modal Question Generation and Answering (QG \& QA) systems. To this purpose, we propose to build synthetic multi-modal corpora that enables to train multi-modal QG/QA. The resulting metric is reference-less, multi-modal; it obtains state-of-the-art correlations with human judgement on the E2E and WebNLG benchmark.
Controlling Hallucinations at Word Level in Data-to-Text Generation
Feb 04, 2021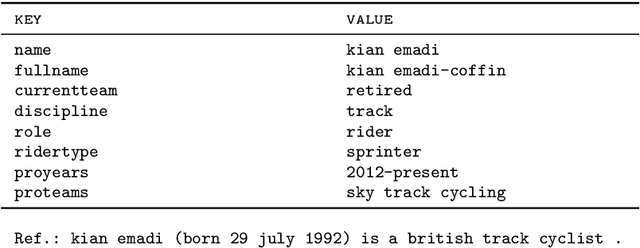
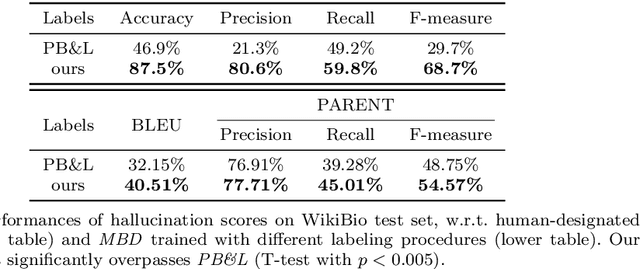
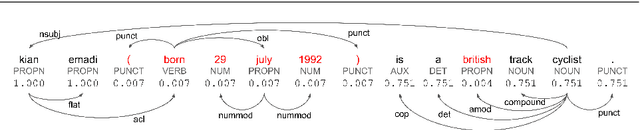
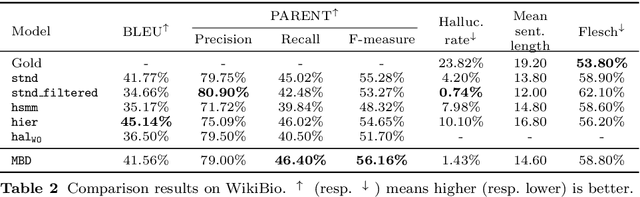
Data-to-Text Generation (DTG) is a subfield of Natural Language Generation aiming at transcribing structured data in natural language descriptions. The field has been recently boosted by the use of neural-based generators which exhibit on one side great syntactic skills without the need of hand-crafted pipelines; on the other side, the quality of the generated text reflects the quality of the training data, which in realistic settings only offer imperfectly aligned structure-text pairs. Consequently, state-of-art neural models include misleading statements - usually called hallucinations - in their outputs. The control of this phenomenon is today a major challenge for DTG, and is the problem addressed in the paper. Previous work deal with this issue at the instance level: using an alignment score for each table-reference pair. In contrast, we propose a finer-grained approach, arguing that hallucinations should rather be treated at the word level. Specifically, we propose a Multi-Branch Decoder which is able to leverage word-level labels to learn the relevant parts of each training instance. These labels are obtained following a simple and efficient scoring procedure based on co-occurrence analysis and dependency parsing. Extensive evaluations, via automated metrics and human judgment on the standard WikiBio benchmark, show the accuracy of our alignment labels and the effectiveness of the proposed Multi-Branch Decoder. Our model is able to reduce and control hallucinations, while keeping fluency and coherence in generated texts. Further experiments on a degraded version of ToTTo show that our model could be successfully used on very noisy settings.
PARENTing via Model-Agnostic Reinforcement Learning to Correct Pathological Behaviors in Data-to-Text Generation
Oct 22, 2020
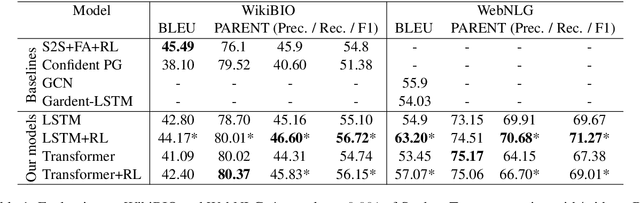

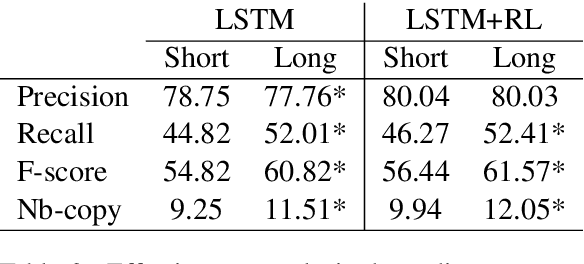
In language generation models conditioned by structured data, the classical training via maximum likelihood almost always leads models to pick up on dataset divergence (i.e., hallucinations or omissions), and to incorporate them erroneously in their own generations at inference. In this work, we build ontop of previous Reinforcement Learning based approaches and show that a model-agnostic framework relying on the recently introduced PARENT metric is efficient at reducing both hallucinations and omissions. Evaluations on the widely used WikiBIO and WebNLG benchmarks demonstrate the effectiveness of this framework compared to state-of-the-art models.
A Hierarchical Model for Data-to-Text Generation
Dec 20, 2019
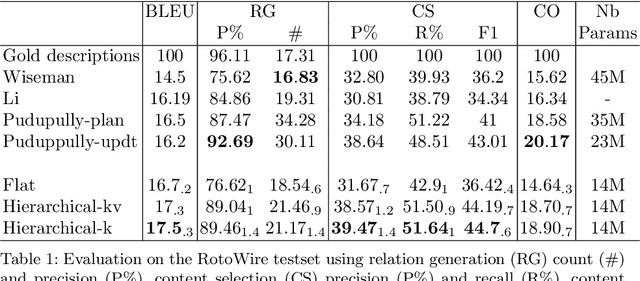
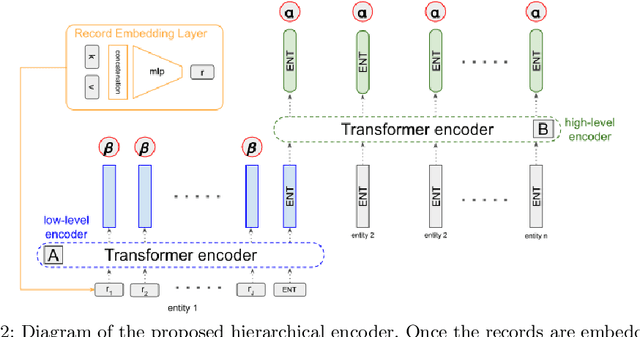

Transcribing structured data into natural language descriptions has emerged as a challenging task, referred to as "data-to-text". These structures generally regroup multiple elements, as well as their attributes. Most attempts rely on translation encoder-decoder methods which linearize elements into a sequence. This however loses most of the structure contained in the data. In this work, we propose to overpass this limitation with a hierarchical model that encodes the data-structure at the element-level and the structure level. Evaluations on RotoWire show the effectiveness of our model w.r.t. qualitative and quantitative metrics.