Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARENTing via Model-Agnostic Reinforcement Learning to Correct Pathological Behaviors in Data-to-Text Generation
Paper and Code

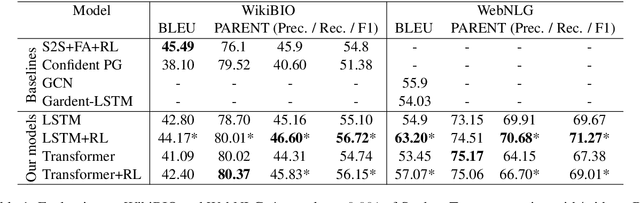

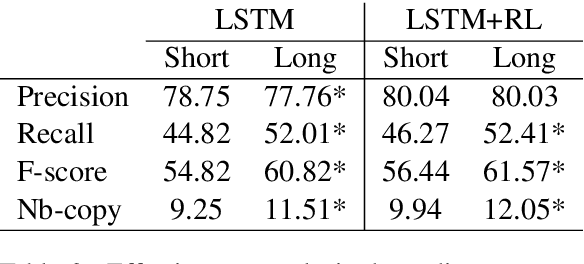
In language generation models conditioned by structured data, the classical training via maximum likelihood almost always leads models to pick up on dataset divergence (i.e., hallucinations or omissions), and to incorporate them erroneously in their own generations at inference. In this work, we build ontop of previous Reinforcement Learning based approaches and show that a model-agnostic framework relying on the recently introduced PARENT metric is efficient at reducing both hallucinations and omissions. Evaluations on the widely used WikiBIO and WebNLG benchmarks demonstrate the effectiveness of this framework compared to state-of-the-art models.
* Accepted at the 13th International Conference on Natural Language
Generation (INLG 2020)
View paper on