 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-MAP: Are Autoregressive Large Language Models Implicit Teachers for Diffusion Large Language Models?
Feb 03, 2026Diffusion Large Language Models (DLLMs) have emerged as a powerful alternative to autoregressive models, enabling parallel token generation across multiple positions. However, preference alignment of DLLMs remains challenging due to high variance introduced by Evidence Lower Bound (ELBO)-based likelihood estimation. In this work, we propose AR-MAP, a novel transfer learning framework that leverages preference-aligned autoregressive LLMs (AR-LLMs) as implicit teachers for DLLM alignment. We reveal that DLLMs can effectively absorb alignment knowledge from AR-LLMs through simple weight scaling, exploiting the shared architectural structure between these divergent generation paradigms. Crucially, our approach circumvents the high variance and computational overhead of direct DLLM alignment and comprehensive experiments across diverse preference alignment tasks demonstrate that AR-MAP achieves competitive or superior performance compared to existing DLLM-specific alignment methods, achieving 69.08\% average score across all tasks and models. Our Code is available at https://github.com/AMAP-ML/AR-MAP.
Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models
Jan 29, 2026Text-to-image (T2I) models have achieved remarkable success in generating high-fidelity images, but they often fail in handling complex spatial relationships, e.g., spatial perception, reasoning, or interaction. These critical aspects are largely overlooked by current benchmarks due to their short or information-sparse prompt design. In this paper, we introduce SpatialGenEval, a new benchmark designed to systematically evaluate the spatial intelligence of T2I models, covering two key aspects: (1) SpatialGenEval involves 1,230 long, information-dense prompts across 25 real-world scenes. Each prompt integrates 10 spatial sub-domains and corresponding 10 multi-choice question-answer pairs, ranging from object position and layout to occlusion and causality. Our extensive evaluation of 21 state-of-the-art models reveals that higher-order spatial reasoning remains a primary bottleneck. (2) To demonstrate that the utility of our information-dense design goes beyond simple evaluation, we also construct the SpatialT2I dataset. It contains 15,400 text-image pairs with rewritten prompts to ensure image consistency while preserving information density. Fine-tuned results on current foundation models (i.e., Stable Diffusion-XL, Uniworld-V1, OmniGen2) yield consistent performance gains (+4.2%, +5.7%, +4.4%) and more realistic effects in spatial relations, highlighting a data-centric paradigm to achieve spatial intelligence in T2I models.
Learning Geometric Invariance for Gait Recognition
Jan 09, 2026The goal of gait recognition is to extract identity-invariant features of an individual under various gait conditions, e.g., cross-view and cross-clothing. Most gait models strive to implicitly learn the common traits across different gait conditions in a data-driven manner to pull different gait conditions closer for recognition. However, relatively few studies have explicitly explored the inherent relations between different gait conditions. For this purpose, we attempt to establish connections among different gait conditions and propose a new perspective to achieve gait recognition: variations in different gait conditions can be approximately viewed as a combination of geometric transformations. In this case, all we need is to determine the types of geometric transformations and achieve geometric invariance, then identity invariance naturally follows. As an initial attempt, we explore three common geometric transformations (i.e., Reflect, Rotate, and Scale) and design a $\mathcal{R}$eflect-$\mathcal{R}$otate-$\mathcal{S}$cale invariance learning framework, named ${\mathcal{RRS}}$-Gait. Specifically, it first flexibly adjusts the convolution kernel based on the specific geometric transformations to achieve approximate feature equivariance. Then these three equivariant-aware features are respectively fed into a global pooling operation for final invariance-aware learning. Extensive experiments on four popular gait datasets (Gait3D, GREW, CCPG, SUSTech1K) show superior performance across various gait conditions.
QAGait: Revisit Gait Recognition from a Quality Perspective
Jan 24, 2024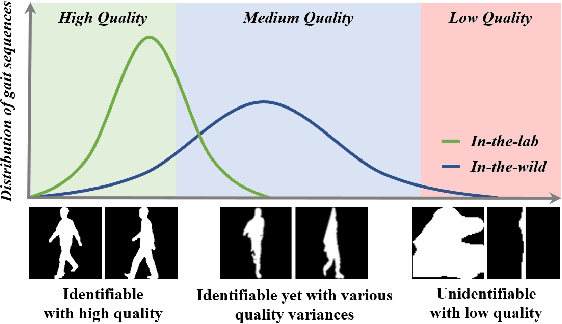
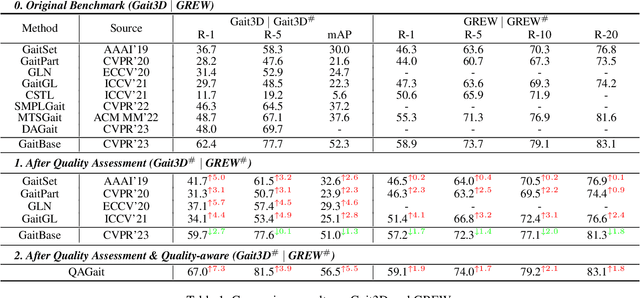
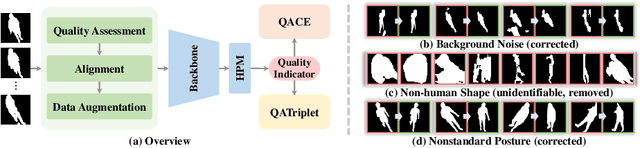
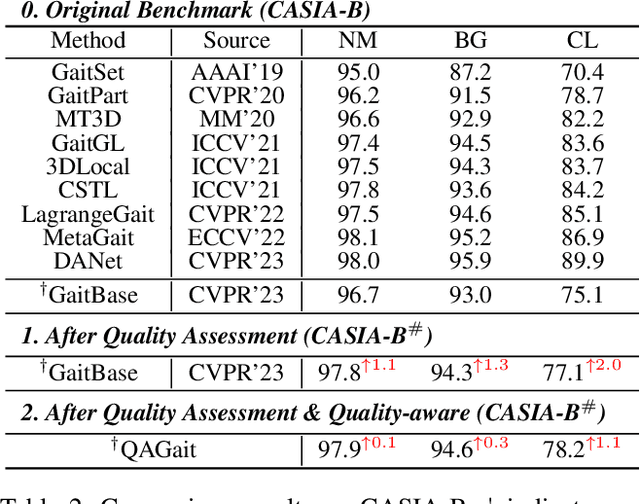
Gait recognition is a promising biometric method that aims to identify pedestrians from their unique walking patterns. Silhouette modality, renowned for its easy acquisition, simple structure, sparse representation, and convenient modeling, has been widely employed in controlled in-the-lab research. However, as gait recognition rapidly advances from in-the-lab to in-the-wild scenarios, various conditions raise significant challenges for silhouette modality, including 1) unidentifiable low-quality silhouettes (abnormal segmentation, severe occlusion, or even non-human shape), and 2) identifiable but challenging silhouettes (background noise, non-standard posture, slight occlusion). To address these challenges, we revisit gait recognition pipeline and approach gait recognition from a quality perspective, namely QAGait. Specifically, we propose a series of cost-effective quality assessment strategies, including Maxmial Connect Area and Template Match to eliminate background noises and unidentifiable silhouettes, Alignment strategy to handle non-standard postures. We also propose two quality-aware loss functions to integrate silhouette quality into optimization within the embedding space. Extensive experiments demonstrate our QAGait can guarantee both gait reliability and performance enhancement. Furthermore, our quality assessment strategies can seamlessly integrate with existing gait datasets, showcasing our superiority. Code is available at https://github.com/wzb-bupt/QAGait.