 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaders make targeted regressions to plausible errors in reanalysis of "noisy-channel garden-path" sentences
May 18, 2026A key question in psycholinguistics is how inferences about the meaning of linguistic input unfold incrementally a comprehender's mind. In this work, we study reading dynamics for ``noisy-channel garden-path'' sentences, which temporarily appear well-formed but feature late-appearing violations of expectation that can be resolved not by inferring an alternative syntactic structure, but by inferring the presence of an error. We find evidence for targeted regressions -- eye movements towards regions that are promising loci of possible errors in light of later-arriving information, showing patterns consistent with the posterior inferences of a model of noisy-channel processing with reanalysis. We discuss the implications of these findings for theories of noisy-channel language comprehension and information-theoretic explanations of reading dynamics.
To Words and Beyond: Probing Large Language Models for Sentence-Level Psycholinguistic Norms of Memorability and Reading Times
Mar 12, 2026Large Language Models (LLMs) have recently been shown to produce estimates of psycholinguistic norms, such as valence, arousal, or concreteness, for words and multiword expressions, that correlate with human judgments. These estimates are obtained by prompting an LLM, in zero-shot fashion, with a question similar to those used in human studies. Meanwhile, for other norms such as lexical decision time or age of acquisition, LLMs require supervised fine-tuning to obtain results that align with ground-truth values. In this paper, we extend this approach to the previously unstudied features of sentence memorability and reading times, which involve the relationship between multiple words in a sentence-level context. Our results show that via fine-tuning, models can provide estimates that correlate with human-derived norms and exceed the predictive power of interpretable baseline predictors, demonstrating that LLMs contain useful information about sentence-level features. At the same time, our results show very mixed zero-shot and few-shot performance, providing further evidence that care is needed when using LLM-prompting as a proxy for human cognitive measures.
A Cross-Linguistic Pressure for Uniform Information Density in Word Order
Jun 06, 2023While natural languages differ widely in both canonical word order and word order flexibility, their word orders still follow shared cross-linguistic statistical patterns, often attributed to functional pressures. In the effort to identify these pressures, prior work has compared real and counterfactual word orders. Yet one functional pressure has been overlooked in such investigations: the uniform information density (UID) hypothesis, which holds that information should be spread evenly throughout an utterance. Here, we ask whether a pressure for UID may have influenced word order patterns cross-linguistically. To this end, we use computational models to test whether real orders lead to greater information uniformity than counterfactual orders. In our empirical study of 10 typologically diverse languages, we find that: (i) among SVO languages, real word orders consistently have greater uniformity than reverse word orders, and (ii) only linguistically implausible counterfactual orders consistently exceed the uniformity of real orders. These findings are compatible with a pressure for information uniformity in the development and usage of natural languages.
Analyzing Wrap-Up Effects through an Information-Theoretic Lens
Mar 31, 2022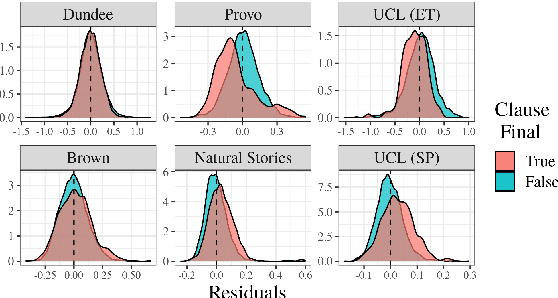
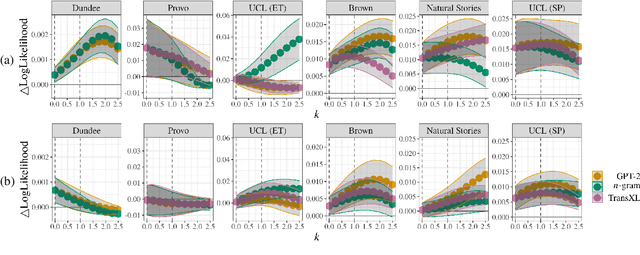
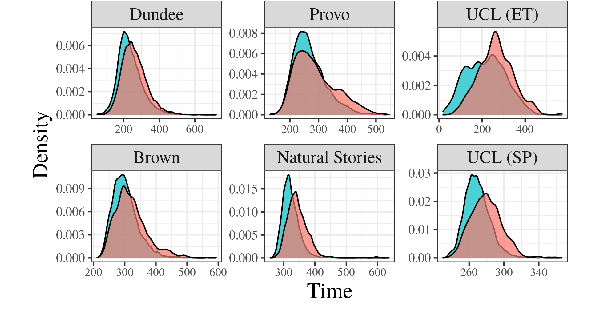
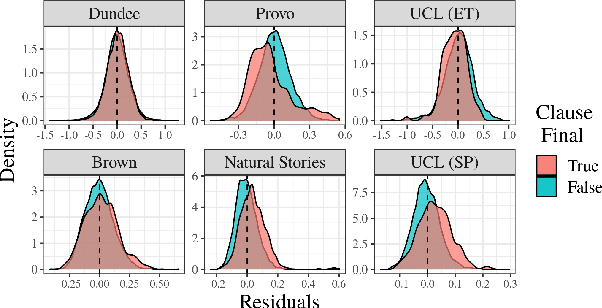
Numerous analyses of reading time (RT) data have been implemented -- all in an effort to better understand the cognitive processes driving reading comprehension. However, data measured on words at the end of a sentence -- or even at the end of a clause -- is often omitted due to the confounding factors introduced by so-called "wrap-up effects," which manifests as a skewed distribution of RTs for these words. Consequently, the understanding of the cognitive processes that might be involved in these wrap-up effects is limited. In this work, we attempt to learn more about these processes by examining the relationship between wrap-up effects and information-theoretic quantities, such as word and context surprisals. We find that the distribution of information in prior contexts is often predictive of sentence- and clause-final RTs (while not of sentence-medial RTs). This lends support to several prior hypotheses about the processes involved in wrap-up effects.
Mixture-of-Partitions: Infusing Large Biomedical Knowledge Graphs into BERT
Sep 10, 2021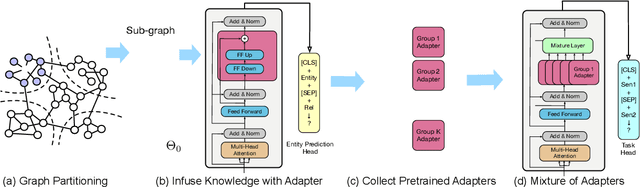

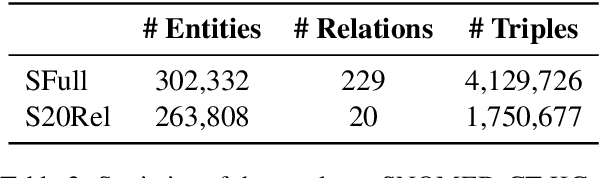
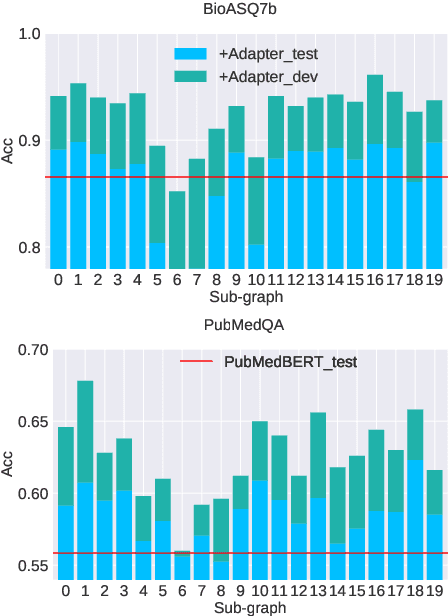
Infusing factual knowledge into pre-trained models is fundamental for many knowledge-intensive tasks. In this paper, we proposed Mixture-of-Partitions (MoP), an infusion approach that can handle a very large knowledge graph (KG) by partitioning it into smaller sub-graphs and infusing their specific knowledge into various BERT models using lightweight adapters. To leverage the overall factual knowledge for a target task, these sub-graph adapters are further fine-tuned along with the underlying BERT through a mixture layer. We evaluate our MoP with three biomedical BERTs (SciBERT, BioBERT, PubmedBERT) on six downstream tasks (inc. NLI, QA, Classification), and the results show that our MoP consistently enhances the underlying BERTs in task performance, and achieves new SOTA performances on five evaluated datasets.