 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe unreasonable effectiveness of pattern matching
Jan 16, 2026We report on an astonishing ability of large language models (LLMs) to make sense of "Jabberwocky" language in which most or all content words have been randomly replaced by nonsense strings, e.g., translating "He dwushed a ghanc zawk" to "He dragged a spare chair". This result addresses ongoing controversies regarding how to best think of what LLMs are doing: are they a language mimic, a database, a blurry version of the Web? The ability of LLMs to recover meaning from structural patterns speaks to the unreasonable effectiveness of pattern-matching. Pattern-matching is not an alternative to "real" intelligence, but rather a key ingredient.
Large language models have learned to use language
Dec 13, 2025
Acknowledging that large language models have learned to use language can open doors to breakthrough language science. Achieving these breakthroughs may require abandoning some long-held ideas about how language knowledge is evaluated and reckoning with the difficult fact that we have entered a post-Turing test era.
How important is language for human-like intelligence?
Sep 19, 2025We use language to communicate our thoughts. But is language merely the expression of thoughts, which are themselves produced by other, nonlinguistic parts of our minds? Or does language play a more transformative role in human cognition, allowing us to have thoughts that we otherwise could (or would) not have? Recent developments in artificial intelligence (AI) and cognitive science have reinvigorated this old question. We argue that language may hold the key to the emergence of both more general AI systems and central aspects of human intelligence. We highlight two related properties of language that make it such a powerful tool for developing domain--general abilities. First, language offers compact representations that make it easier to represent and reason about many abstract concepts (e.g., exact numerosity). Second, these compressed representations are the iterated output of collective minds. In learning a language, we learn a treasure trove of culturally evolved abstractions. Taken together, these properties mean that a sufficiently powerful learning system exposed to language--whether biological or artificial--learns a compressed model of the world, reverse engineering many of the conceptual and causal structures that support human (and human-like) thought.
Language models align with human judgments on key grammatical constructions
Jan 19, 2024

Do Large Language Models (LLMs) make human-like linguistic generalizations? Dentella et al. (2023; "DGL") prompt several LLMs ("Is the following sentence grammatically correct in English?") to elicit grammaticality judgments of 80 English sentences, concluding that LLMs demonstrate a "yes-response bias" and a "failure to distinguish grammatical from ungrammatical sentences". We re-evaluate LLM performance using well-established practices and find that DGL's data in fact provide evidence for just how well LLMs capture human behaviors. Models not only achieve high accuracy overall, but also capture fine-grained variation in human linguistic judgments.
Can We Distinguish Machine Learning from Human Learning?
Oct 08, 2019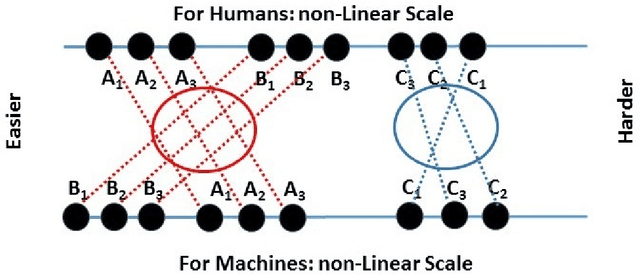
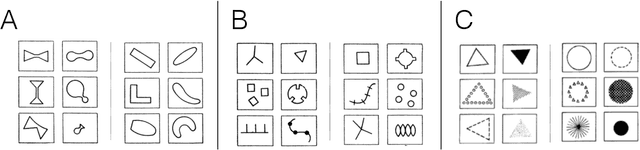


What makes a task relatively more or less difficult for a machine compared to a human? Much AI/ML research has focused on expanding the range of tasks that machines can do, with a focus on whether machines can beat humans. Allowing for differences in scale, we can seek interesting (anomalous) pairs of tasks T, T'. We define interesting in this way: The "harder to learn" relation is reversed when comparing human intelligence (HI) to AI. While humans seems to be able to understand problems by formulating rules, ML using neural networks does not rely on constructing rules. We discuss a novel approach where the challenge is to "perform well under rules that have been created by human beings." We suggest that this provides a rigorous and precise pathway for understanding the difference between the two kinds of learning. Specifically, we suggest a large and extensible class of learning tasks, formulated as learning under rules. With these tasks, both the AI and HI will be studied with rigor and precision. The immediate goal is to find interesting groundtruth rule pairs. In the long term, the goal will be to understand, in a generalizable way, what distinguishes interesting pairs from ordinary pairs, and to define saliency behind interesting pairs. This may open new ways of thinking about AI, and provide unexpected insights into human learning.