 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistic communication as (inverse) reward design
Paper and Code
Apr 11, 2022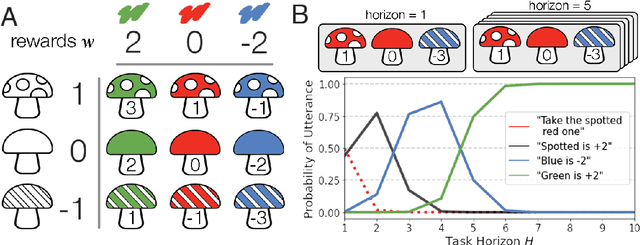
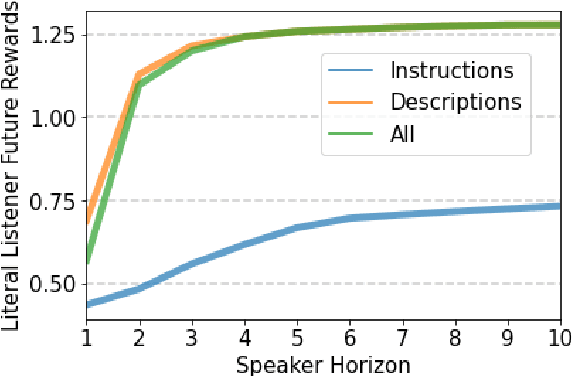
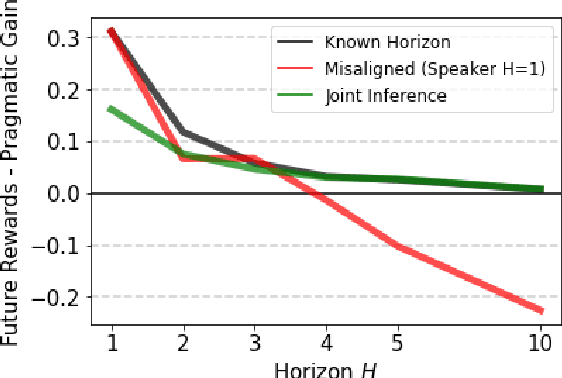
Natural language is an intuitive and expressive way to communicate reward information to autonomous agents. It encompasses everything from concrete instructions to abstract descriptions of the world. Despite this, natural language is often challenging to learn from: it is difficult for machine learning methods to make appropriate inferences from such a wide range of input. This paper proposes a generalization of reward design as a unifying principle to ground linguistic communication: speakers choose utterances to maximize expected rewards from the listener's future behaviors. We first extend reward design to incorporate reasoning about unknown future states in a linear bandit setting. We then define a speaker model which chooses utterances according to this objective. Simulations show that short-horizon speakers (reasoning primarily about a single, known state) tend to use instructions, while long-horizon speakers (reasoning primarily about unknown, future states) tend to describe the reward function. We then define a pragmatic listener which performs inverse reward design by jointly inferring the speaker's latent horizon and rewards. Our findings suggest that this extension of reward design to linguistic communication, including the notion of a latent speaker horizon, is a promising direction for achieving more robust alignment outcomes from natural language supervision.