 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen does data augmentation help generalization in NLP?
Paper and Code
Apr 30, 2020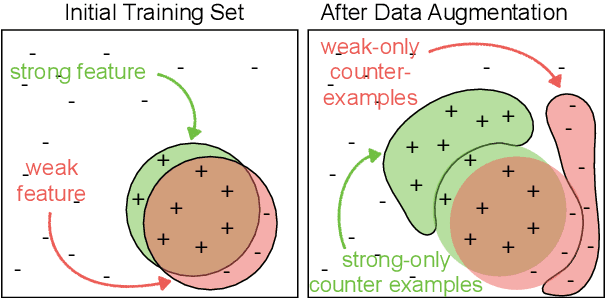

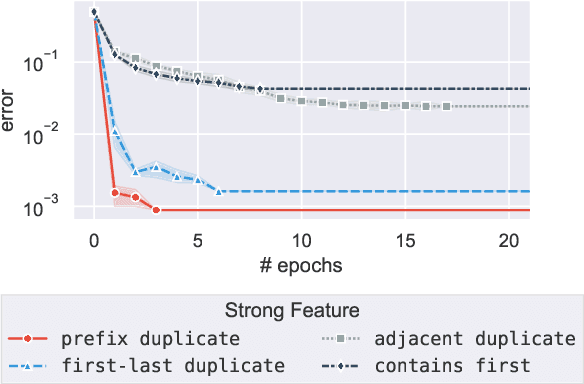

Neural models often exploit superficial ("weak") features to achieve good performance, rather than deriving the more general ("strong") features that we'd prefer a model to use. Overcoming this tendency is a central challenge in areas such as representation learning and ML fairness. Recent work has proposed using data augmentation--that is, generating training examples on which these weak features fail--as a means of encouraging models to prefer the stronger features. We design a series of toy learning problems to investigate the conditions under which such data augmentation is helpful. We show that augmenting with training examples on which the weak feature fails ("counterexamples") does succeed in preventing the model from relying on the weak feature, but often does not succeed in encouraging the model to use the stronger feature in general. We also find in many cases that the number of counterexamples needed to reach a given error rate is independent of the amount of training data, and that this type of data augmentation becomes less effective as the target strong feature becomes harder to learn.