 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual GenQA: A Language-Agnostic Generative Question Answering Approach for Open-Domain Question Answering
Paper and Code
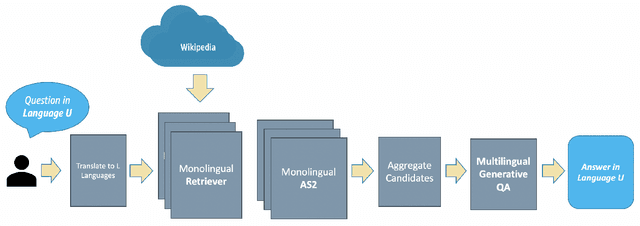



Open-Retrieval Generative Question Answering (GenQA) is proven to deliver high-quality, natural-sounding answers in English. In this paper, we present the first generalization of the GenQA approach for the multilingual environment. To this end, we present the GenTyDiQA dataset, which extends the TyDiQA evaluation data (Clark et al., 2020) with natural-sounding, well-formed answers in Arabic, Bengali, English, Japanese, and Russian. For all these languages, we show that a GenQA sequence-to-sequence-based model outperforms a state-of-the-art Answer Sentence Selection model. We also show that a multilingually-trained model competes with, and in some cases outperforms, its monolingual counterparts. Finally, we show that our system can even compete with strong baselines, even when fed with information from a variety of languages. Essentially, our system is able to answer a question in any language of our language set using information from many languages, making it the first Language-Agnostic GenQA system.