 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubimage Overlap Prediction: Task-Aligned Self-Supervised Pretraining For Semantic Segmentation In Remote Sensing Imagery
Jan 05, 2026Self-supervised learning (SSL) methods have become a dominant paradigm for creating general purpose models whose capabilities can be transferred to downstream supervised learning tasks. However, most such methods rely on vast amounts of pretraining data. This work introduces Subimage Overlap Prediction, a novel self-supervised pretraining task to aid semantic segmentation in remote sensing imagery that uses significantly lesser pretraining imagery. Given an image, a sub-image is extracted and the model is trained to produce a semantic mask of the location of the extracted sub-image within the original image. We demonstrate that pretraining with this task results in significantly faster convergence, and equal or better performance (measured via mIoU) on downstream segmentation. This gap in convergence and performance widens when labeled training data is reduced. We show this across multiple architecture types, and with multiple downstream datasets. We also show that our method matches or exceeds performance while requiring significantly lesser pretraining data relative to other SSL methods. Code and model weights are provided at \href{https://github.com/sharmalakshay93/subimage-overlap-prediction}{github.com/sharmalakshay93/subimage-overlap-prediction}.
Bridging the Skills Gap: Evaluating an AI-Assisted Provider Platform to Support Care Providers with Empathetic Delivery of Protocolized Therapy
Jan 08, 2024



Despite the high prevalence and burden of mental health conditions, there is a global shortage of mental health providers. Artificial Intelligence (AI) methods have been proposed as a way to address this shortage, by supporting providers with less extensive training as they deliver care. To this end, we developed the AI-Assisted Provider Platform (A2P2), a text-based virtual therapy interface that includes a response suggestion feature, which supports providers in delivering protocolized therapies empathetically. We studied providers with and without expertise in mental health treatment delivering a therapy session using the platform with (intervention) and without (control) AI-assistance features. Upon evaluation, the AI-assisted system significantly decreased response times by 29.34% (p=0.002), tripled empathic response accuracy (p=0.0001), and increased goal recommendation accuracy by 66.67% (p=0.001) across both user groups compared to the control. Both groups rated the system as having excellent usability.
Extracting and Inferring Personal Attributes from Dialogue
Sep 26, 2021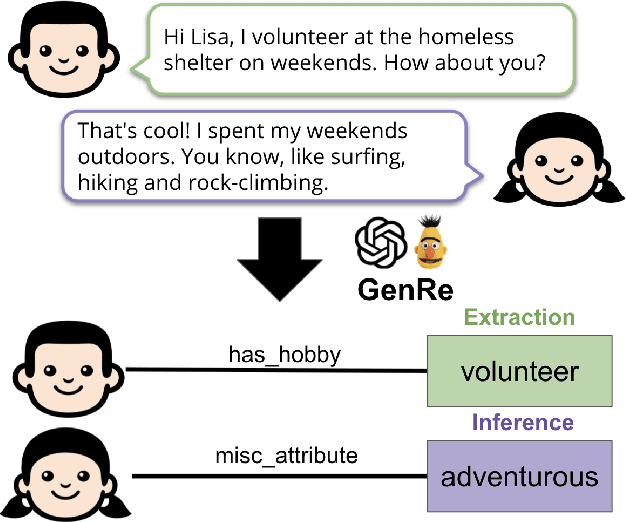


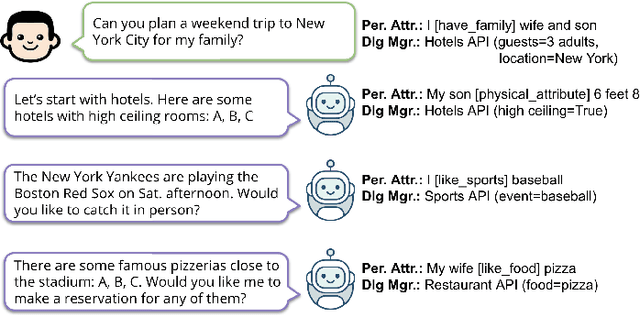
Personal attributes represent structured information about a person, such as their hobbies, pets, family, likes and dislikes. In this work, we introduce the tasks of extracting and inferring personal attributes from human-human dialogue. We first demonstrate the benefit of incorporating personal attributes in a social chit-chat dialogue model and task-oriented dialogue setting. Thus motivated, we propose the tasks of personal attribute extraction and inference, and then analyze the linguistic demands of these tasks. To meet these challenges, we introduce a simple and extensible model that combines an autoregressive language model utilizing constrained attribute generation with a discriminative reranker. Our model outperforms strong baselines on extracting personal attributes as well as inferring personal attributes that are not contained verbatim in utterances and instead requires commonsense reasoning and lexical inferences, which occur frequently in everyday conversation.
The SelectGen Challenge: Finding the Best Training Samples for Few-Shot Neural Text Generation
Aug 14, 2021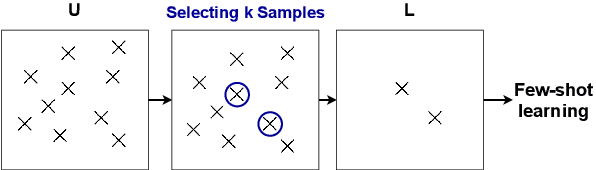
We propose a shared task on training instance selection for few-shot neural text generation. Large-scale pretrained language models have led to dramatic improvements in few-shot text generation. Nonetheless, almost all previous work simply applies random sampling to select the few-shot training instances. Little to no attention has been paid to the selection strategies and how they would affect model performance. The study of the selection strategy can help us to (1) make the most use of our annotation budget in downstream tasks and (2) better benchmark few-shot text generative models. We welcome submissions that present their selection strategies and the effects on the generation quality.
Jointly Improving Language Understanding and Generation with Quality-Weighted Weak Supervision of Automatic Labeling
Feb 06, 2021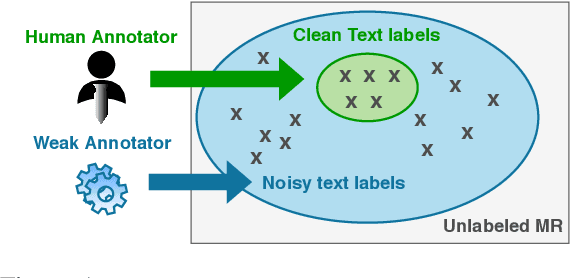
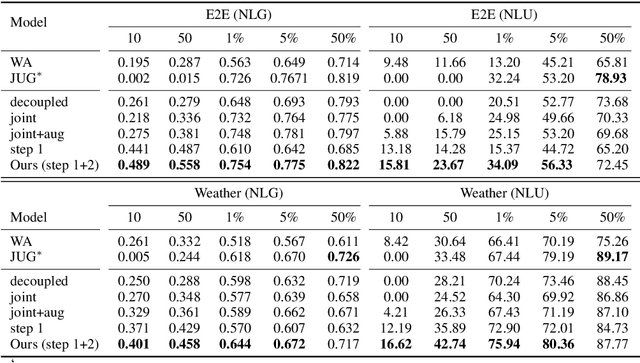
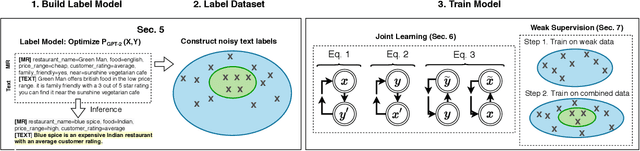
Neural natural language generation (NLG) and understanding (NLU) models are data-hungry and require massive amounts of annotated data to be competitive. Recent frameworks address this bottleneck with generative models that synthesize weak labels at scale, where a small amount of training labels are expert-curated and the rest of the data is automatically annotated. We follow that approach, by automatically constructing a large-scale weakly-labeled data with a fine-tuned GPT-2, and employ a semi-supervised framework to jointly train the NLG and NLU models. The proposed framework adapts the parameter updates to the models according to the estimated label-quality. On both the E2E and Weather benchmarks, we show that this weakly supervised training paradigm is an effective approach under low resource scenarios and outperforming benchmark systems on both datasets when 100% of training data is used.
DART: A Lightweight Quality-Suggestive Data-to-Text Annotation Tool
Oct 08, 2020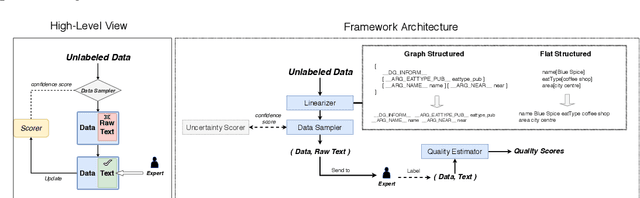

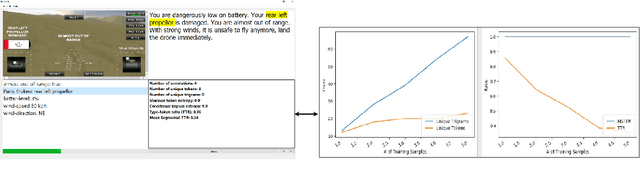
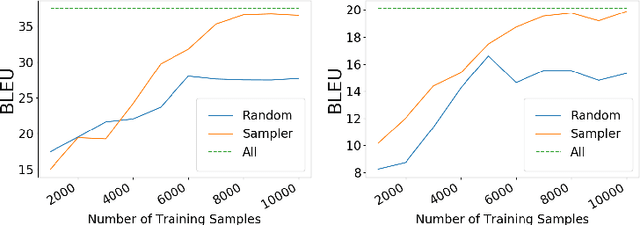
We present a lightweight annotation tool, the Data AnnotatoR Tool (DART), for the general task of labeling structured data with textual descriptions. The tool is implemented as an interactive application that reduces human efforts in annotating large quantities of structured data, e.g. in the format of a table or tree structure. By using a backend sequence-to-sequence model, our system iteratively analyzes the annotated labels in order to better sample unlabeled data. In a simulation experiment performed on annotating large quantities of structured data, DART has been shown to reduce the total number of annotations needed with active learning and automatically suggesting relevant labels.