 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient pre-training objectives for Transformers
Paper and Code



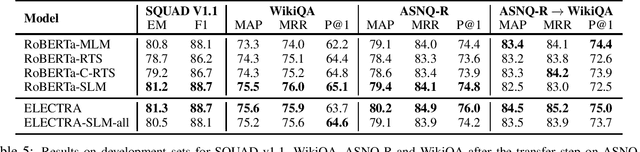
The Transformer architecture deeply changed the natural language processing, outperforming all previous state-of-the-art models. However, well-known Transformer models like BERT, RoBERTa, and GPT-2 require a huge compute budget to create a high quality contextualised representation. In this paper, we study several efficient pre-training objectives for Transformers-based models. By testing these objectives on different tasks, we determine which of the ELECTRA model's new features is the most relevant. We confirm that Transformers pre-training is improved when the input does not contain masked tokens and that the usage of the whole output to compute the loss reduces training time. Moreover, inspired by ELECTRA, we study a model composed of two blocks; a discriminator and a simple generator based on a statistical model with no impact on the computational performances. Besides, we prove that eliminating the MASK token and considering the whole output during the loss computation are essential choices to improve performance. Furthermore, we show that it is possible to efficiently train BERT-like models using a discriminative approach as in ELECTRA but without a complex generator, which is expensive. Finally, we show that ELECTRA benefits heavily from a state-of-the-art hyper-parameters search.