 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Labeling Refinement for Robust Representation Learning with Bootstrap Your Own Latent
Paper and Code
Apr 09, 2022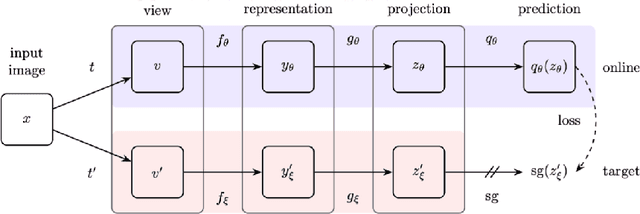
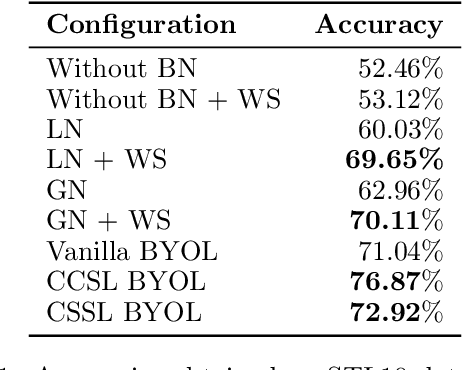
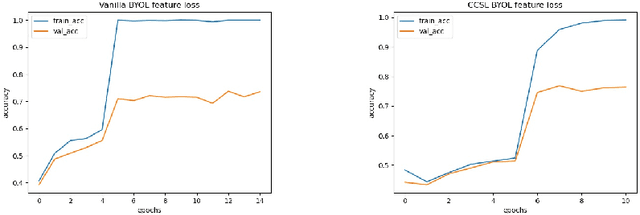
In this work, we have worked towards two major goals. Firstly, we have investigated the importance of Batch Normalisation (BN) layers in a non-contrastive representation learning framework called Bootstrap Your Own Latent (BYOL). We conducted several experiments to conclude that BN layers are not necessary for representation learning in BYOL. Moreover, BYOL only learns from the positive pairs of images but ignores other semantically similar images in the same input batch. For the second goal, we have introduced two new loss functions to determine the semantically similar pairs in the same input batch of images and reduce the distance between their representations. These loss functions are Cross-Cosine Similarity Loss (CCSL) and Cross-Sigmoid Similarity Loss (CSSL). Using the proposed loss functions, we are able to surpass the performance of Vanilla BYOL (71.04%) by training the BYOL framework using CCSL loss (76.87%) on the STL10 dataset. BYOL trained using CSSL loss performs comparably with Vanilla BYOL.