 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeRP: Self-Supervised Representation Learning Using Perturbed Point Clouds
Paper and Code
Sep 13, 2022
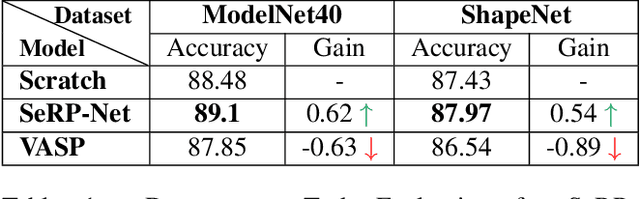
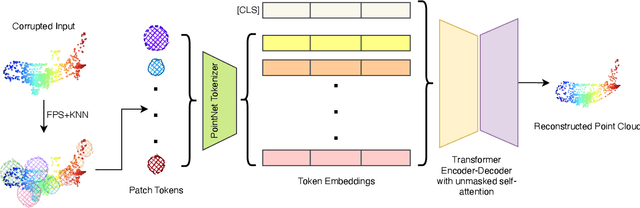
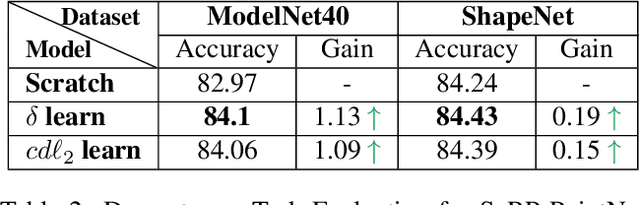
We present SeRP, a framework for Self-Supervised Learning of 3D point clouds. SeRP consists of encoder-decoder architecture that takes perturbed or corrupted point clouds as inputs and aims to reconstruct the original point cloud without corruption. The encoder learns the high-level latent representations of the points clouds in a low-dimensional subspace and recovers the original structure. In this work, we have used Transformers and PointNet-based Autoencoders. The proposed framework also addresses some of the limitations of Transformers-based Masked Autoencoders which are prone to leakage of location information and uneven information density. We trained our models on the complete ShapeNet dataset and evaluated them on ModelNet40 as a downstream classification task. We have shown that the pretrained models achieved 0.5-1% higher classification accuracies than the networks trained from scratch. Furthermore, we also proposed VASP: Vector-Quantized Autoencoder for Self-supervised Representation Learning for Point Clouds that employs Vector-Quantization for discrete representation learning for Transformer-based autoencoders.