 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device Spatial Attention based Sequence Learning Approach for Scene Text Script Identification
Dec 01, 2021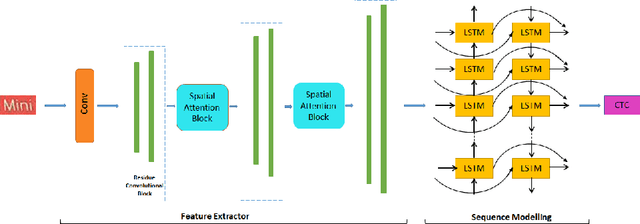
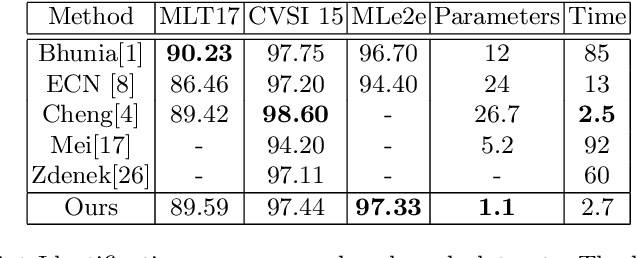
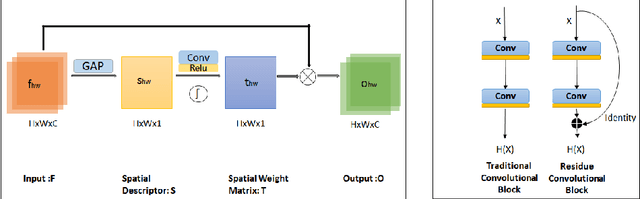
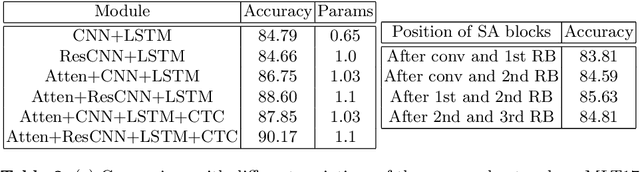
Automatic identification of script is an essential component of a multilingual OCR engine. In this paper, we present an efficient, lightweight, real-time and on-device spatial attention based CNN-LSTM network for scene text script identification, feasible for deployment on resource constrained mobile devices. Our network consists of a CNN, equipped with a spatial attention module which helps reduce the spatial distortions present in natural images. This allows the feature extractor to generate rich image representations while ignoring the deformities and thereby, enhancing the performance of this fine grained classification task. The network also employs residue convolutional blocks to build a deep network to focus on the discriminative features of a script. The CNN learns the text feature representation by identifying each character as belonging to a particular script and the long term spatial dependencies within the text are captured using the sequence learning capabilities of the LSTM layers. Combining the spatial attention mechanism with the residue convolutional blocks, we are able to enhance the performance of the baseline CNN to build an end-to-end trainable network for script identification. The experimental results on several standard benchmarks demonstrate the effectiveness of our method. The network achieves competitive accuracy with state-of-the-art methods and is superior in terms of network size, with a total of just 1.1 million parameters and inference time of 2.7 milliseconds.
A Simple Approach to Image Tilt Correction with Self-Attention MobileNet for Smartphones
Oct 31, 2021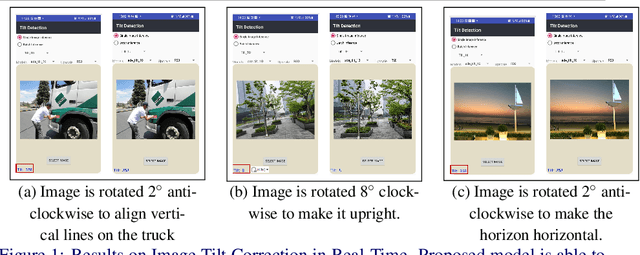
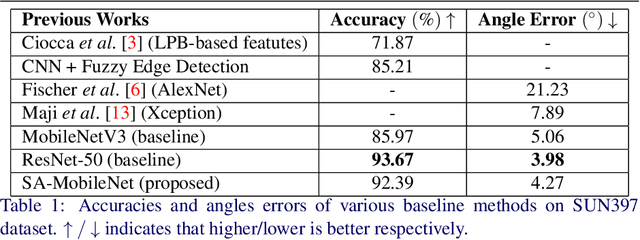
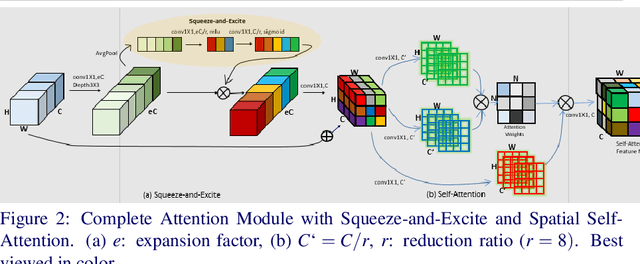
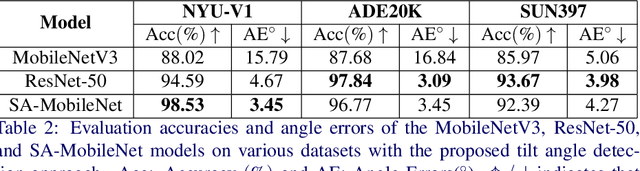
The main contributions of our work are two-fold. First, we present a Self-Attention MobileNet, called SA-MobileNet Network that can model long-range dependencies between the image features instead of processing the local region as done by standard convolutional kernels. SA-MobileNet contains self-attention modules integrated with the inverted bottleneck blocks of the MobileNetV3 model which results in modeling of both channel-wise attention and spatial attention of the image features and at the same time introduce a novel self-attention architecture for low-resource devices. Secondly, we propose a novel training pipeline for the task of image tilt detection. We treat this problem in a multi-label scenario where we predict multiple angles for a tilted input image in a narrow interval of range 1-2 degrees, depending on the dataset used. This process induces an implicit correlation between labels without any computational overhead of the second or higher-order methods in multi-label learning. With the combination of our novel approach and the architecture, we present state-of-the-art results on detecting the image tilt angle on mobile devices as compared to the MobileNetV3 model. Finally, we establish that SA-MobileNet is more accurate than MobileNetV3 on SUN397, NYU-V1, and ADE20K datasets by 6.42%, 10.51%, and 9.09% points respectively, and faster by at least 4 milliseconds on Snapdragon 750 Octa-core.
On-Device Content Moderation
Jul 25, 2021

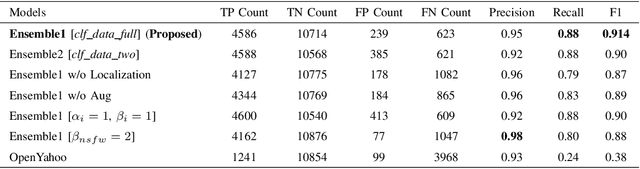
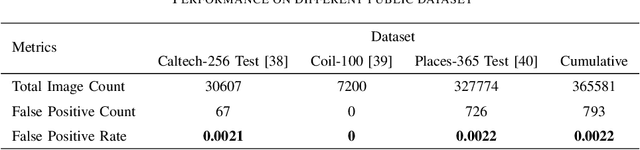
With the advent of internet, not safe for work(NSFW) content moderation is a major problem today. Since,smartphones are now part of daily life of billions of people,it becomes even more important to have a solution which coulddetect and suggest user about potential NSFW content present ontheir phone. In this paper we present a novel on-device solutionfor detecting NSFW images. In addition to conventional porno-graphic content moderation, we have also included semi-nudecontent moderation as it is still NSFW in a large demography.We have curated a dataset comprising of three major categories,namely nude, semi-nude and safe images. We have created anensemble of object detector and classifier for filtering of nudeand semi-nude contents. The solution provides unsafe body partannotations along with identification of semi-nude images. Weextensively tested our proposed solution on several public datasetand also on our custom dataset. The model achieves F1 scoreof 0.91 with 95% precision and 88% recall on our customNSFW16k dataset and 0.92 MAP on NPDI dataset. Moreover itachieves average 0.002 false positive rate on a collection of safeimage open datasets.
STRIDE : Scene Text Recognition In-Device
May 17, 2021
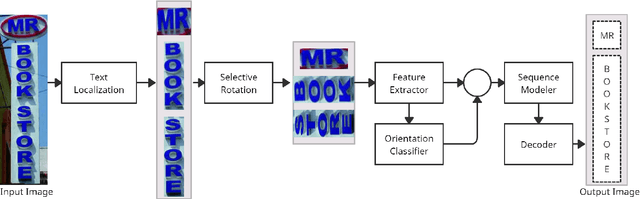
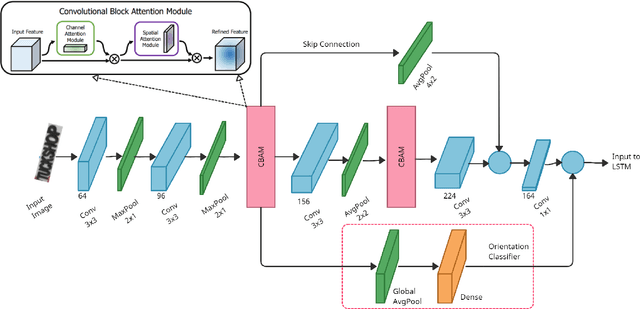

Optical Character Recognition (OCR) systems have been widely used in various applications for extracting semantic information from images. To give the user more control over their privacy, an on-device solution is needed. The current state-of-the-art models are too heavy and complex to be deployed on-device. We develop an efficient lightweight scene text recognition (STR) system, which has only 0.88M parameters and performs real-time text recognition. Attention modules tend to boost the accuracy of STR networks but are generally slow and not optimized for device inference. So, we propose the use of convolution attention modules to the text recognition networks, which aims to provide channel and spatial attention information to the LSTM module by adding very minimal computational cost. It boosts our word accuracy on ICDAR 13 dataset by almost 2\%. We also introduce a novel orientation classifier module, to support the simultaneous recognition of both horizontal and vertical text. The proposed model surpasses on-device metrics of inference time and memory footprint and achieves comparable accuracy when compared to the leading commercial and other open-source OCR engines. We deploy the system on-device with an inference speed of 2.44 ms per word on the Exynos 990 chipset device and achieve an accuracy of 88.4\% on ICDAR-13 dataset.
TeLCoS: OnDevice Text Localization with Clustering of Script
Apr 21, 2021
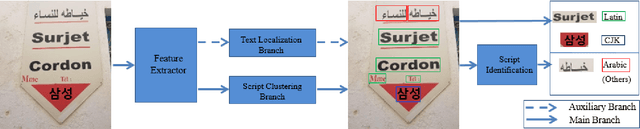

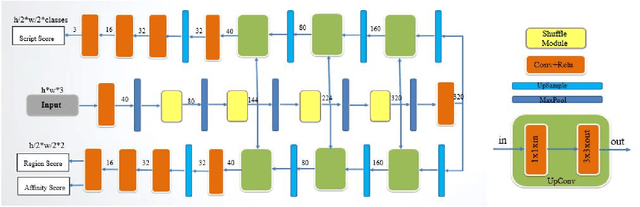
Recent research in the field of text localization in a resource constrained environment has made extensive use of deep neural networks. Scene text localization and recognition on low-memory mobile devices have a wide range of applications including content extraction, image categorization and keyword based image search. For text recognition of multi-lingual localized text, the OCR systems require prior knowledge of the script of each text instance. This leads to word script identification being an essential step for text recognition. Most existing methods treat text localization, script identification and text recognition as three separate tasks. This makes script identification an overhead in the recognition pipeline. To reduce this overhead, we propose TeLCoS: OnDevice Text Localization with Clustering of Script, a multi-task dual branch lightweight CNN network that performs real-time on device Text Localization and High-level Script Clustering simultaneously. The network drastically reduces the number of calls to a separate script identification module, by grouping and identifying some majorly used scripts through a single feed-forward pass over the localization network. We also introduce a novel structural similarity based channel pruning mechanism to build an efficient network with only 1.15M parameters. Experiments on benchmark datasets suggest that our method achieves state-of-the-art performance, with execution latency of 60 ms for the entire pipeline on the Exynos 990 chipset device.
ScreenSeg: On-Device Screenshot Layout Analysis
Apr 21, 2021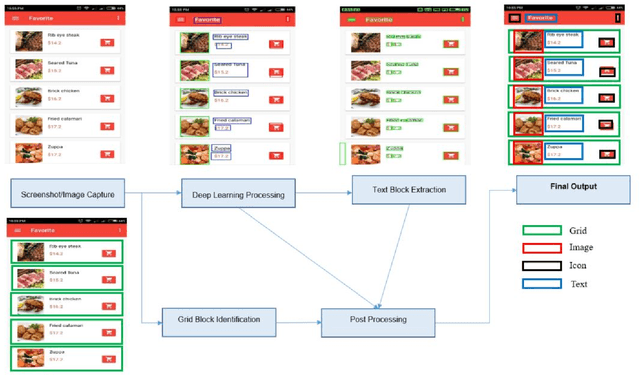
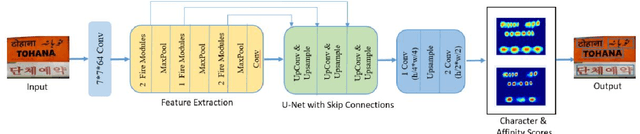
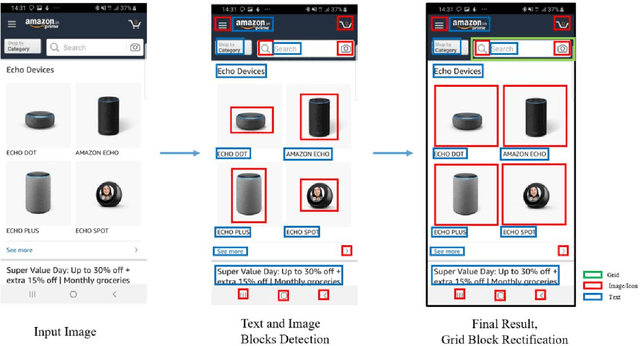
We propose a novel end-to-end solution that performs a Hierarchical Layout Analysis of screenshots and document images on resource constrained devices like mobilephones. Our approach segments entities like Grid, Image, Text and Icon blocks occurring in a screenshot. We provide an option for smart editing by auto highlighting these entities for saving or sharing. Further this multi-level layout analysis of screenshots has many use cases including content extraction, keyword-based image search, style transfer, etc. We have addressed the limitations of known baseline approaches, supported a wide variety of semantically complex screenshots, and developed an approach which is highly optimized for on-device deployment. In addition, we present a novel weighted NMS technique for filtering object proposals. We achieve an average precision of about 0.95 with a latency of around 200ms on Samsung Galaxy S10 Device for a screenshot of 1080p resolution. The solution pipeline is already commercialized in Samsung Device applications i.e. Samsung Capture, Smart Crop, My Filter in Camera Application, Bixby Touch.
On-Device Tag Generation for Unstructured Text
Dec 05, 2020



With the overwhelming transition to smart phones, storing important information in the form of unstructured text has become habitual to users of mobile devices. From grocery lists to drafts of emails and important speeches, users store a lot of data in the form of unstructured text (for eg: in the Notes application) on their devices, leading to cluttering of data. This not only prevents users from efficient navigation in the applications but also precludes them from perceiving the relations that could be present across data in those applications. This paper proposes a novel pipeline to generate a set of tags using world knowledge based on the keywords and concepts present in unstructured textual data. These tags can then be used to summarize, categorize or search for the desired information thus enhancing user experience by allowing them to have a holistic outlook of the kind of information stored in the form of unstructured text. In the proposed system, we use an on-device (mobile phone) efficient CNN model with pruned ConceptNet resource to achieve our goal. The architecture also presents a novel ranking algorithm to extract the top n tags from any given text.
On-Device Sentence Similarity for SMS Dataset
Dec 04, 2020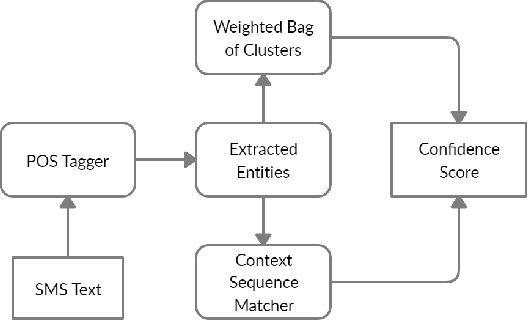

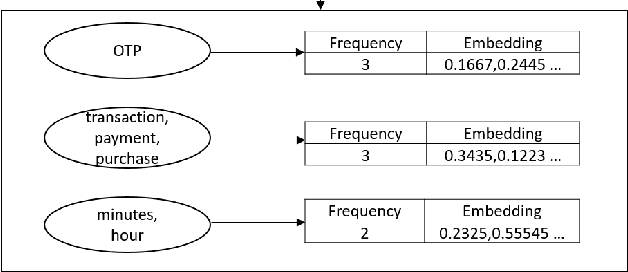
Determining the sentence similarity between Short Message Service (SMS) texts/sentences plays a significant role in mobile device industry. Gauging the similarity between SMS data is thus necessary for various applications like enhanced searching and navigation, clubbing together SMS of similar type when given a custom label or tag is provided by user irrespective of their sender etc. The problem faced with SMS data is its incomplete structure and grammatical inconsistencies. In this paper, we propose a unique pipeline for evaluating the text similarity between SMS texts. We use Part of Speech (POS) model for keyword extraction by taking advantage of the partial structure embedded in SMS texts and similarity comparisons are carried out using statistical methods. The proposed pipeline deals with major semantic variations across SMS data as well as makes it effective for its application on-device (mobile phone). To showcase the capabilities of our work, our pipeline has been designed with an inclination towards one of the possible applications of SMS text similarity discussed in one of the following sections but nonetheless guarantees scalability for other applications as well.
On-Device Text Image Super Resolution
Nov 20, 2020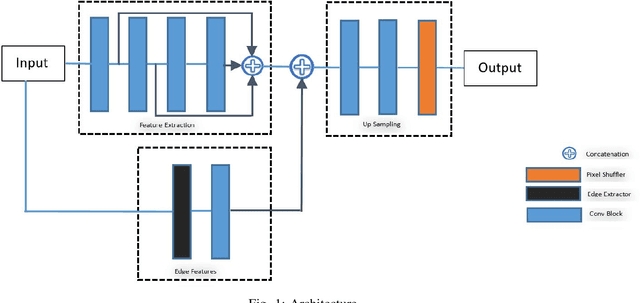

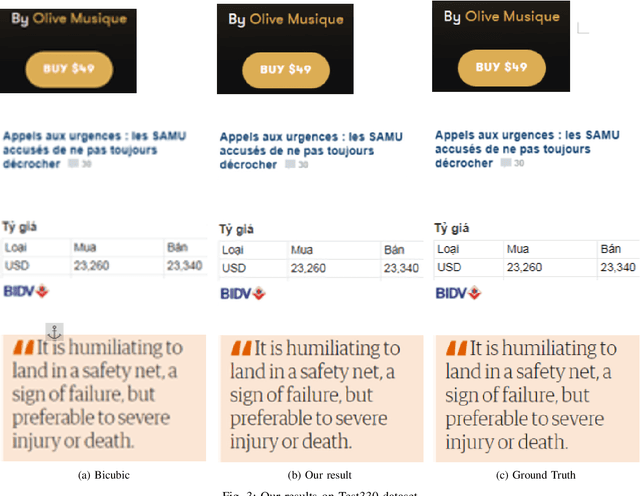

Recent research on super-resolution (SR) has witnessed major developments with the advancements of deep convolutional neural networks. There is a need for information extraction from scenic text images or even document images on device, most of which are low-resolution (LR) images. Therefore, SR becomes an essential pre-processing step as Bicubic Upsampling, which is conventionally present in smartphones, performs poorly on LR images. To give the user more control over his privacy, and to reduce the carbon footprint by reducing the overhead of cloud computing and hours of GPU usage, executing SR models on the edge is a necessity in the recent times. There are various challenges in running and optimizing a model on resource-constrained platforms like smartphones. In this paper, we present a novel deep neural network that reconstructs sharper character edges and thus boosts OCR confidence. The proposed architecture not only achieves significant improvement in PSNR over bicubic upsampling on various benchmark datasets but also runs with an average inference time of 11.7 ms per image. We have outperformed state-of-the-art on the Text330 dataset. We also achieve an OCR accuracy of 75.89% on the ICDAR 2015 TextSR dataset, where ground truth has an accuracy of 78.10%.
On-Device Language Identification of Text in Images using Diacritic Characters
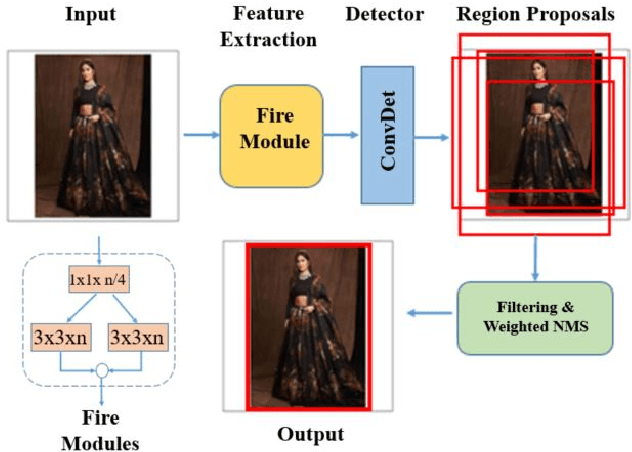
Nov 10, 2020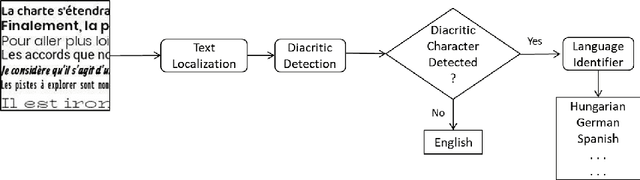


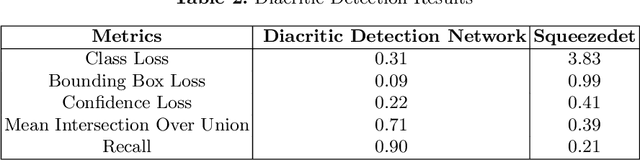
Diacritic characters can be considered as a unique set of characters providing us with adequate and significant clue in identifying a given language with considerably high accuracy. Diacritics, though associated with phonetics often serve as a distinguishing feature for many languages especially the ones with a Latin script. In this proposed work, we aim to identify language of text in images using the presence of diacritic characters in order to improve Optical Character Recognition (OCR) performance in any given automated environment. We showcase our work across 13 Latin languages encompassing 85 diacritic characters. We use an architecture similar to Squeezedet for object detection of diacritic characters followed by a shallow network to finally identify the language. OCR systems when accompanied with identified language parameter tends to produce better results than sole deployment of OCR systems. The discussed work apart from guaranteeing an improvement in OCR results also takes on-device (mobile phone) constraints into consideration in terms of model size and inference time.