 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeswitched Sentence Creation using Dependency Parsing
Dec 05, 2020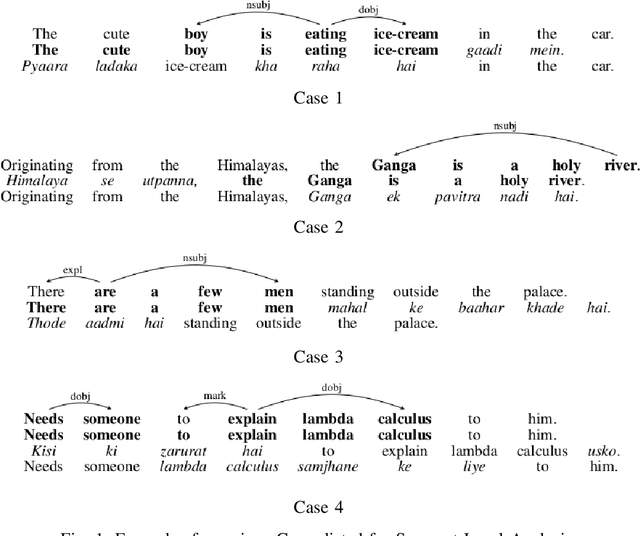
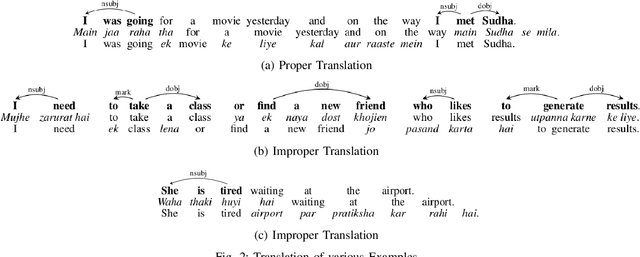

Codeswitching has become one of the most common occurrences across multilingual speakers of the world, especially in countries like India which encompasses around 23 official languages with the number of bilingual speakers being around 300 million. The scarcity of Codeswitched data becomes a bottleneck in the exploration of this domain with respect to various Natural Language Processing (NLP) tasks. We thus present a novel algorithm which harnesses the syntactic structure of English grammar to develop grammatically sensible Codeswitched versions of English-Hindi, English-Marathi and English-Kannada data. Apart from maintaining the grammatical sanity to a great extent, our methodology also guarantees abundant generation of data from a minuscule snapshot of given data. We use multiple datasets to showcase the capabilities of our algorithm while at the same time we assess the quality of generated Codeswitched data using some qualitative metrics along with providing baseline results for couple of NLP tasks.
On-Device Tag Generation for Unstructured Text
Dec 05, 2020



With the overwhelming transition to smart phones, storing important information in the form of unstructured text has become habitual to users of mobile devices. From grocery lists to drafts of emails and important speeches, users store a lot of data in the form of unstructured text (for eg: in the Notes application) on their devices, leading to cluttering of data. This not only prevents users from efficient navigation in the applications but also precludes them from perceiving the relations that could be present across data in those applications. This paper proposes a novel pipeline to generate a set of tags using world knowledge based on the keywords and concepts present in unstructured textual data. These tags can then be used to summarize, categorize or search for the desired information thus enhancing user experience by allowing them to have a holistic outlook of the kind of information stored in the form of unstructured text. In the proposed system, we use an on-device (mobile phone) efficient CNN model with pruned ConceptNet resource to achieve our goal. The architecture also presents a novel ranking algorithm to extract the top n tags from any given text.
On-Device Sentence Similarity for SMS Dataset
Dec 04, 2020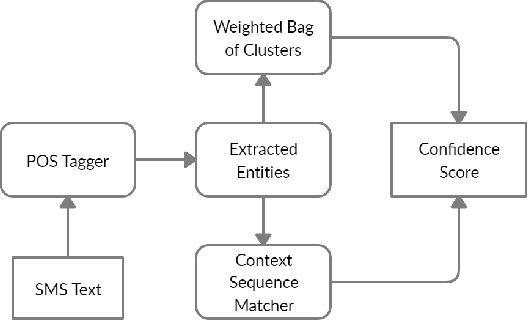

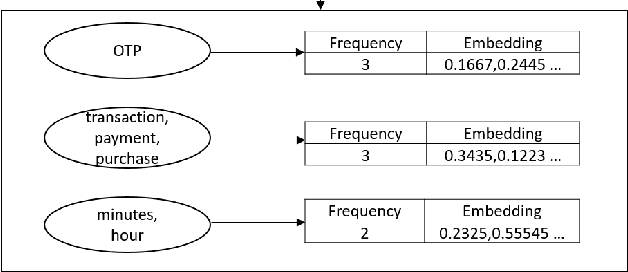
Determining the sentence similarity between Short Message Service (SMS) texts/sentences plays a significant role in mobile device industry. Gauging the similarity between SMS data is thus necessary for various applications like enhanced searching and navigation, clubbing together SMS of similar type when given a custom label or tag is provided by user irrespective of their sender etc. The problem faced with SMS data is its incomplete structure and grammatical inconsistencies. In this paper, we propose a unique pipeline for evaluating the text similarity between SMS texts. We use Part of Speech (POS) model for keyword extraction by taking advantage of the partial structure embedded in SMS texts and similarity comparisons are carried out using statistical methods. The proposed pipeline deals with major semantic variations across SMS data as well as makes it effective for its application on-device (mobile phone). To showcase the capabilities of our work, our pipeline has been designed with an inclination towards one of the possible applications of SMS text similarity discussed in one of the following sections but nonetheless guarantees scalability for other applications as well.
On-Device Text Image Super Resolution
Nov 20, 2020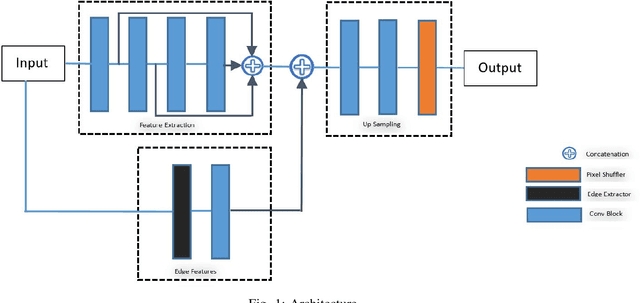

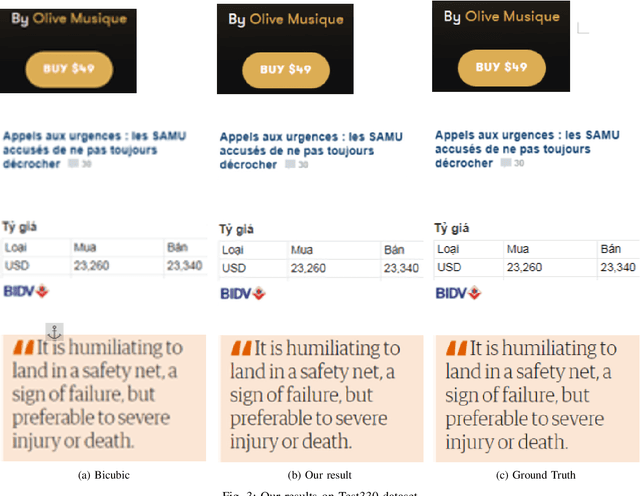

Recent research on super-resolution (SR) has witnessed major developments with the advancements of deep convolutional neural networks. There is a need for information extraction from scenic text images or even document images on device, most of which are low-resolution (LR) images. Therefore, SR becomes an essential pre-processing step as Bicubic Upsampling, which is conventionally present in smartphones, performs poorly on LR images. To give the user more control over his privacy, and to reduce the carbon footprint by reducing the overhead of cloud computing and hours of GPU usage, executing SR models on the edge is a necessity in the recent times. There are various challenges in running and optimizing a model on resource-constrained platforms like smartphones. In this paper, we present a novel deep neural network that reconstructs sharper character edges and thus boosts OCR confidence. The proposed architecture not only achieves significant improvement in PSNR over bicubic upsampling on various benchmark datasets but also runs with an average inference time of 11.7 ms per image. We have outperformed state-of-the-art on the Text330 dataset. We also achieve an OCR accuracy of 75.89% on the ICDAR 2015 TextSR dataset, where ground truth has an accuracy of 78.10%.
On-Device Language Identification of Text in Images using Diacritic Characters
Nov 10, 2020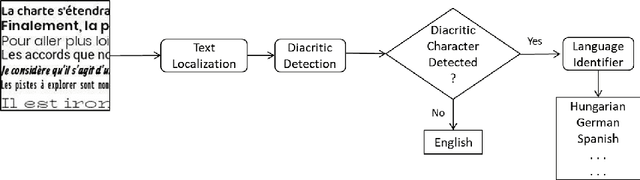


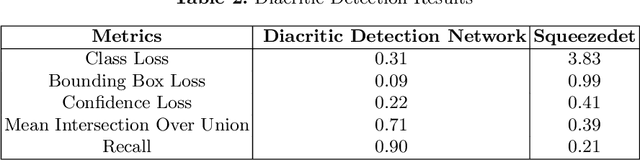
Diacritic characters can be considered as a unique set of characters providing us with adequate and significant clue in identifying a given language with considerably high accuracy. Diacritics, though associated with phonetics often serve as a distinguishing feature for many languages especially the ones with a Latin script. In this proposed work, we aim to identify language of text in images using the presence of diacritic characters in order to improve Optical Character Recognition (OCR) performance in any given automated environment. We showcase our work across 13 Latin languages encompassing 85 diacritic characters. We use an architecture similar to Squeezedet for object detection of diacritic characters followed by a shallow network to finally identify the language. OCR systems when accompanied with identified language parameter tends to produce better results than sole deployment of OCR systems. The discussed work apart from guaranteeing an improvement in OCR results also takes on-device (mobile phone) constraints into consideration in terms of model size and inference time.
On-device Filtering of Social Media Images for Efficient Storage
Apr 06, 2020
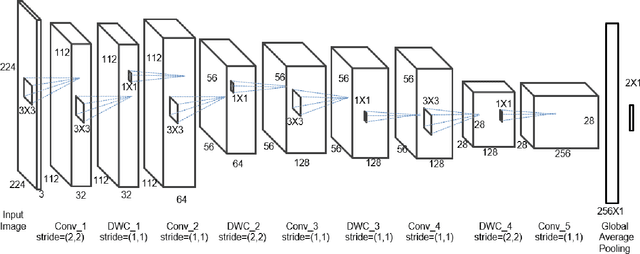


Artificially crafted images such as memes, seasonal greetings, etc are flooding the social media platforms today. These eventually start occupying a lot of internal memory of smartphones and it gets cumbersome for the user to go through hundreds of images and delete these synthetic images. To address this, we propose a novel method based on Convolutional Neural Networks (CNNs) for the on-device filtering of social media images by classifying these synthetic images and allowing the user to delete them in one go. The custom model uses depthwise separable convolution layers to achieve low inference time on smartphones. We have done an extensive evaluation of our model on various camera image datasets to cover most aspects of images captured by a camera. Various sorts of synthetic social media images have also been tested. The proposed solution achieves an accuracy of 98.25% on the Places-365 dataset and 95.81% on the Synthetic image dataset that we have prepared containing 30K instances.
On-Device Information Extraction from SMS using Hybrid Hierarchical Classification
Feb 03, 2020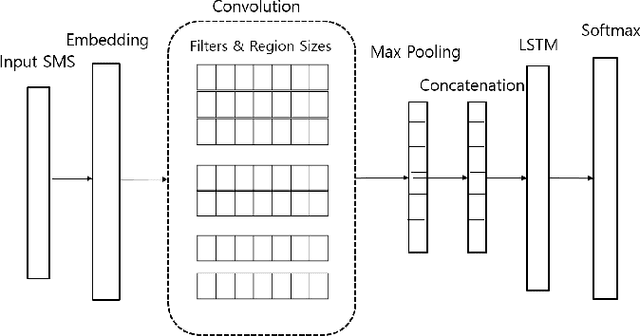
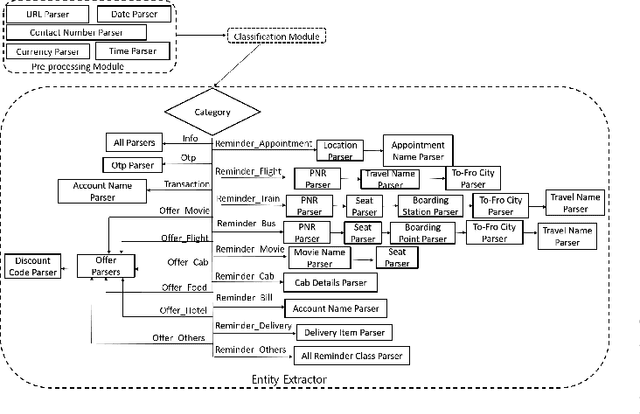

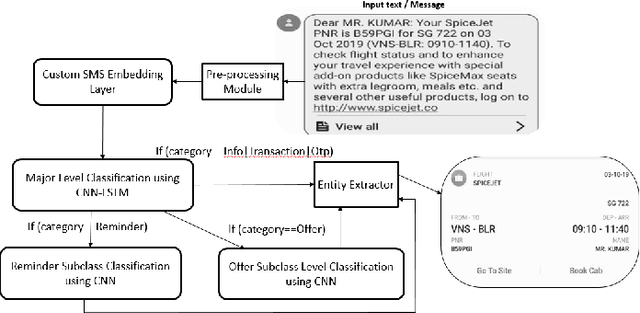
Cluttering of SMS inbox is one of the serious problems that users today face in the digital world where every online login, transaction, along with promotions generate multiple SMS. This problem not only prevents users from searching and navigating messages efficiently but often results in users missing out the relevant information associated with the corresponding SMS like offer codes, payment reminders etc. In this paper, we propose a unique architecture to organize and extract the appropriate information from SMS and further display it in an intuitive template. In the proposed architecture, we use a Hybrid Hierarchical Long Short Term Memory (LSTM)-Convolutional Neural Network (CNN) to categorize SMS into multiple classes followed by a set of entity parsers used to extract the relevant information from the classified message. The architecture using its preprocessing techniques not only takes into account the enormous variations observed in SMS data but also makes it efficient for its on-device (mobile phone) functionalities in terms of inference timing and size.
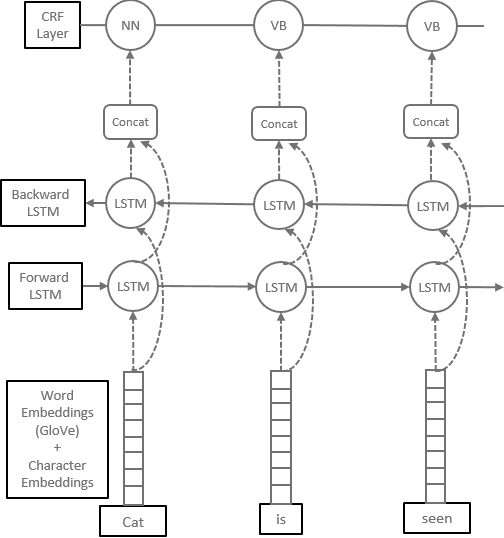
An Efficient Architecture for Predicting the Case of Characters using Sequence Models
Jan 30, 2020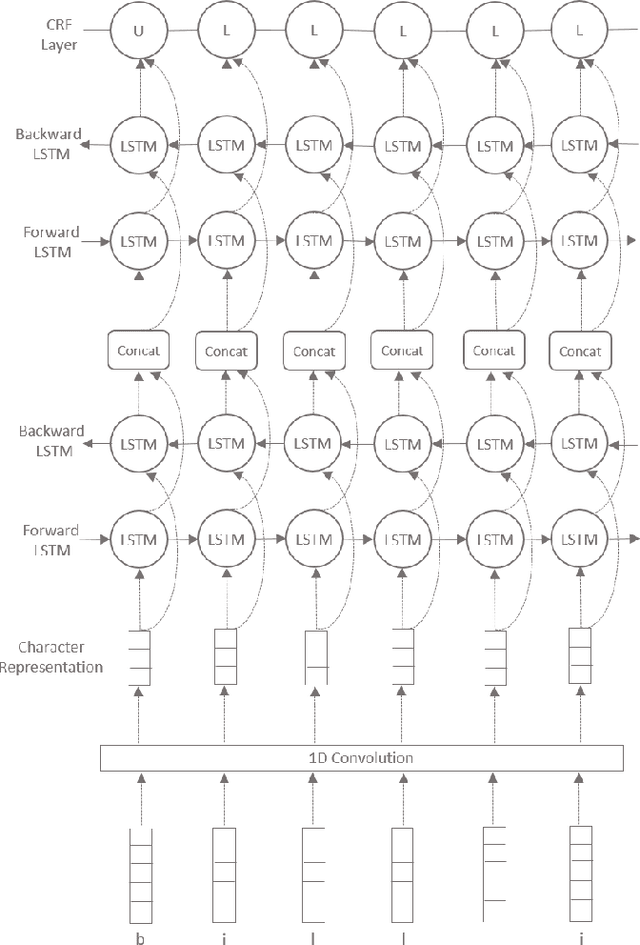

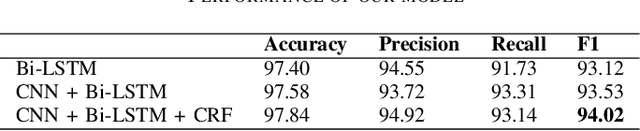
The dearth of clean textual data often acts as a bottleneck in several natural language processing applications. The data available often lacks proper case (uppercase or lowercase) information. This often comes up when text is obtained from social media, messaging applications and other online platforms. This paper attempts to solve this problem by restoring the correct case of characters, commonly known as Truecasing. Doing so improves the accuracy of several processing tasks further down in the NLP pipeline. Our proposed architecture uses a combination of convolutional neural networks (CNN), bi-directional long short-term memory networks (LSTM) and conditional random fields (CRF), which work at a character level without any explicit feature engineering. In this study we compare our approach to previous statistical and deep learning based approaches. Our method shows an increment of 0.83 in F1 score over the current state of the art. Since truecasing acts as a preprocessing step in several applications, every increment in the F1 score leads to a significant improvement in the language processing tasks.