 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device Sentence Similarity for SMS Dataset
Paper and Code
Dec 04, 2020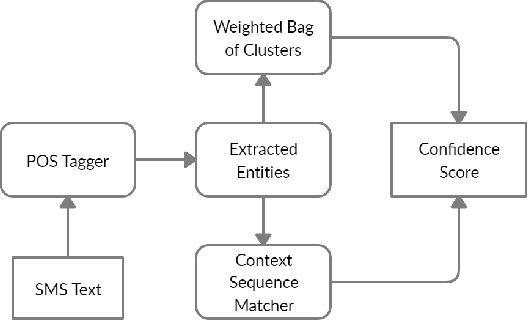

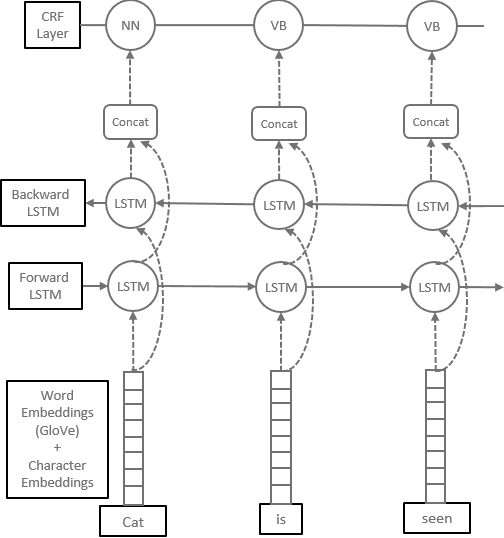
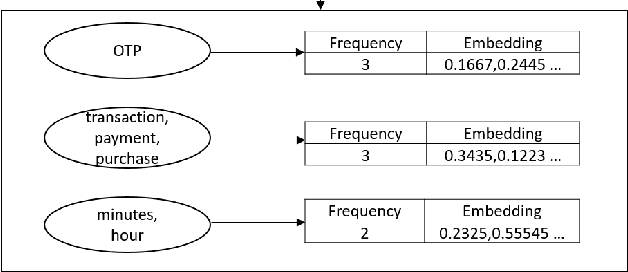
Determining the sentence similarity between Short Message Service (SMS) texts/sentences plays a significant role in mobile device industry. Gauging the similarity between SMS data is thus necessary for various applications like enhanced searching and navigation, clubbing together SMS of similar type when given a custom label or tag is provided by user irrespective of their sender etc. The problem faced with SMS data is its incomplete structure and grammatical inconsistencies. In this paper, we propose a unique pipeline for evaluating the text similarity between SMS texts. We use Part of Speech (POS) model for keyword extraction by taking advantage of the partial structure embedded in SMS texts and similarity comparisons are carried out using statistical methods. The proposed pipeline deals with major semantic variations across SMS data as well as makes it effective for its application on-device (mobile phone). To showcase the capabilities of our work, our pipeline has been designed with an inclination towards one of the possible applications of SMS text similarity discussed in one of the following sections but nonetheless guarantees scalability for other applications as well.