 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthCharge: An Electric Vehicle Routing Instance Generator with Feasibility Screening to Enable Learning-Based Optimization and Benchmarking
Mar 03, 2026The electric vehicle routing problem with time windows (EVRPTW) extends the classical VRPTW by introducing battery capacity constraints and charging station decisions. Existing benchmark datasets are often static and lack verifiable feasibility, which restricts reproducible evaluation of learning-based routing models. We introduce SynthCharge, a parametric generator that produces diverse, feasibility-screened EVRPTW instances across varying spatiotemporal configurations and scalable customer counts. While SynthCharge can currently generate large-scale instances of up to 500 customers, we focus our experiments on sizes ranging from 5 to 100 customers. Unlike static benchmark suites, SynthCharge integrates instance geometry with adaptive energy capacity scaling and range-aware charging station placement. To guarantee structural validity, the generator systematically filters out unsolvable instances through a fast feasibility screening process. Ultimately, SynthCharge provides the dynamic benchmarking infrastructure needed to systematically evaluate the robustness of emerging neural routing and data-driven approaches.
Geometry-Free Conditional Diffusion Modeling for Solving the Inverse Electrocardiography Problem
Jan 26, 2026This paper proposes a data-driven model for solving the inverse problem of electrocardiography, the mathematical problem that forms the basis of electrocardiographic imaging (ECGI). We present a conditional diffusion framework that learns a probabilistic mapping from noisy body surface signals to heart surface electric potentials. The proposed approach leverages the generative nature of diffusion models to capture the non-unique and underdetermined nature of the ECGI inverse problem, enabling probabilistic sampling of multiple reconstructions rather than a single deterministic estimate. Unlike traditional methods, the proposed framework is geometry-free and purely data-driven, alleviating the need for patient-specific mesh construction. We evaluate the method on a real ECGI dataset and compare it against strong deterministic baselines, including a convolutional neural network, long short-term memory network, and transformer-based model. The results demonstrate that the proposed diffusion approach achieves improved reconstruction accuracy, highlighting the potential of diffusion models as a robust tool for noninvasive cardiac electrophysiology imaging.
A Curriculum-Based Deep Reinforcement Learning Framework for the Electric Vehicle Routing Problem
Jan 21, 2026The electric vehicle routing problem with time windows (EVRPTW) is a complex optimization problem in sustainable logistics, where routing decisions must minimize total travel distance, fleet size, and battery usage while satisfying strict customer time constraints. Although deep reinforcement learning (DRL) has shown great potential as an alternative to classical heuristics and exact solvers, existing DRL models often struggle to maintain training stability-failing to converge or generalize when constraints are dense. In this study, we propose a curriculum-based deep reinforcement learning (CB-DRL) framework designed to resolve this instability. The framework utilizes a structured three-phase curriculum that gradually increases problem complexity: the agent first learns distance and fleet optimization (Phase A), then battery management (Phase B), and finally the full EVRPTW (Phase C). To ensure stable learning across phases, the framework employs a modified proximal policy optimization algorithm with phase-specific hyperparameters, value and advantage clipping, and adaptive learning-rate scheduling. The policy network is built upon a heterogeneous graph attention encoder enhanced by global-local attention and feature-wise linear modulation. This specialized architecture explicitly captures the distinct properties of depots, customers, and charging stations. Trained exclusively on small instances with N=10 customers, the model demonstrates robust generalization to unseen instances ranging from N=5 to N=100, significantly outperforming standard baselines on medium-scale problems. Experimental results confirm that this curriculum-guided approach achieves high feasibility rates and competitive solution quality on out-of-distribution instances where standard DRL baselines fail, effectively bridging the gap between neural speed and operational reliability.
Fourier Learning Machines: Nonharmonic Fourier-Based Neural Networks for Scientific Machine Learning
Sep 10, 2025



We introduce the Fourier Learning Machine (FLM), a neural network (NN) architecture designed to represent a multidimensional nonharmonic Fourier series. The FLM uses a simple feedforward structure with cosine activation functions to learn the frequencies, amplitudes, and phase shifts of the series as trainable parameters. This design allows the model to create a problem-specific spectral basis adaptable to both periodic and nonperiodic functions. Unlike previous Fourier-inspired NN models, the FLM is the first architecture able to represent a complete, separable Fourier basis in multiple dimensions using a standard Multilayer Perceptron-like architecture. A one-to-one correspondence between the Fourier coefficients and amplitudes and phase-shifts is demonstrated, allowing for the translation between a full, separable basis form and the cosine phase--shifted one. Additionally, we evaluate the performance of FLMs on several scientific computing problems, including benchmark Partial Differential Equations (PDEs) and a family of Optimal Control Problems (OCPs). Computational experiments show that the performance of FLMs is comparable, and often superior, to that of established architectures like SIREN and vanilla feedforward NNs.
Semantic Role Labeling of NomBank Partitives
Dec 18, 2024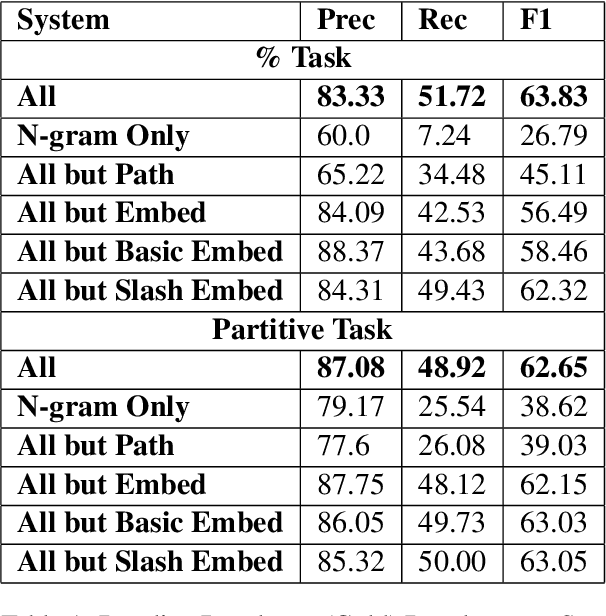
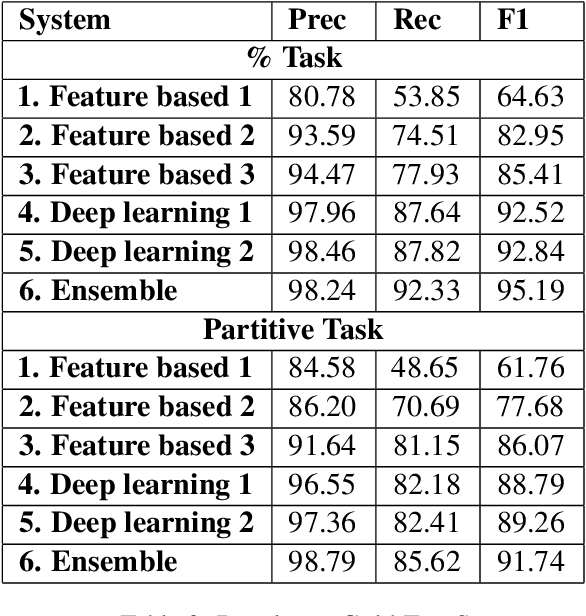
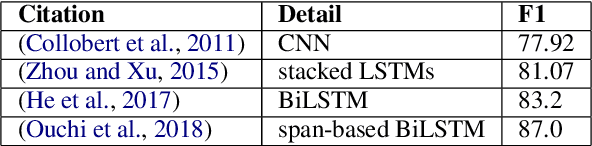
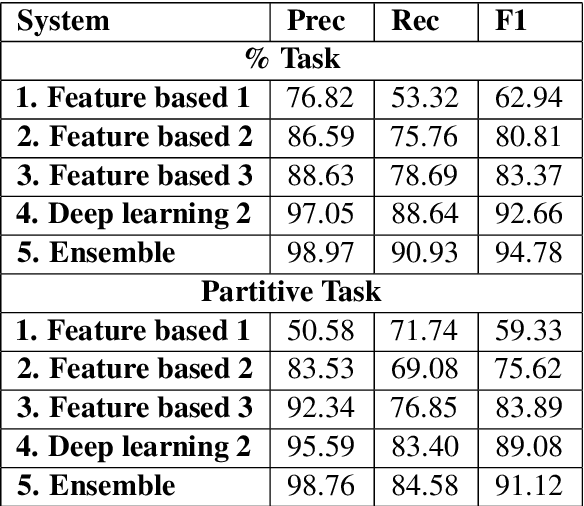
This article is about Semantic Role Labeling for English partitive nouns (5%/REL of the price/ARG1; The price/ARG1 rose 5 percent/REL) in the NomBank annotated corpus. Several systems are described using traditional and transformer-based machine learning, as well as ensembling. Our highest scoring system achieves an F1 of 91.74% using "gold" parses from the Penn Treebank and 91.12% when using the Berkeley Neural parser. This research includes both classroom and experimental settings for system development.
The Role of Handling Attributive Nouns in Improving Chinese-To-English Machine Translation
Dec 18, 2024Translating between languages with drastically different grammatical conventions poses challenges, not just for human interpreters but also for machine translation systems. In this work, we specifically target the translation challenges posed by attributive nouns in Chinese, which frequently cause ambiguities in English translation. By manually inserting the omitted particle X ('DE'). In news article titles from the Penn Chinese Discourse Treebank, we developed a targeted dataset to fine-tune Hugging Face Chinese to English translation models, specifically improving how this critical function word is handled. This focused approach not only complements the broader strategies suggested by previous studies but also offers a practical enhancement by specifically addressing a common error type in Chinese-English translation.
Classification of US Supreme Court Cases using BERT-Based Techniques
Apr 17, 2023
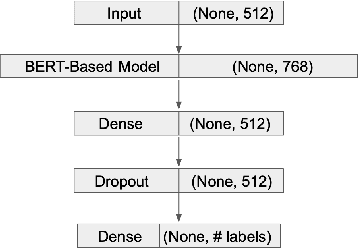
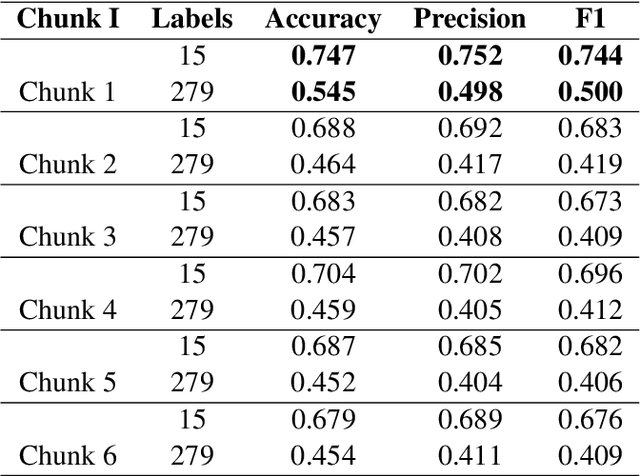
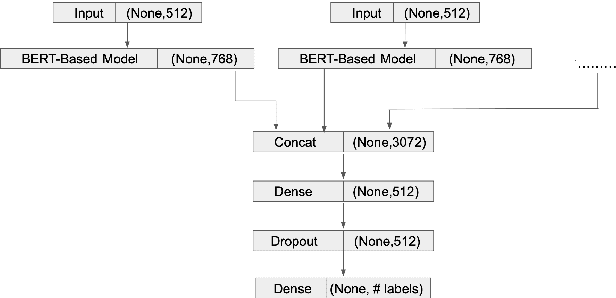
Models based on bidirectional encoder representations from transformers (BERT) produce state of the art (SOTA) results on many natural language processing (NLP) tasks such as named entity recognition (NER), part-of-speech (POS) tagging etc. An interesting phenomenon occurs when classifying long documents such as those from the US supreme court where BERT-based models can be considered difficult to use on a first-pass or out-of-the-box basis. In this paper, we experiment with several BERT-based classification techniques for US supreme court decisions or supreme court database (SCDB) and compare them with the previous SOTA results. We then compare our results specifically with SOTA models for long documents. We compare our results for two classification tasks: (1) a broad classification task with 15 categories and (2) a fine-grained classification task with 279 categories. Our best result produces an accuracy of 80\% on the 15 broad categories and 60\% on the fine-grained 279 categories which marks an improvement of 8\% and 28\% respectively from previously reported SOTA results.
Comlex Syntax: Building a Computational Lexicon
Nov 10, 1994
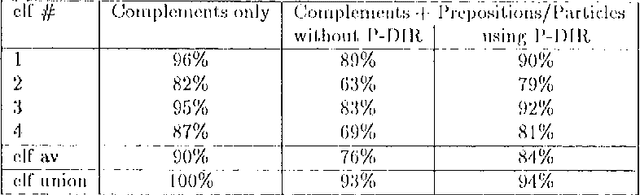
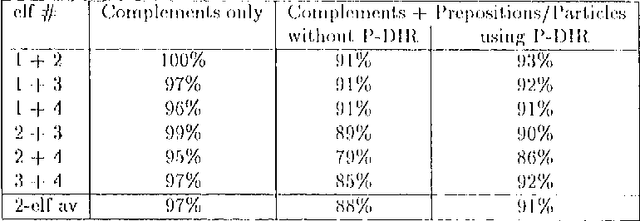
We describe the design of Comlex Syntax, a computational lexicon providing detailed syntactic information for approximately 38,000 English headwords. We consider the types of errors which arise in creating such a lexicon, and how such errors can be measured and controlled.