 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Neural Networks and Log-linear Models to Improve Relation Extraction
Nov 18, 2015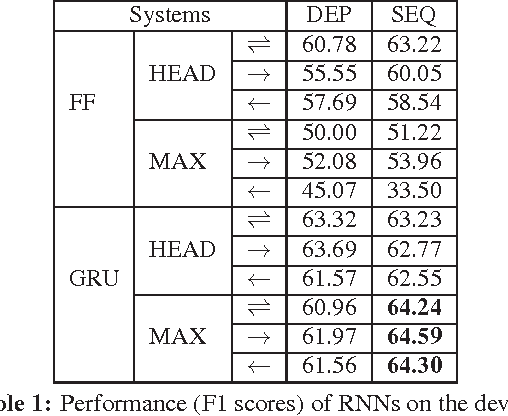
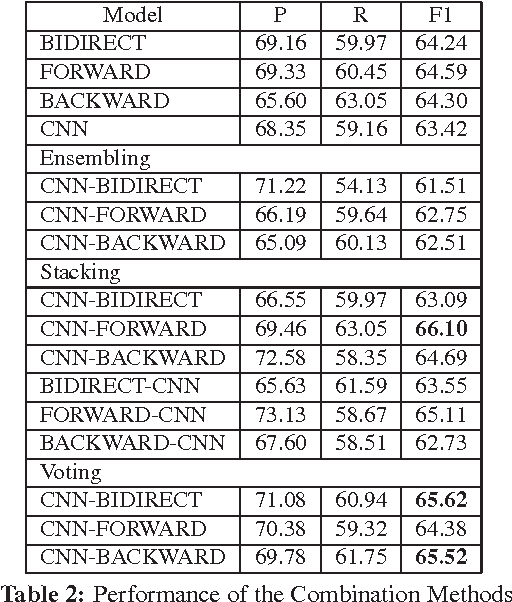
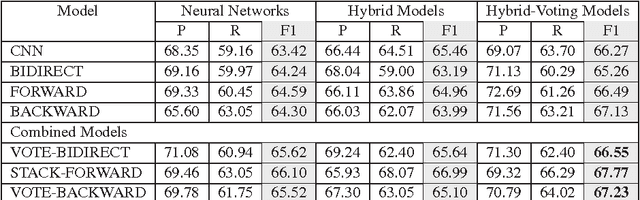
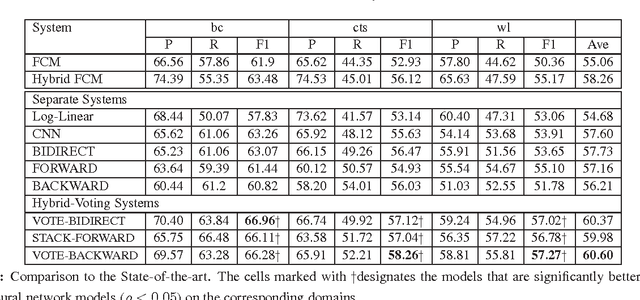
The last decade has witnessed the success of the traditional feature-based method on exploiting the discrete structures such as words or lexical patterns to extract relations from text. Recently, convolutional and recurrent neural networks has provided very effective mechanisms to capture the hidden structures within sentences via continuous representations, thereby significantly advancing the performance of relation extraction. The advantage of convolutional neural networks is their capacity to generalize the consecutive k-grams in the sentences while recurrent neural networks are effective to encode long ranges of sentence context. This paper proposes to combine the traditional feature-based method, the convolutional and recurrent neural networks to simultaneously benefit from their advantages. Our systematic evaluation of different network architectures and combination methods demonstrates the effectiveness of this approach and results in the state-of-the-art performance on the ACE 2005 and SemEval dataset.
Jointly Embedding Relations and Mentions for Knowledge Population
Jul 07, 2015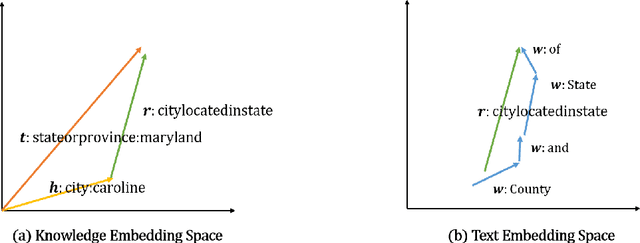
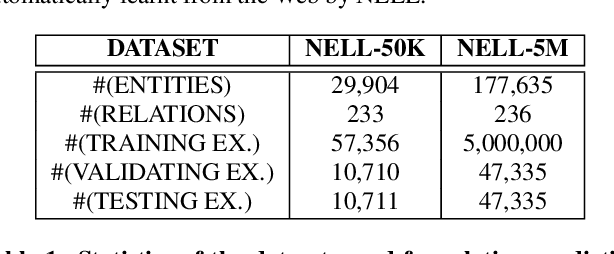
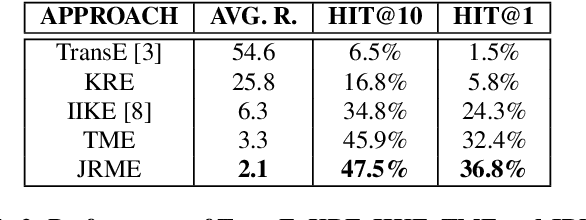

This paper contributes a joint embedding model for predicting relations between a pair of entities in the scenario of relation inference. It differs from most stand-alone approaches which separately operate on either knowledge bases or free texts. The proposed model simultaneously learns low-dimensional vector representations for both triplets in knowledge repositories and the mentions of relations in free texts, so that we can leverage the evidence both resources to make more accurate predictions. We use NELL to evaluate the performance of our approach, compared with cutting-edge methods. Results of extensive experiments show that our model achieves significant improvement on relation extraction.
Probabilistic Belief Embedding for Knowledge Base Completion
May 22, 2015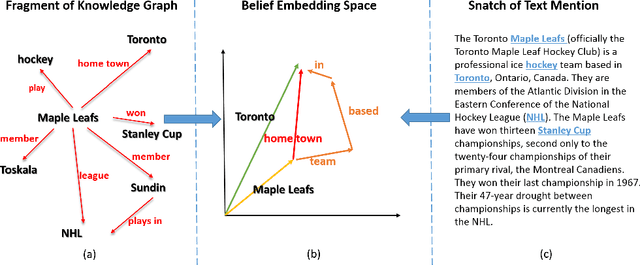
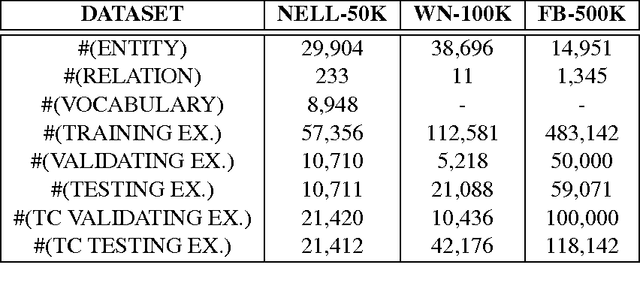
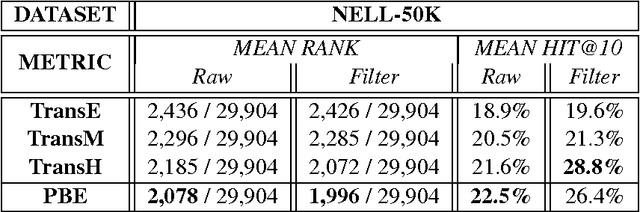
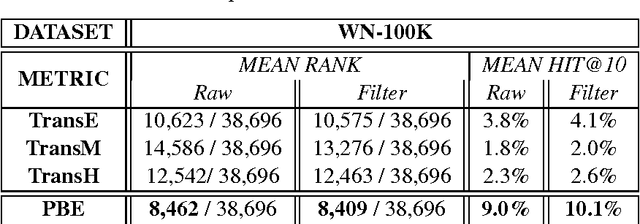
This paper contributes a novel embedding model which measures the probability of each belief $\langle h,r,t,m\rangle$ in a large-scale knowledge repository via simultaneously learning distributed representations for entities ($h$ and $t$), relations ($r$), and the words in relation mentions ($m$). It facilitates knowledge completion by means of simple vector operations to discover new beliefs. Given an imperfect belief, we can not only infer the missing entities, predict the unknown relations, but also tell the plausibility of the belief, just leveraging the learnt embeddings of remaining evidences. To demonstrate the scalability and the effectiveness of our model, we conduct experiments on several large-scale repositories which contain millions of beliefs from WordNet, Freebase and NELL, and compare it with other cutting-edge approaches via competing the performances assessed by the tasks of entity inference, relation prediction and triplet classification with respective metrics. Extensive experimental results show that the proposed model outperforms the state-of-the-arts with significant improvements.
Large Margin Nearest Neighbor Embedding for Knowledge Representation
Apr 07, 2015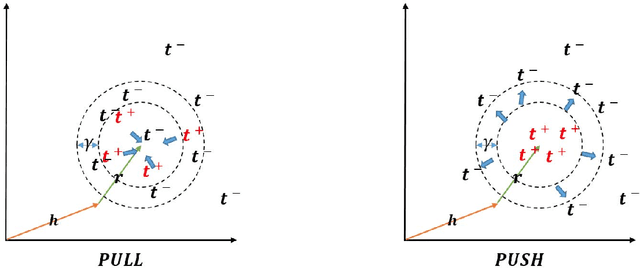
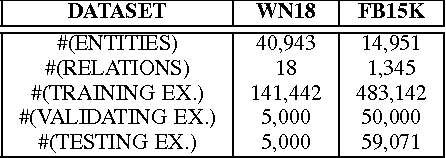
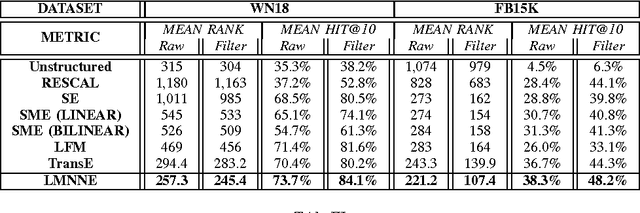

Traditional way of storing facts in triplets ({\it head\_entity, relation, tail\_entity}), abbreviated as ({\it h, r, t}), makes the knowledge intuitively displayed and easily acquired by mankind, but hardly computed or even reasoned by AI machines. Inspired by the success in applying {\it Distributed Representations} to AI-related fields, recent studies expect to represent each entity and relation with a unique low-dimensional embedding, which is different from the symbolic and atomic framework of displaying knowledge in triplets. In this way, the knowledge computing and reasoning can be essentially facilitated by means of a simple {\it vector calculation}, i.e. ${\bf h} + {\bf r} \approx {\bf t}$. We thus contribute an effective model to learn better embeddings satisfying the formula by pulling the positive tail entities ${\bf t^{+}}$ to get together and close to {\bf h} + {\bf r} ({\it Nearest Neighbor}), and simultaneously pushing the negatives ${\bf t^{-}}$ away from the positives ${\bf t^{+}}$ via keeping a {\it Large Margin}. We also design a corresponding learning algorithm to efficiently find the optimal solution based on {\it Stochastic Gradient Descent} in iterative fashion. Quantitative experiments illustrate that our approach can achieve the state-of-the-art performance, compared with several latest methods on some benchmark datasets for two classical applications, i.e. {\it Link prediction} and {\it Triplet classification}. Moreover, we analyze the parameter complexities among all the evaluated models, and analytical results indicate that our model needs fewer computational resources on outperforming the other methods.
Comlex Syntax: Building a Computational Lexicon
Nov 10, 1994
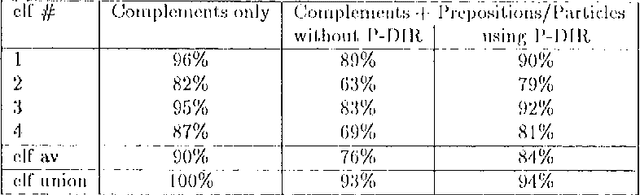
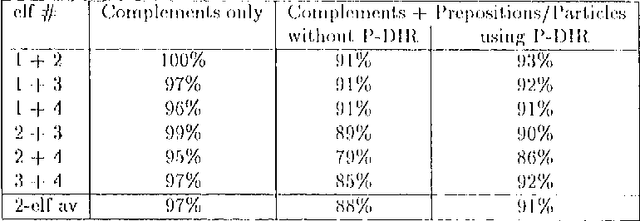
We describe the design of Comlex Syntax, a computational lexicon providing detailed syntactic information for approximately 38,000 English headwords. We consider the types of errors which arise in creating such a lexicon, and how such errors can be measured and controlled.