 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Margin Nearest Neighbor Embedding for Knowledge Representation
Paper and Code
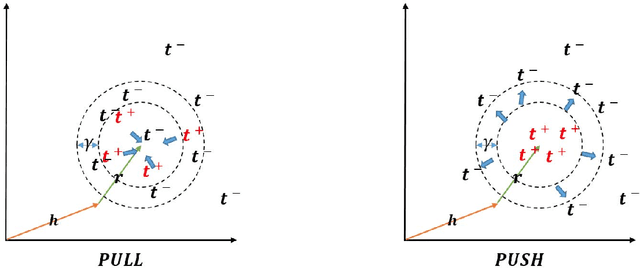
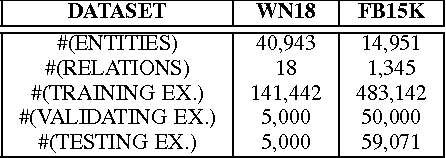
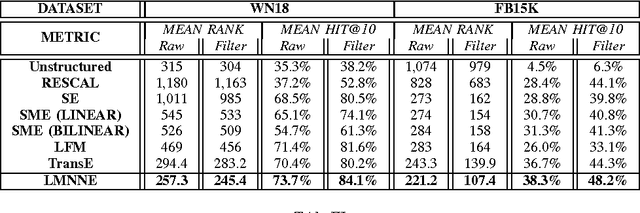

Traditional way of storing facts in triplets ({\it head\_entity, relation, tail\_entity}), abbreviated as ({\it h, r, t}), makes the knowledge intuitively displayed and easily acquired by mankind, but hardly computed or even reasoned by AI machines. Inspired by the success in applying {\it Distributed Representations} to AI-related fields, recent studies expect to represent each entity and relation with a unique low-dimensional embedding, which is different from the symbolic and atomic framework of displaying knowledge in triplets. In this way, the knowledge computing and reasoning can be essentially facilitated by means of a simple {\it vector calculation}, i.e. ${\bf h} + {\bf r} \approx {\bf t}$. We thus contribute an effective model to learn better embeddings satisfying the formula by pulling the positive tail entities ${\bf t^{+}}$ to get together and close to {\bf h} + {\bf r} ({\it Nearest Neighbor}), and simultaneously pushing the negatives ${\bf t^{-}}$ away from the positives ${\bf t^{+}}$ via keeping a {\it Large Margin}. We also design a corresponding learning algorithm to efficiently find the optimal solution based on {\it Stochastic Gradient Descent} in iterative fashion. Quantitative experiments illustrate that our approach can achieve the state-of-the-art performance, compared with several latest methods on some benchmark datasets for two classical applications, i.e. {\it Link prediction} and {\it Triplet classification}. Moreover, we analyze the parameter complexities among all the evaluated models, and analytical results indicate that our model needs fewer computational resources on outperforming the other methods.