 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Speaker Vector Normalization with Maximum Gaussianality Training
Oct 30, 2020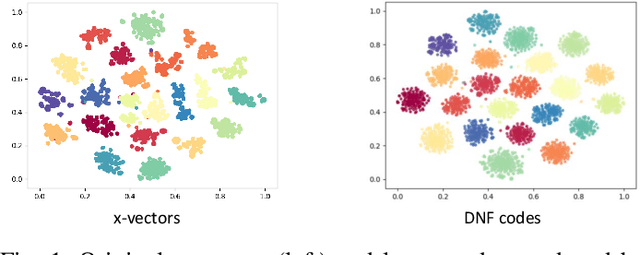
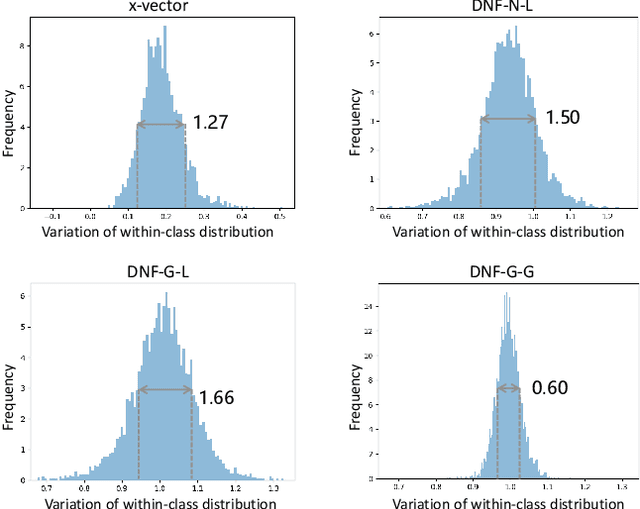
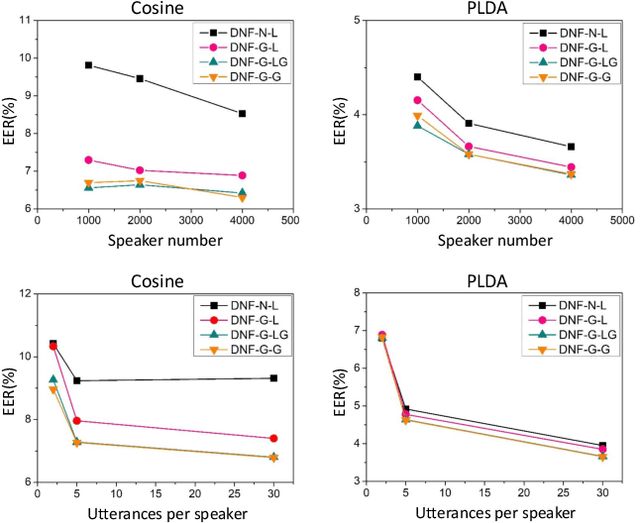
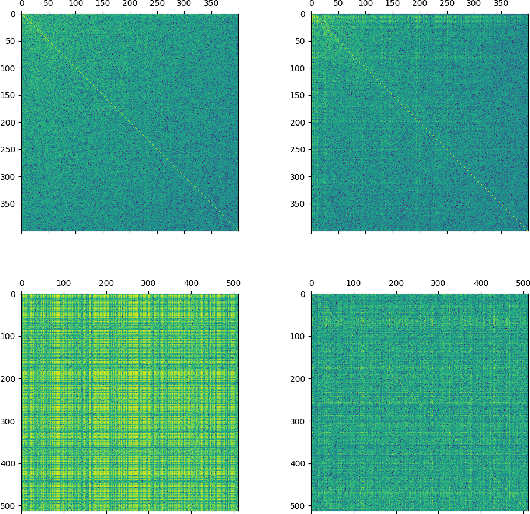
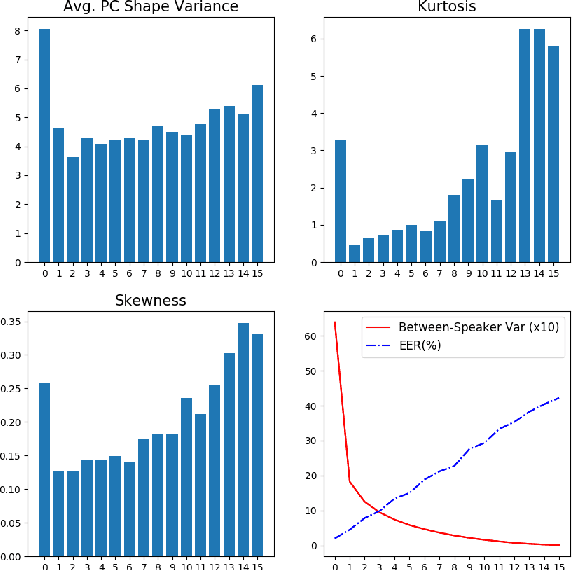
Deep speaker embedding represents the state-of-the-art technique for speaker recognition. A key problem with this approach is that the resulting deep speaker vectors tend to be irregularly distributed. In previous research, we proposed a deep normalization approach based on a new discriminative normalization flow (DNF) model, by which the distributions of individual speakers are arguably transformed to homogeneous Gaussians. This normalization was demonstrated to be effective, but despite this remarkable success, we empirically found that the latent codes produced by the DNF model are generally neither homogeneous nor Gaussian, although the model has assumed so. In this paper, we argue that this problem is largely attributed to the maximum-likelihood (ML) training criterion of the DNF model, which aims to maximize the likelihood of the observations but not necessarily improve the Gaussianality of the latent codes. We therefore propose a new Maximum Gaussianality (MG) training approach that directly maximizes the Gaussianality of the latent codes. Our experiments on two data sets, SITW and CNCeleb, demonstrate that our new MG training approach can deliver much better performance than the previous ML training, and exhibits improved domain generalizability, particularly with regard to cosine scoring.
Deep Normalization for Speaker Vectors
Apr 07, 2020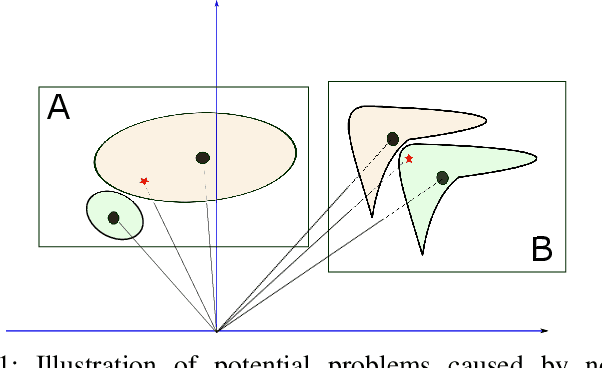
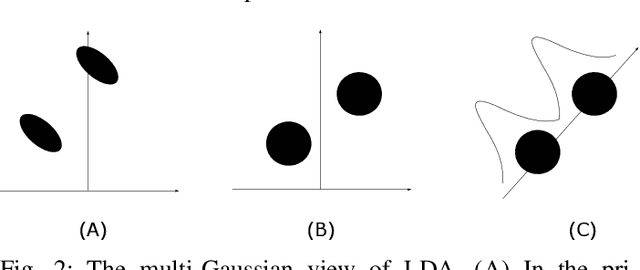
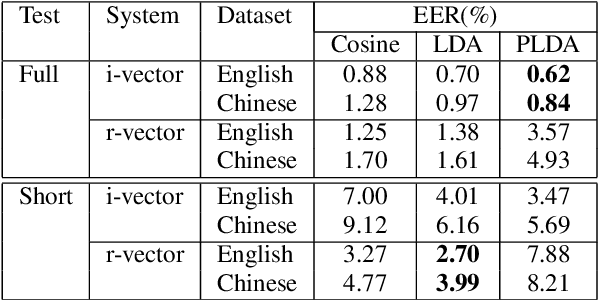
Deep speaker embedding has demonstrated state-of-the-art performance in audio speaker recognition (SRE). However, one potential issue with this approach is that the speaker vectors derived from deep embedding models tend to be non-Gaussian for each individual speaker, and non-homogeneous for distributions of different speakers. These irregular distributions can seriously impact SRE performance, especially with the popular PLDA scoring method, which assumes homogeneous Gaussian distribution. In this paper, we argue that deep speaker vectors require deep normalization, and propose a deep normalization approach based on a novel discriminative normalization flow (DNF) model. We demonstrate the effectiveness of the proposed approach with experiments using the widely used SITW and CNCeleb corpora. In these experiments, the DNF-based normalization delivered substantial performance gains and also showed strong generalization capability in out-of-domain tests.
Phonetic Temporal Neural Model for Language Identification
Aug 25, 2017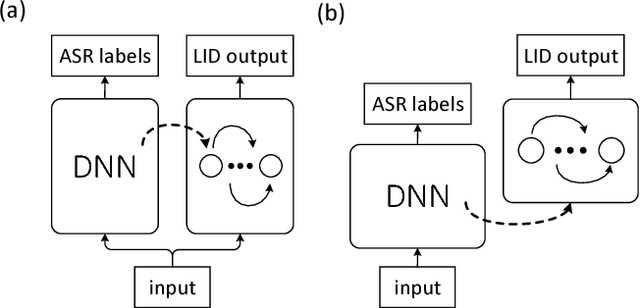
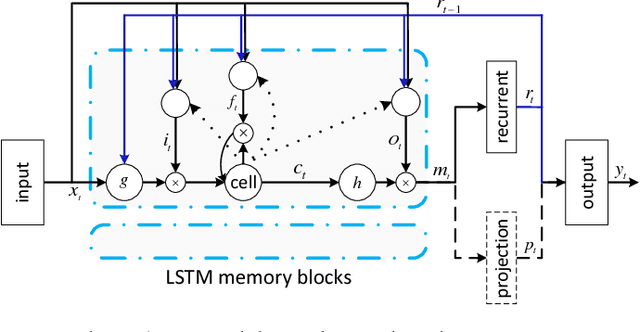
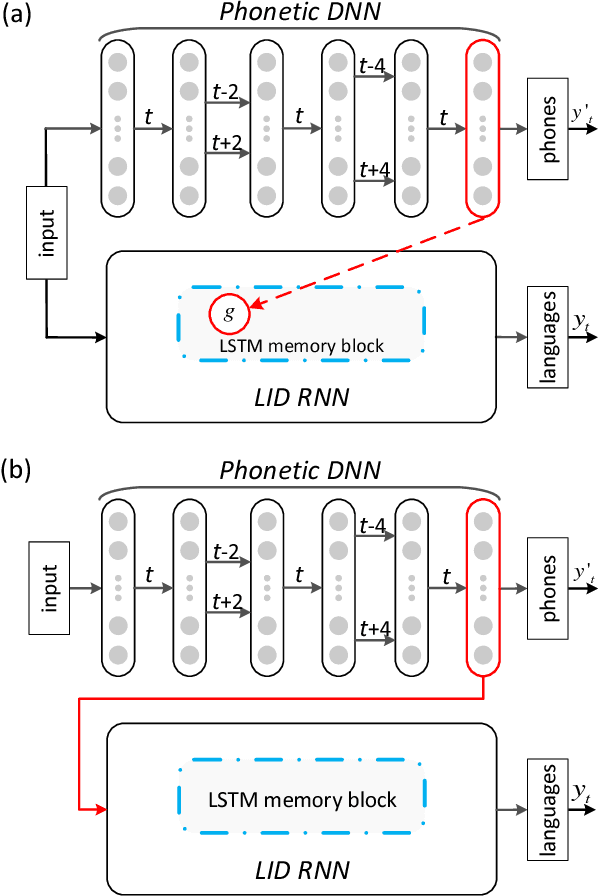
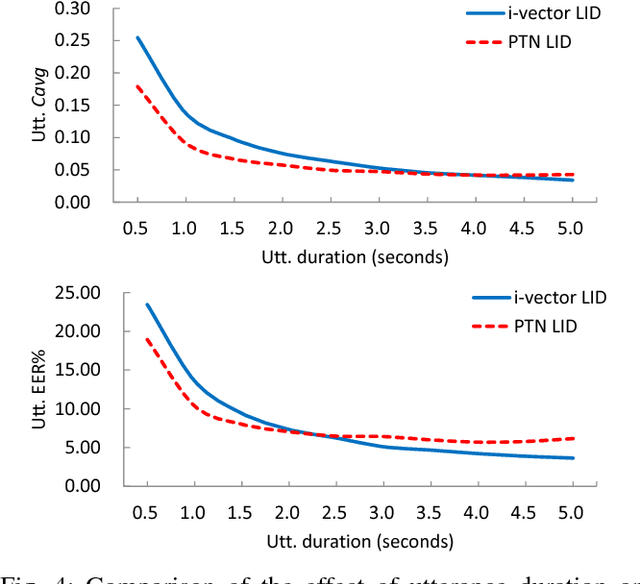
Deep neural models, particularly the LSTM-RNN model, have shown great potential for language identification (LID). However, the use of phonetic information has been largely overlooked by most existing neural LID methods, although this information has been used very successfully in conventional phonetic LID systems. We present a phonetic temporal neural model for LID, which is an LSTM-RNN LID system that accepts phonetic features produced by a phone-discriminative DNN as the input, rather than raw acoustic features. This new model is similar to traditional phonetic LID methods, but the phonetic knowledge here is much richer: it is at the frame level and involves compacted information of all phones. Our experiments conducted on the Babel database and the AP16-OLR database demonstrate that the temporal phonetic neural approach is very effective, and significantly outperforms existing acoustic neural models. It also outperforms the conventional i-vector approach on short utterances and in noisy conditions.
Memory-augmented Neural Machine Translation
Aug 07, 2017

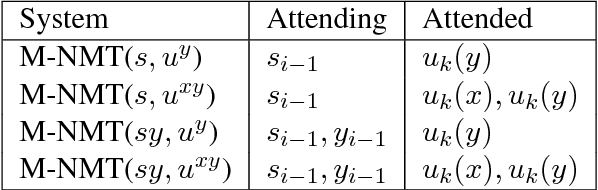
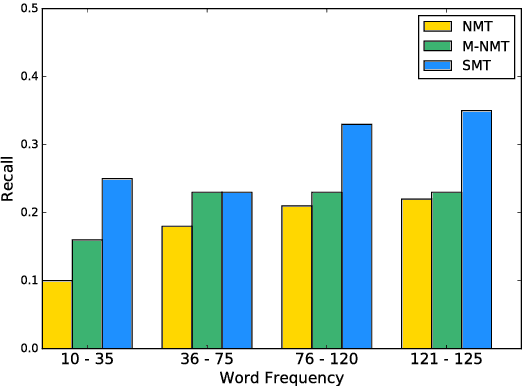
Neural machine translation (NMT) has achieved notable success in recent times, however it is also widely recognized that this approach has limitations with handling infrequent words and word pairs. This paper presents a novel memory-augmented NMT (M-NMT) architecture, which stores knowledge about how words (usually infrequently encountered ones) should be translated in a memory and then utilizes them to assist the neural model. We use this memory mechanism to combine the knowledge learned from a conventional statistical machine translation system and the rules learned by an NMT system, and also propose a solution for out-of-vocabulary (OOV) words based on this framework. Our experiments on two Chinese-English translation tasks demonstrated that the M-NMT architecture outperformed the NMT baseline by $9.0$ and $2.7$ BLEU points on the two tasks, respectively. Additionally, we found this architecture resulted in a much more effective OOV treatment compared to competitive methods.
Collaborative Learning for Language and Speaker Recognition
May 23, 2017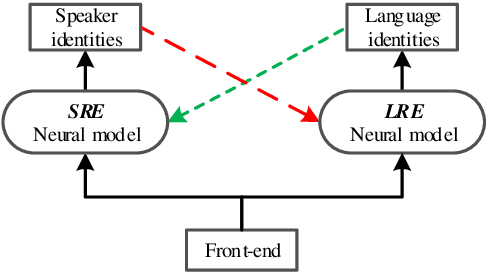
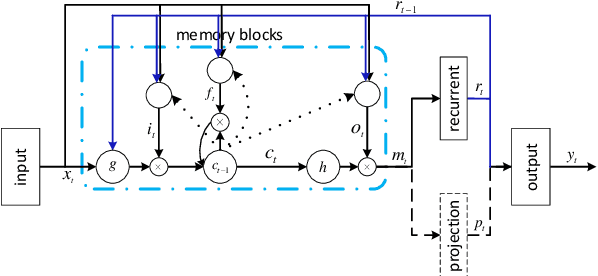
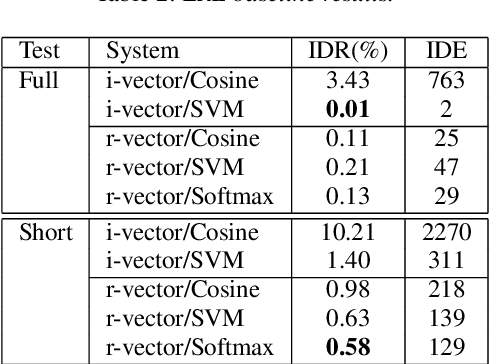
This paper presents a unified model to perform language and speaker recognition simultaneously and altogether. The model is based on a multi-task recurrent neural network where the output of one task is fed as the input of the other, leading to a collaborative learning framework that can improve both language and speaker recognition by borrowing information from each other. Our experiments demonstrated that the multi-task model outperforms the task-specific models on both tasks.
Flexible and Creative Chinese Poetry Generation Using Neural Memory
May 10, 2017
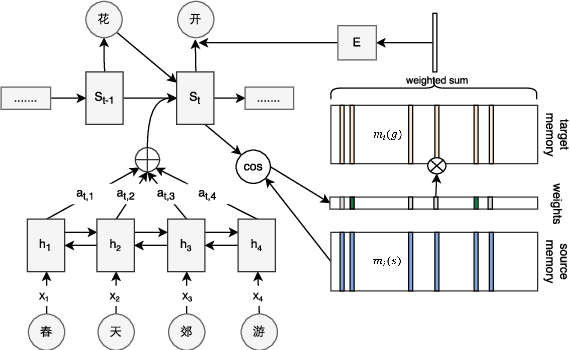
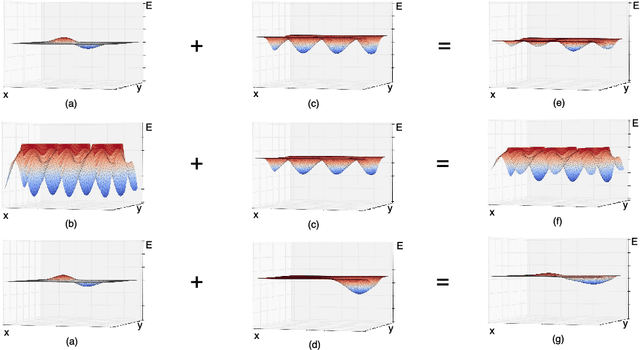

It has been shown that Chinese poems can be successfully generated by sequence-to-sequence neural models, particularly with the attention mechanism. A potential problem of this approach, however, is that neural models can only learn abstract rules, while poem generation is a highly creative process that involves not only rules but also innovations for which pure statistical models are not appropriate in principle. This work proposes a memory-augmented neural model for Chinese poem generation, where the neural model and the augmented memory work together to balance the requirements of linguistic accordance and aesthetic innovation, leading to innovative generations that are still rule-compliant. In addition, it is found that the memory mechanism provides interesting flexibility that can be used to generate poems with different styles.
Probabilistic Belief Embedding for Knowledge Base Completion
May 22, 2015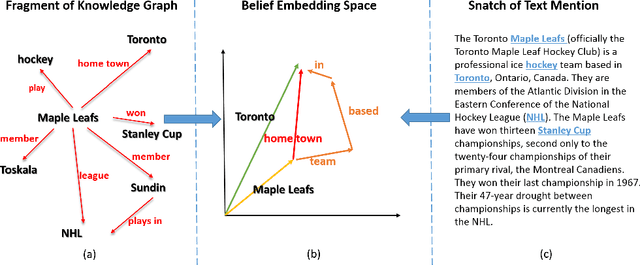
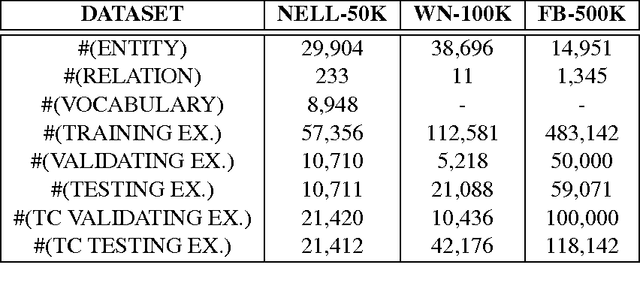
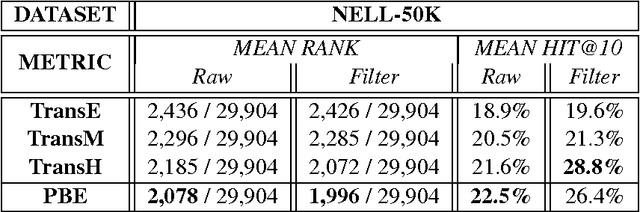
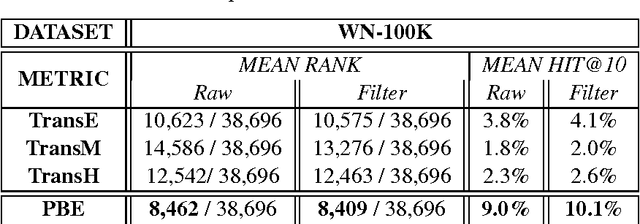
This paper contributes a novel embedding model which measures the probability of each belief $\langle h,r,t,m\rangle$ in a large-scale knowledge repository via simultaneously learning distributed representations for entities ($h$ and $t$), relations ($r$), and the words in relation mentions ($m$). It facilitates knowledge completion by means of simple vector operations to discover new beliefs. Given an imperfect belief, we can not only infer the missing entities, predict the unknown relations, but also tell the plausibility of the belief, just leveraging the learnt embeddings of remaining evidences. To demonstrate the scalability and the effectiveness of our model, we conduct experiments on several large-scale repositories which contain millions of beliefs from WordNet, Freebase and NELL, and compare it with other cutting-edge approaches via competing the performances assessed by the tasks of entity inference, relation prediction and triplet classification with respective metrics. Extensive experimental results show that the proposed model outperforms the state-of-the-arts with significant improvements.