 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Speaker Vector Normalization with Maximum Gaussianality Training
Paper and Code
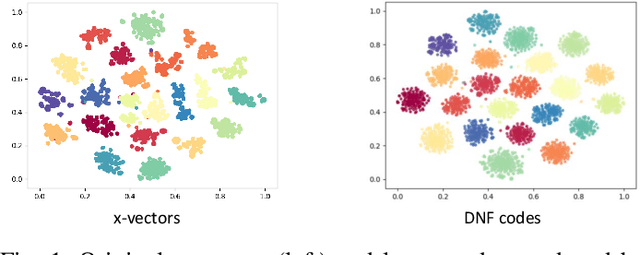
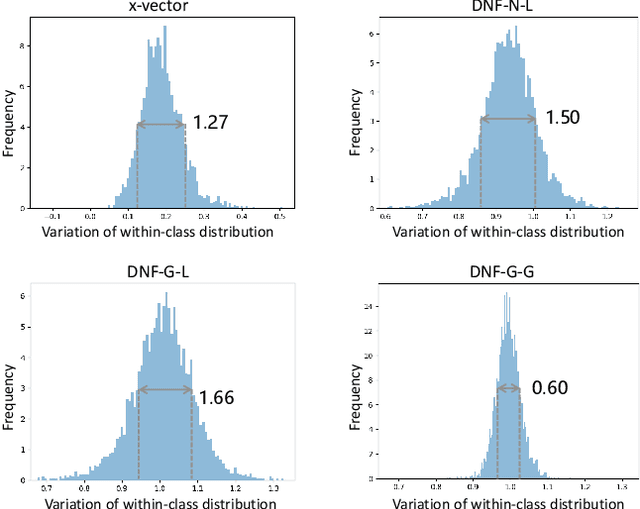
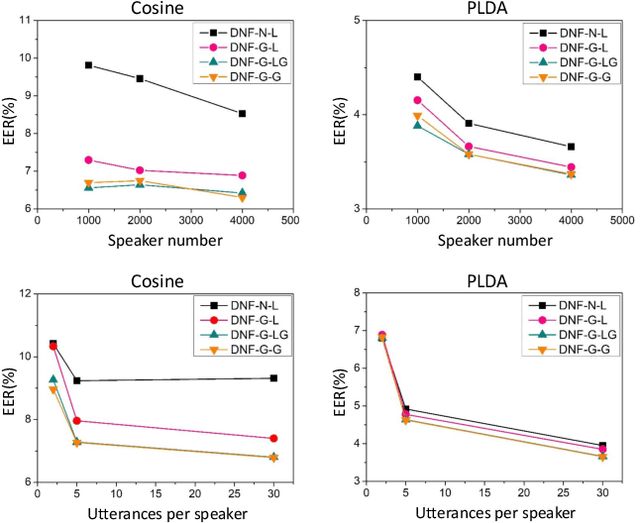
Deep speaker embedding represents the state-of-the-art technique for speaker recognition. A key problem with this approach is that the resulting deep speaker vectors tend to be irregularly distributed. In previous research, we proposed a deep normalization approach based on a new discriminative normalization flow (DNF) model, by which the distributions of individual speakers are arguably transformed to homogeneous Gaussians. This normalization was demonstrated to be effective, but despite this remarkable success, we empirically found that the latent codes produced by the DNF model are generally neither homogeneous nor Gaussian, although the model has assumed so. In this paper, we argue that this problem is largely attributed to the maximum-likelihood (ML) training criterion of the DNF model, which aims to maximize the likelihood of the observations but not necessarily improve the Gaussianality of the latent codes. We therefore propose a new Maximum Gaussianality (MG) training approach that directly maximizes the Gaussianality of the latent codes. Our experiments on two data sets, SITW and CNCeleb, demonstrate that our new MG training approach can deliver much better performance than the previous ML training, and exhibits improved domain generalizability, particularly with regard to cosine scoring.