Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Learning for Language and Speaker Recognition
Paper and Code
May 23, 2017
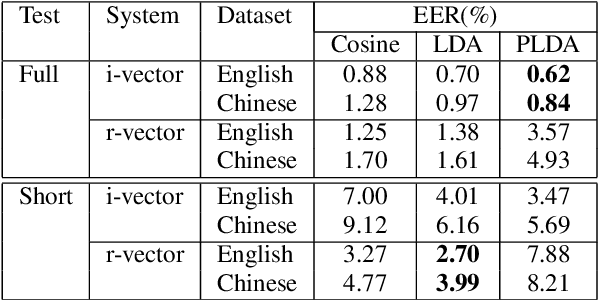
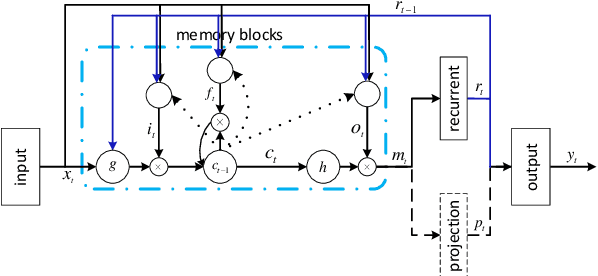
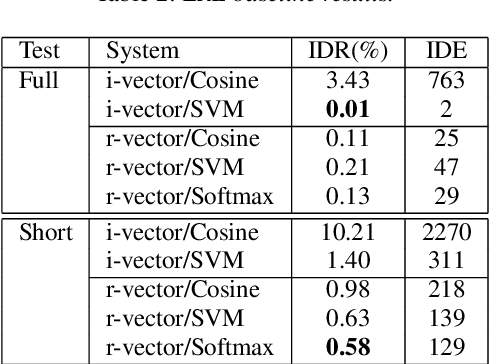
This paper presents a unified model to perform language and speaker recognition simultaneously and altogether. The model is based on a multi-task recurrent neural network where the output of one task is fed as the input of the other, leading to a collaborative learning framework that can improve both language and speaker recognition by borrowing information from each other. Our experiments demonstrated that the multi-task model outperforms the task-specific models on both tasks.
View paper on