 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIBE: Video Inference for Human Body Pose and Shape Estimation
Paper and Code
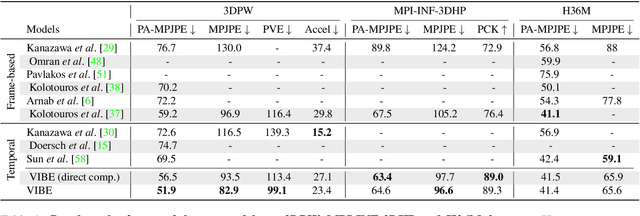

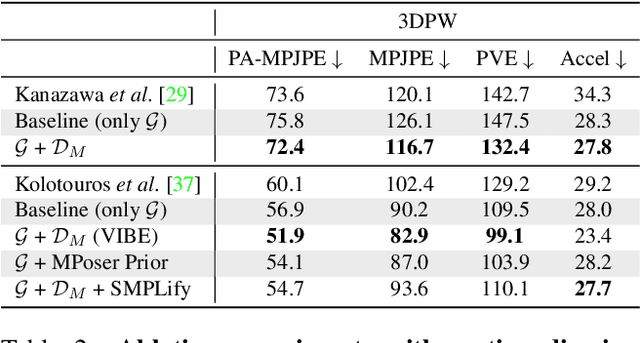
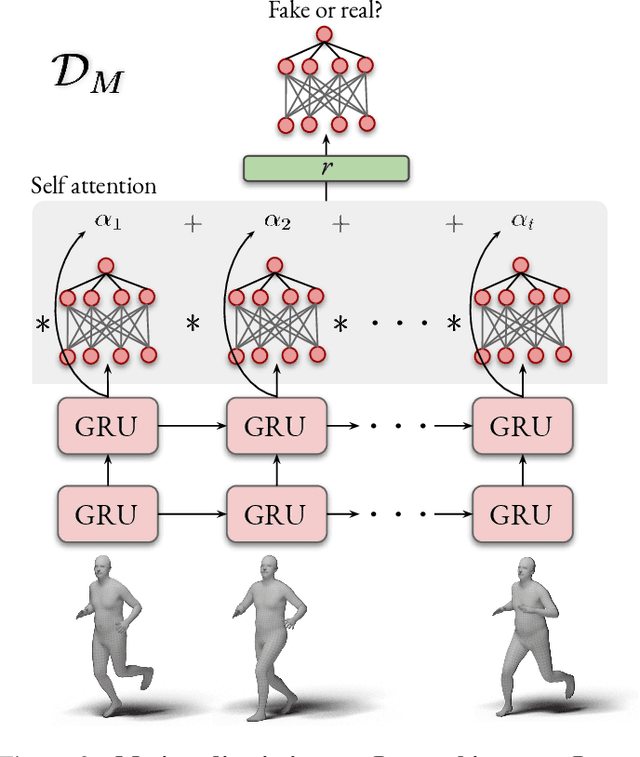
Human motion is fundamental to understanding behavior. Despite progress on single-image 3D pose and shape estimation, existing video-based state-of-the-art methods fail to produce accurate and natural motion sequences due to a lack of ground-truth 3D motion data for training. To address this problem, we propose Video Inference for Body Pose and Shape Estimation (VIBE), which makes use of an existing large-scale motion capture dataset (AMASS) together with unpaired, in-the-wild, 2D keypoint annotations. Our key novelty is an adversarial learning framework that leverages AMASS to discriminate between real human motions and those produced by our temporal pose and shape regression networks. We define a temporal network architecture and show that adversarial training, at the sequence level, produces kinematically plausible motion sequences without in-the-wild ground-truth 3D labels. We perform extensive experimentation to analyze the importance of motion and demonstrate the effectiveness of VIBE on challenging 3D pose estimation datasets, achieving state-of-the-art performance. Code and pretrained models are available at https://github.com/mkocabas/VIBE.