 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHORE: Contact, Human and Object REconstruction from a single RGB image
Paper and Code
Apr 05, 2022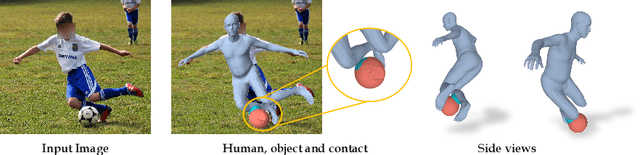

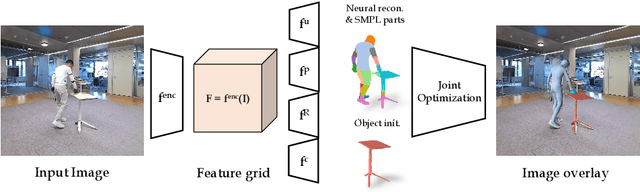
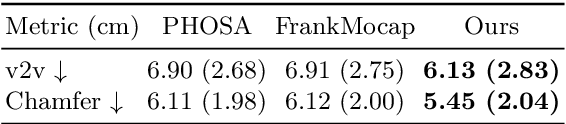
While most works in computer vision and learning have focused on perceiving 3D humans from single images in isolation, in this work we focus on capturing 3D humans interacting with objects. The problem is extremely challenging due to heavy occlusions between human and object, diverse interaction types and depth ambiguity. In this paper, we introduce CHORE, a novel method that learns to jointly reconstruct human and object from a single image. CHORE takes inspiration from recent advances in implicit surface learning and classical model-based fitting. We compute a neural reconstruction of human and object represented implicitly with two unsigned distance fields, and additionally predict a correspondence field to a parametric body as well as an object pose field. This allows us to robustly fit a parametric body model and a 3D object template, while reasoning about interactions. Furthermore, prior pixel-aligned implicit learning methods use synthetic data and make assumptions that are not met in real data. We propose a simple yet effective depth-aware scaling that allows more efficient shape learning on real data. Our experiments show that our joint reconstruction learned with the proposed strategy significantly outperforms the SOTA. Our code and models will be released to foster future research in this direction.