 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking by 3D Model Estimation of Unknown Objects in Videos
Paper and Code
Apr 13, 2023
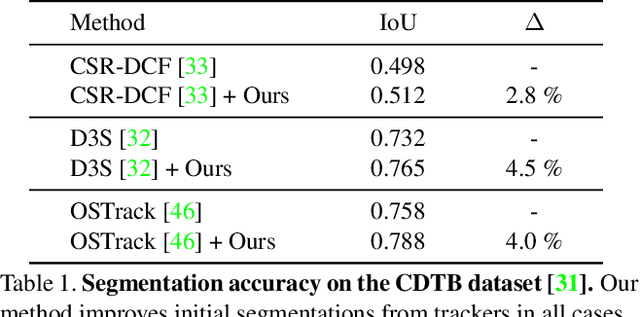
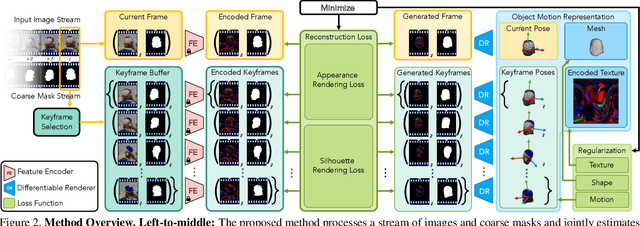
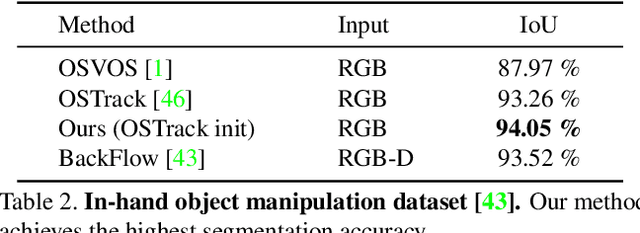
Most model-free visual object tracking methods formulate the tracking task as object location estimation given by a 2D segmentation or a bounding box in each video frame. We argue that this representation is limited and instead propose to guide and improve 2D tracking with an explicit object representation, namely the textured 3D shape and 6DoF pose in each video frame. Our representation tackles a complex long-term dense correspondence problem between all 3D points on the object for all video frames, including frames where some points are invisible. To achieve that, the estimation is driven by re-rendering the input video frames as well as possible through differentiable rendering, which has not been used for tracking before. The proposed optimization minimizes a novel loss function to estimate the best 3D shape, texture, and 6DoF pose. We improve the state-of-the-art in 2D segmentation tracking on three different datasets with mostly rigid objects.