 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating Data for Optimal and Private Learning
Nov 28, 2024Multiple Instance Regression (MIR) and Learning from Label Proportions (LLP) are learning frameworks arising in many applications, where the training data is partitioned into disjoint sets or bags, and only an aggregate label i.e., bag-label for each bag is available to the learner. In the case of MIR, the bag-label is the label of an undisclosed instance from the bag, while in LLP, the bag-label is the mean of the bag's labels. In this paper, we study for various loss functions in MIR and LLP, what is the optimal way to partition the dataset into bags such that the utility for downstream tasks like linear regression is maximized. We theoretically provide utility guarantees, and show that in each case, the optimal bagging strategy (approximately) reduces to finding an optimal clustering of the feature vectors or the labels with respect to natural objectives such as $k$-means. We also show that our bagging mechanisms can be made label-differentially private, incurring an additional utility error. We then generalize our results to the setting of Generalized Linear Models (GLMs). Finally, we experimentally validate our theoretical results.
Learning Predictive Checklists with Probabilistic Logic Programming
Nov 25, 2024
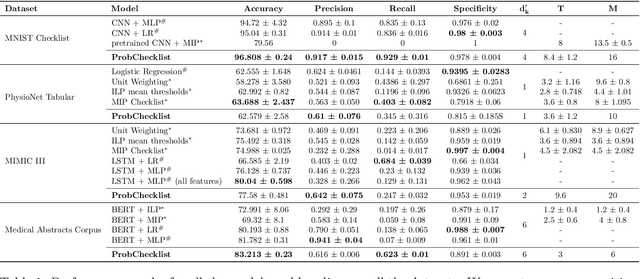
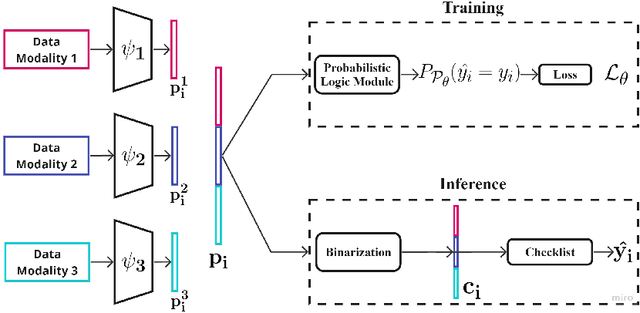

Checklists have been widely recognized as effective tools for completing complex tasks in a systematic manner. Although originally intended for use in procedural tasks, their interpretability and ease of use have led to their adoption for predictive tasks as well, including in clinical settings. However, designing checklists can be challenging, often requiring expert knowledge and manual rule design based on available data. Recent work has attempted to address this issue by using machine learning to automatically generate predictive checklists from data, although these approaches have been limited to Boolean data. We propose a novel method for learning predictive checklists from diverse data modalities, such as images and time series. Our approach relies on probabilistic logic programming, a learning paradigm that enables matching the discrete nature of checklist with continuous-valued data. We propose a regularization technique to tradeoff between the information captured in discrete concepts of continuous data and permit a tunable level of interpretability for the learned checklist concepts. We demonstrate that our method outperforms various explainable machine learning techniques on prediction tasks involving image sequences, time series, and clinical notes.
Weak to Strong Learning from Aggregate Labels
Nov 09, 2024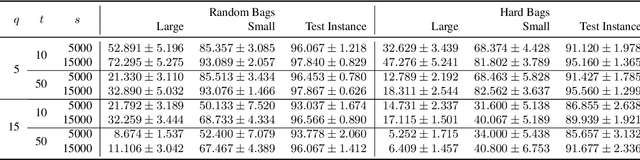
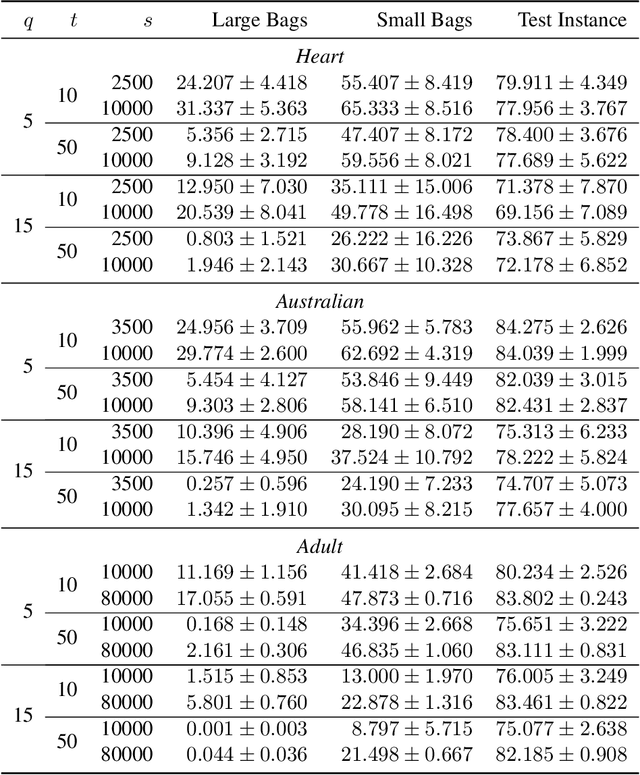


In learning from aggregate labels, the training data consists of sets or "bags" of feature-vectors (instances) along with an aggregate label for each bag derived from the (usually {0,1}-valued) labels of its instances. In learning from label proportions (LLP), the aggregate label is the average of the bag's instance labels, whereas in multiple instance learning (MIL) it is the OR. The goal is to train an instance-level predictor, typically achieved by fitting a model on the training data, in particular one that maximizes the accuracy which is the fraction of satisfied bags i.e., those on which the predicted labels are consistent with the aggregate label. A weak learner has at a constant accuracy < 1 on the training bags, while a strong learner's accuracy can be arbitrarily close to 1. We study the problem of using a weak learner on such training bags with aggregate labels to obtain a strong learner, analogous to supervised learning for which boosting algorithms are known. Our first result shows the impossibility of boosting in LLP using weak classifiers of any accuracy < 1 by constructing a collection of bags for which such weak learners (for any weight assignment) exist, while not admitting any strong learner. A variant of this construction also rules out boosting in MIL for a non-trivial range of weak learner accuracy. In the LLP setting however, we show that a weak learner (with small accuracy) on large enough bags can in fact be used to obtain a strong learner for small bags, in polynomial time. We also provide more efficient, sampling based variant of our procedure with probabilistic guarantees which are empirically validated on three real and two synthetic datasets. Our work is the first to theoretically study weak to strong learning from aggregate labels, with an algorithm to achieve the same for LLP, while proving the impossibility of boosting for both LLP and MIL.
Modularity aided consistent attributed graph clustering via coarsening
Jul 09, 2024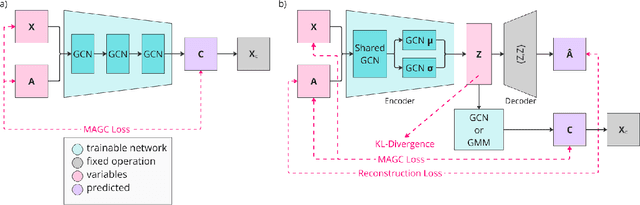
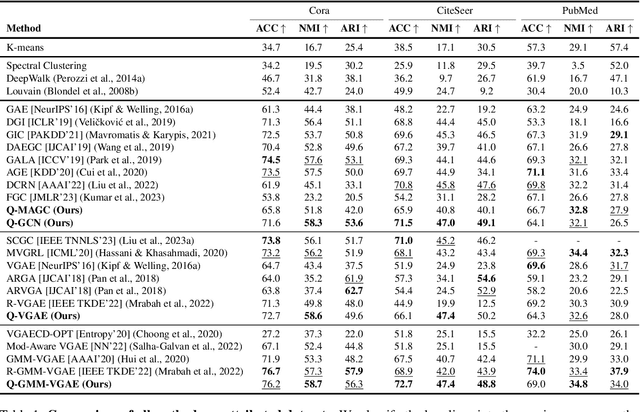
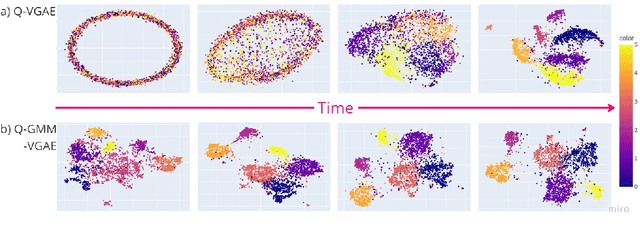
Graph clustering is an important unsupervised learning technique for partitioning graphs with attributes and detecting communities. However, current methods struggle to accurately capture true community structures and intra-cluster relations, be computationally efficient, and identify smaller communities. We address these challenges by integrating coarsening and modularity maximization, effectively leveraging both adjacency and node features to enhance clustering accuracy. We propose a loss function incorporating log-determinant, smoothness, and modularity components using a block majorization-minimization technique, resulting in superior clustering outcomes. The method is theoretically consistent under the Degree-Corrected Stochastic Block Model (DC-SBM), ensuring asymptotic error-free performance and complete label recovery. Our provably convergent and time-efficient algorithm seamlessly integrates with graph neural networks (GNNs) and variational graph autoencoders (VGAEs) to learn enhanced node features and deliver exceptional clustering performance. Extensive experiments on benchmark datasets demonstrate its superiority over existing state-of-the-art methods for both attributed and non-attributed graphs.
FRACTAL: Fine-Grained Scoring from Aggregate Text Labels
Apr 07, 2024Large language models (LLMs) are being increasingly tuned to power complex generation tasks such as writing, fact-seeking, querying and reasoning. Traditionally, human or model feedback for evaluating and further tuning LLM performance has been provided at the response level, enabling faster and more cost-effective assessments. However, recent works (Amplayo et al. [2022], Wu et al. [2023]) indicate that sentence-level labels may provide more accurate and interpretable feedback for LLM optimization. In this work, we introduce methods to disaggregate response-level labels into sentence-level (pseudo-)labels. Our approach leverages multiple instance learning (MIL) and learning from label proportions (LLP) techniques in conjunction with prior information (e.g., document-sentence cosine similarity) to train a specialized model for sentence-level scoring. We also employ techniques which use model predictions to pseudo-label the train-set at the sentence-level for model training to further improve performance. We conduct extensive evaluations of our methods across six datasets and four tasks: retrieval, question answering, summarization, and math reasoning. Our results demonstrate improved performance compared to multiple baselines across most of these tasks. Our work is the first to develop response-level feedback to sentence-level scoring techniques, leveraging sentence-level prior information, along with comprehensive evaluations on multiple tasks as well as end-to-end finetuning evaluation showing performance comparable to a model trained on fine-grained human annotated labels.
Learning predictive checklists from continuous medical data
Nov 14, 2022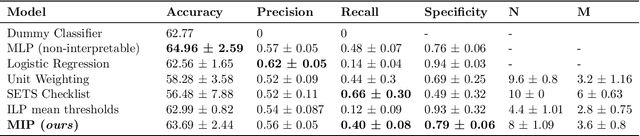
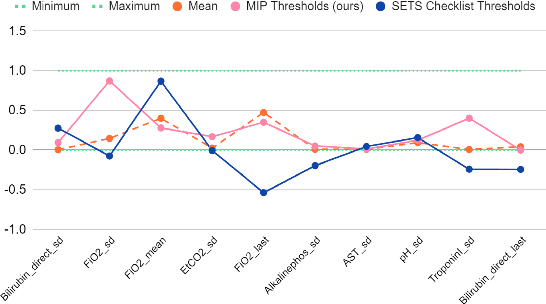
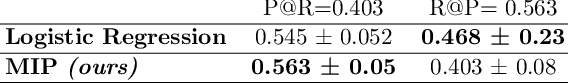
Checklists, while being only recently introduced in the medical domain, have become highly popular in daily clinical practice due to their combined effectiveness and great interpretability. Checklists are usually designed by expert clinicians that manually collect and analyze available evidence. However, the increasing quantity of available medical data is calling for a partially automated checklist design. Recent works have taken a step in that direction by learning predictive checklists from categorical data. In this work, we propose to extend this approach to accomodate learning checklists from continuous medical data using mixed-integer programming approach. We show that this extension outperforms a range of explainable machine learning baselines on the prediction of sepsis from intensive care clinical trajectories.
* Extended Abstract presented at Machine Learning for Health (ML4H) symposium 2022, November 28th, 2022, New Orleans, United States & Virtual, http://www.ml4h.cc, 7 pages
Severity and Mortality Prediction Models to Triage Indian COVID-19 Patients
Sep 02, 2021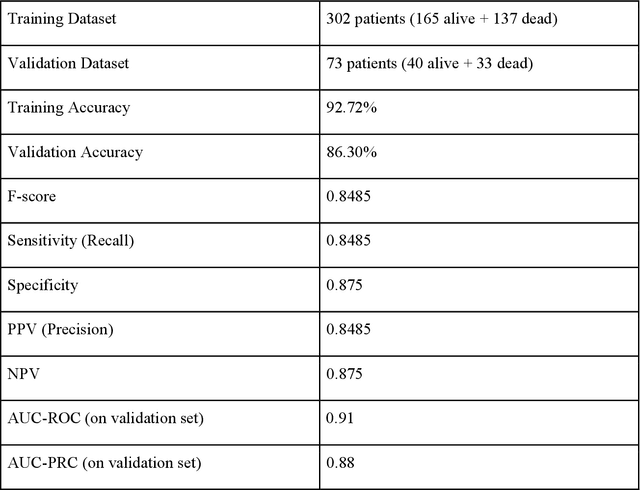
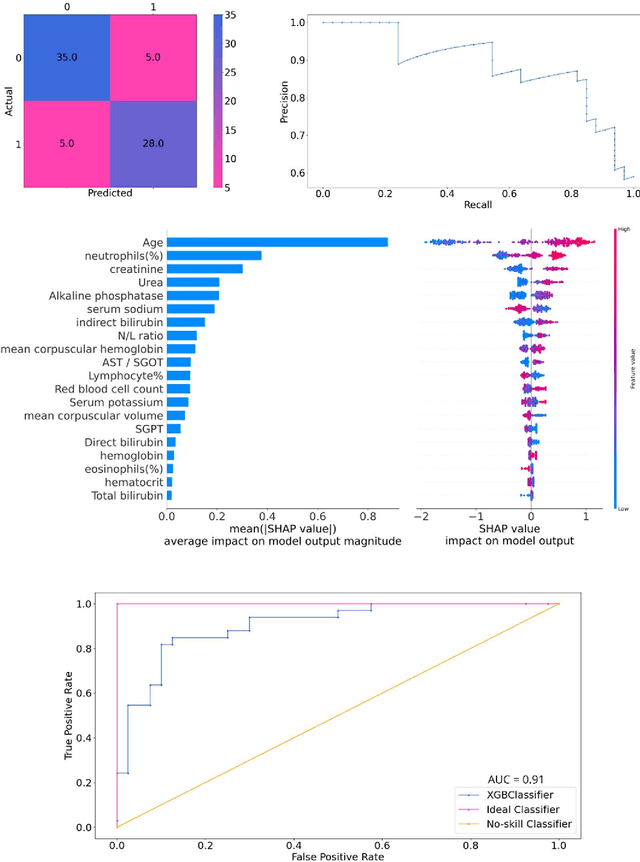
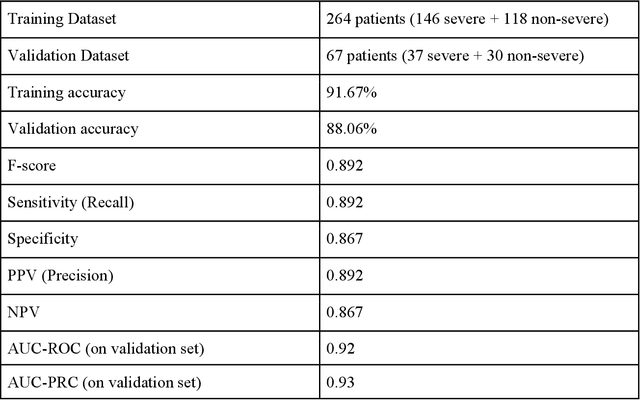
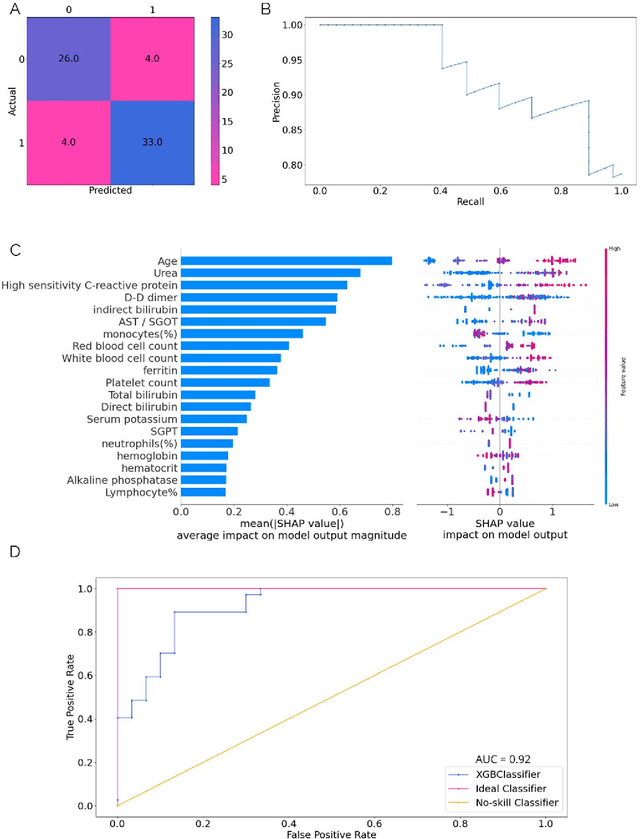
As the second wave in India mitigates, COVID-19 has now infected about 29 million patients countrywide, leading to more than 350 thousand people dead. As the infections surged, the strain on the medical infrastructure in the country became apparent. While the country vaccinates its population, opening up the economy may lead to an increase in infection rates. In this scenario, it is essential to effectively utilize the limited hospital resources by an informed patient triaging system based on clinical parameters. Here, we present two interpretable machine learning models predicting the clinical outcomes, severity, and mortality, of the patients based on routine non-invasive surveillance of blood parameters from one of the largest cohorts of Indian patients at the day of admission. Patient severity and mortality prediction models achieved 86.3% and 88.06% accuracy, respectively, with an AUC-ROC of 0.91 and 0.92. We have integrated both the models in a user-friendly web app calculator, https://triage-COVID-19.herokuapp.com/, to showcase the potential deployment of such efforts at scale.
Challenges in the application of a mortality prediction model for COVID-19 patients on an Indian cohort
Jan 15, 2021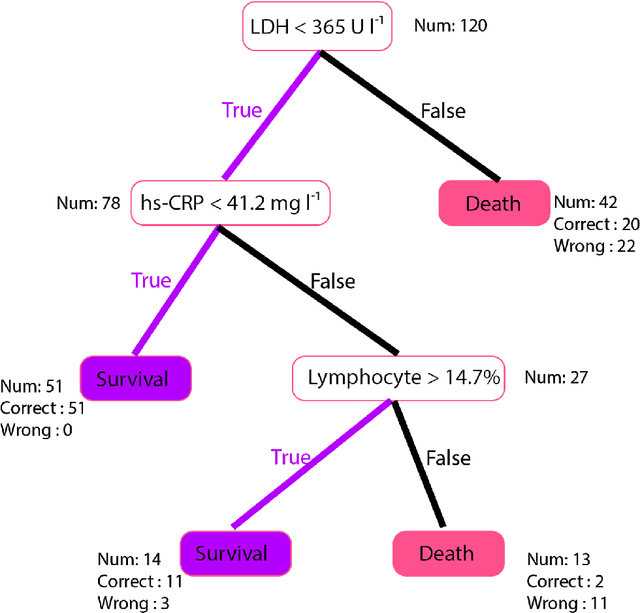
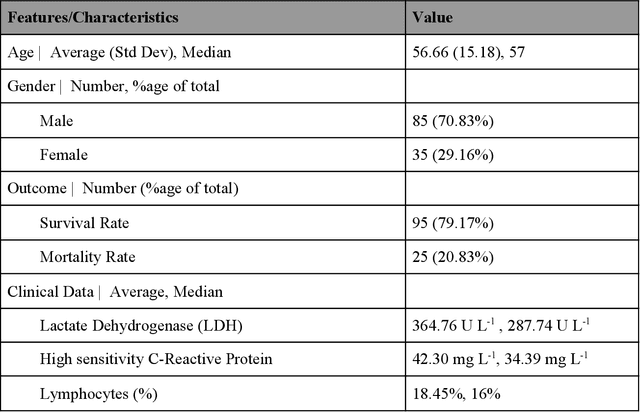
Many countries are now experiencing the third wave of the COVID-19 pandemic straining the healthcare resources with an acute shortage of hospital beds and ventilators for the critically ill patients. This situation is especially worse in India with the second largest load of COVID-19 cases and a relatively resource-scarce medical infrastructure. Therefore, it becomes essential to triage the patients based on the severity of their disease and devote resources towards critically ill patients. Yan et al. 1 have published a very pertinent research that uses Machine learning (ML) methods to predict the outcome of COVID-19 patients based on their clinical parameters at the day of admission. They used the XGBoost algorithm, a type of ensemble model, to build the mortality prediction model. The final classifier is built through the sequential addition of multiple weak classifiers. The clinically operable decision rule was obtained from a 'single-tree XGBoost' and used lactic dehydrogenase (LDH), lymphocyte and high-sensitivity C-reactive protein (hs-CRP) values. This decision tree achieved a 100% survival prediction and 81% mortality prediction. However, these models have several technical challenges and do not provide an out of the box solution that can be deployed for other populations as has been reported in the "Matters Arising" section of Yan et al. Here, we show the limitations of this model by deploying it on one of the largest datasets of COVID-19 patients containing detailed clinical parameters collected from India.