 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak to Strong Learning from Aggregate Labels
Paper and Code
Nov 09, 2024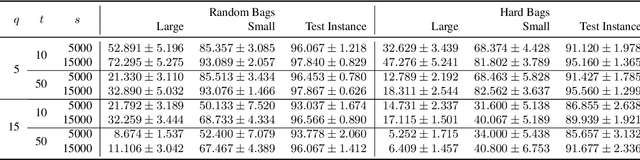
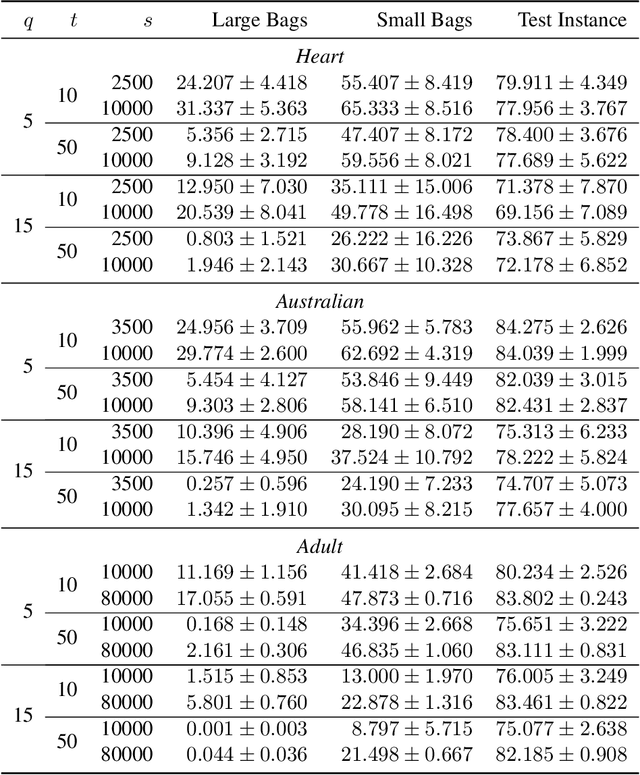


In learning from aggregate labels, the training data consists of sets or "bags" of feature-vectors (instances) along with an aggregate label for each bag derived from the (usually {0,1}-valued) labels of its instances. In learning from label proportions (LLP), the aggregate label is the average of the bag's instance labels, whereas in multiple instance learning (MIL) it is the OR. The goal is to train an instance-level predictor, typically achieved by fitting a model on the training data, in particular one that maximizes the accuracy which is the fraction of satisfied bags i.e., those on which the predicted labels are consistent with the aggregate label. A weak learner has at a constant accuracy < 1 on the training bags, while a strong learner's accuracy can be arbitrarily close to 1. We study the problem of using a weak learner on such training bags with aggregate labels to obtain a strong learner, analogous to supervised learning for which boosting algorithms are known. Our first result shows the impossibility of boosting in LLP using weak classifiers of any accuracy < 1 by constructing a collection of bags for which such weak learners (for any weight assignment) exist, while not admitting any strong learner. A variant of this construction also rules out boosting in MIL for a non-trivial range of weak learner accuracy. In the LLP setting however, we show that a weak learner (with small accuracy) on large enough bags can in fact be used to obtain a strong learner for small bags, in polynomial time. We also provide more efficient, sampling based variant of our procedure with probabilistic guarantees which are empirically validated on three real and two synthetic datasets. Our work is the first to theoretically study weak to strong learning from aggregate labels, with an algorithm to achieve the same for LLP, while proving the impossibility of boosting for both LLP and MIL.