 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking GNN Models on Molecular Regression Tasks with CKA-Based Representation Analysis
Feb 24, 2026Molecules are commonly represented as SMILES strings, which can be readily converted to fixed-size molecular fingerprints. These fingerprints serve as feature vectors to train ML/DL models for molecular property prediction tasks in the field of computational chemistry, drug discovery, biochemistry, and materials science. Recent research has demonstrated that SMILES can be used to construct molecular graphs where atoms are nodes ($V$) and bonds are edges ($E$). These graphs can subsequently be used to train geometric DL models like GNN. GNN learns the inherent structural relationships within a molecule rather than depending on fixed-size fingerprints. Although GNN are powerful aggregators, their efficacy on smaller datasets and inductive biases across different architectures is less studied. In our present study, we performed a systematic benchmarking of four different GNN architectures across a diverse domain of datasets (physical chemistry, biological, and analytical). Additionally, we have also implemented a hierarchical fusion (GNN+FP) framework for target prediction. We observed that the fusion framework consistently outperforms or matches the performance of standalone GNN (RMSE improvement > $7\%$) and baseline models. Further, we investigated the representational similarity using centered kernel alignment (CKA) between GNN and fingerprint embeddings and found that they occupy highly independent latent spaces (CKA $\le0.46$). The cross-architectural CKA score suggests a high convergence between isotopic models like GCN, GraphSAGE and GIN (CKA $\geq0.88$), with GAT learning moderately independent representation (CKA $0.55-0.80$).
Understanding Virality: A Rubric based Vision-Language Model Framework for Short-Form Edutainment Evaluation
Dec 24, 2025Evaluating short-form video content requires moving beyond surface-level quality metrics toward human-aligned, multimodal reasoning. While existing frameworks like VideoScore-2 assess visual and semantic fidelity, they do not capture how specific audiovisual attributes drive real audience engagement. In this work, we propose a data-driven evaluation framework that uses Vision-Language Models (VLMs) to extract unsupervised audiovisual features, clusters them into interpretable factors, and trains a regression-based evaluator to predict engagement on short-form edutainment videos. Our curated YouTube Shorts dataset enables systematic analysis of how VLM-derived features relate to human engagement behavior. Experiments show strong correlations between predicted and actual engagement, demonstrating that our lightweight, feature-based evaluator provides interpretable and scalable assessments compared to traditional metrics (e.g., SSIM, FID). By grounding evaluation in both multimodal feature importance and human-centered engagement signals, our approach advances toward robust and explainable video understanding.
Innovations in Agricultural Forecasting: A Multivariate Regression Study on Global Crop Yield Prediction
Dec 04, 2023
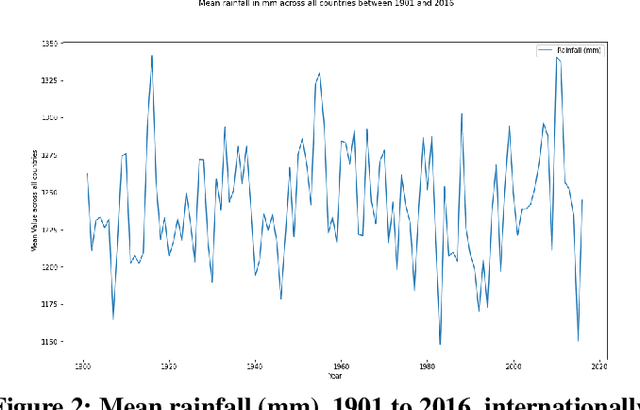
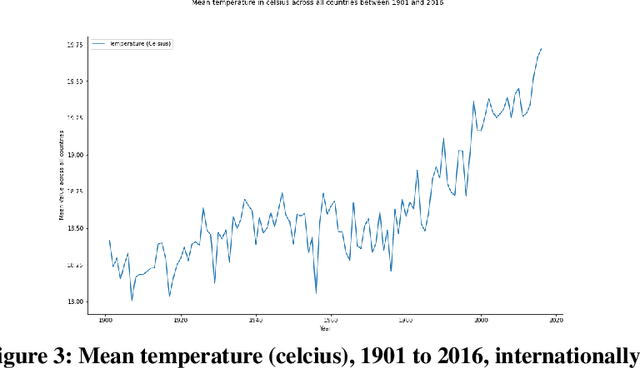
The prediction of crop yields internationally is a crucial objective in agricultural research. Thus, this study implements 6 regression models (Linear, Tree, Gradient Descent, Gradient Boosting, K- Nearest Neighbors, and Random Forest) to predict crop yields in 196 countries. Given 4 key training parameters, pesticides (tonnes), rainfall (mm), temperature (Celsius), and yield (hg/ha), it was found that our Random Forest Regression model achieved a determination coefficient (r^2) of 0.94, with a margin of error (ME) of .03. The models were trained and tested using the Food and Agricultural Organization of the United Nations data, along with the World Bank Climate Change Data Catalog. Furthermore, each parameter was analyzed to understand how varying factors could impact overall yield. We used unconventional models, contrary to generally used Deep Learning (DL) and Machine Learning (ML) models, combined with recently collected data to implement a unique approach in our research. Existing scholarship would benefit from understanding the most optimal model for agricultural research, specifically using the United Nations data.
Which Modality should I use -- Text, Motif, or Image? : Understanding Graphs with Large Language Models
Nov 16, 2023



Large language models (LLMs) are revolutionizing various fields by leveraging large text corpora for context-aware intelligence. Due to the context size, however, encoding an entire graph with LLMs is fundamentally limited. This paper explores how to better integrate graph data with LLMs and presents a novel approach using various encoding modalities (e.g., text, image, and motif) and approximation of global connectivity of a graph using different prompting methods to enhance LLMs' effectiveness in handling complex graph structures. The study also introduces GraphTMI, a new benchmark for evaluating LLMs in graph structure analysis, focusing on factors such as homophily, motif presence, and graph difficulty. Key findings reveal that image modality, supported by advanced vision-language models like GPT-4V, is more effective than text in managing token limits while retaining critical information. The research also examines the influence of different factors on each encoding modality's performance. This study highlights the current limitations and charts future directions for LLMs in graph understanding and reasoning tasks.
Severity and Mortality Prediction Models to Triage Indian COVID-19 Patients
Sep 02, 2021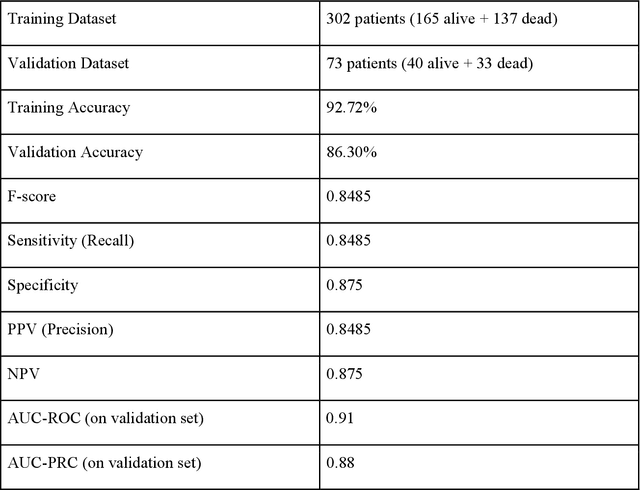
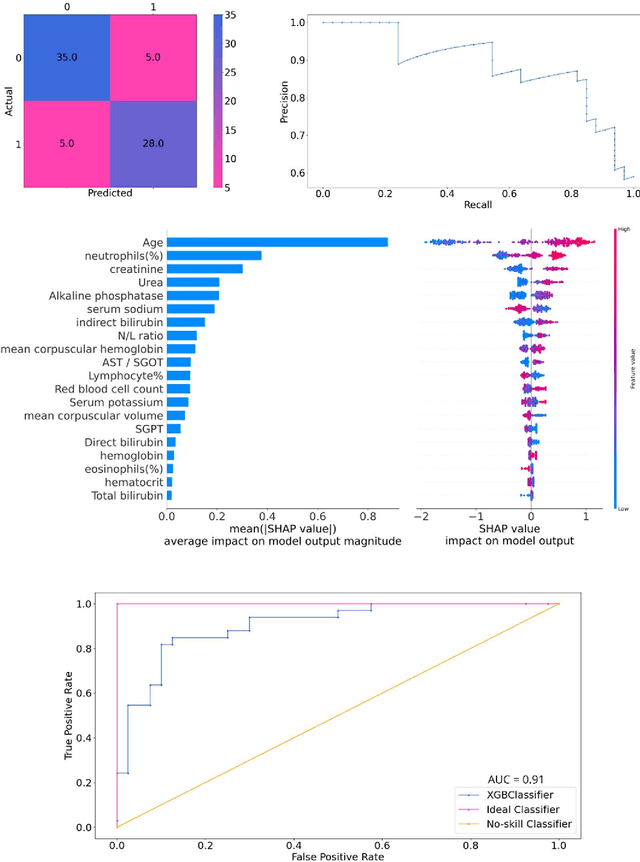
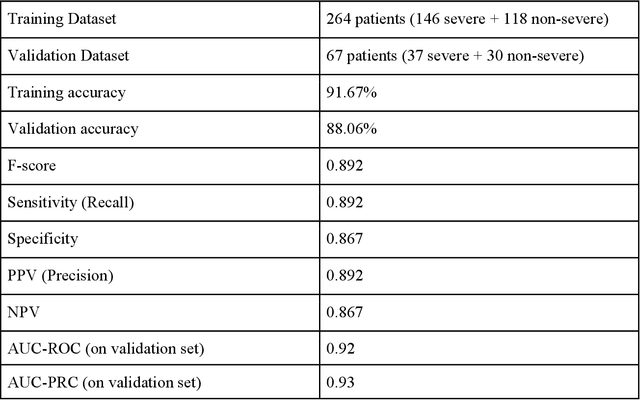
As the second wave in India mitigates, COVID-19 has now infected about 29 million patients countrywide, leading to more than 350 thousand people dead. As the infections surged, the strain on the medical infrastructure in the country became apparent. While the country vaccinates its population, opening up the economy may lead to an increase in infection rates. In this scenario, it is essential to effectively utilize the limited hospital resources by an informed patient triaging system based on clinical parameters. Here, we present two interpretable machine learning models predicting the clinical outcomes, severity, and mortality, of the patients based on routine non-invasive surveillance of blood parameters from one of the largest cohorts of Indian patients at the day of admission. Patient severity and mortality prediction models achieved 86.3% and 88.06% accuracy, respectively, with an AUC-ROC of 0.91 and 0.92. We have integrated both the models in a user-friendly web app calculator, https://triage-COVID-19.herokuapp.com/, to showcase the potential deployment of such efforts at scale.
Challenges in the application of a mortality prediction model for COVID-19 patients on an Indian cohort
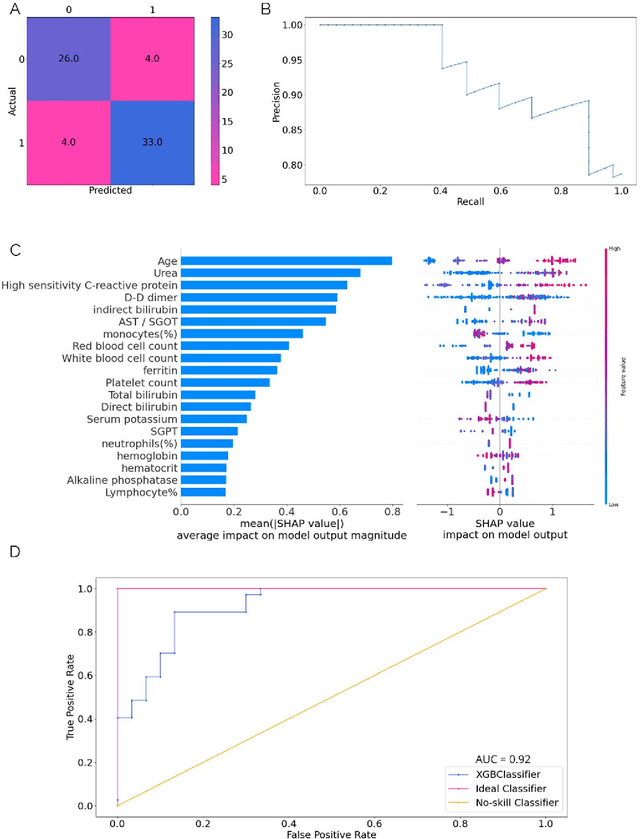
Jan 15, 2021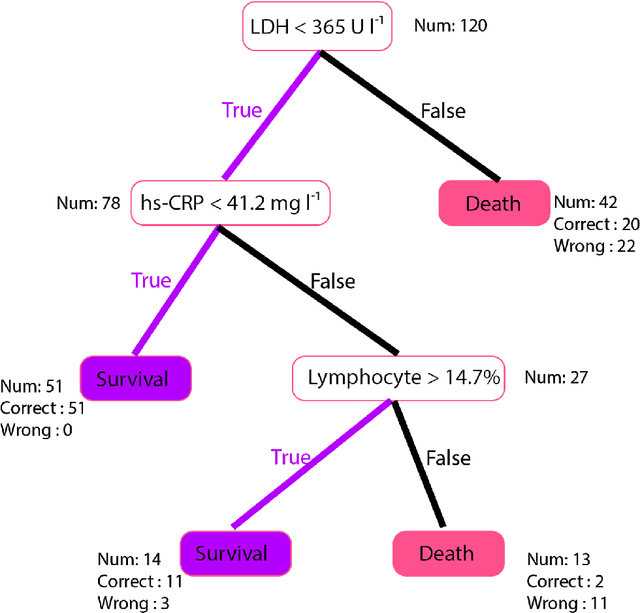
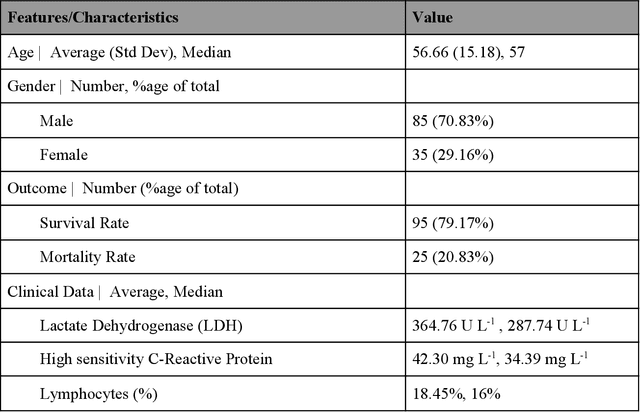
Many countries are now experiencing the third wave of the COVID-19 pandemic straining the healthcare resources with an acute shortage of hospital beds and ventilators for the critically ill patients. This situation is especially worse in India with the second largest load of COVID-19 cases and a relatively resource-scarce medical infrastructure. Therefore, it becomes essential to triage the patients based on the severity of their disease and devote resources towards critically ill patients. Yan et al. 1 have published a very pertinent research that uses Machine learning (ML) methods to predict the outcome of COVID-19 patients based on their clinical parameters at the day of admission. They used the XGBoost algorithm, a type of ensemble model, to build the mortality prediction model. The final classifier is built through the sequential addition of multiple weak classifiers. The clinically operable decision rule was obtained from a 'single-tree XGBoost' and used lactic dehydrogenase (LDH), lymphocyte and high-sensitivity C-reactive protein (hs-CRP) values. This decision tree achieved a 100% survival prediction and 81% mortality prediction. However, these models have several technical challenges and do not provide an out of the box solution that can be deployed for other populations as has been reported in the "Matters Arising" section of Yan et al. Here, we show the limitations of this model by deploying it on one of the largest datasets of COVID-19 patients containing detailed clinical parameters collected from India.