 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Structured Surrogate Loss and Regularization in Structured Prediction
Paper and Code
Sep 14, 2018


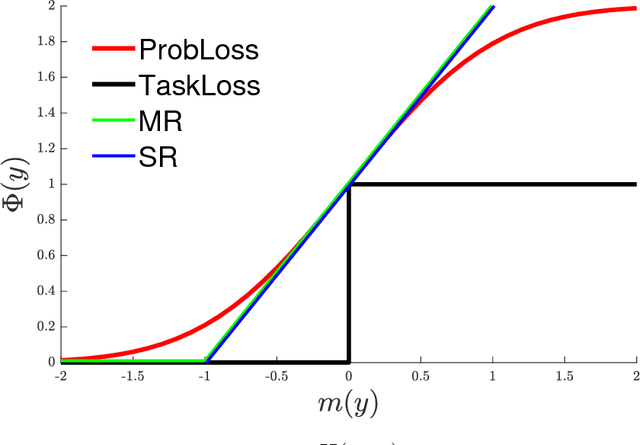
In this dissertation, we focus on several important problems in structured prediction. In structured prediction, the label has a rich intrinsic substructure, and the loss varies with respect to the predicted label and the true label pair. Structured SVM is an extension of binary SVM to adapt to such structured tasks. In the first part of the dissertation, we study the surrogate losses and its efficient methods. To minimize the empirical risk, a surrogate loss which upper bounds the loss, is used as a proxy to minimize the actual loss. Since the objective function is written in terms of the surrogate loss, the choice of the surrogate loss is important, and the performance depends on it. Another issue regarding the surrogate loss is the efficiency of the argmax label inference for the surrogate loss. Efficient inference is necessary for the optimization since it is often the most time-consuming step. We present a new class of surrogate losses named bi-criteria surrogate loss, which is a generalization of the popular surrogate losses. We first investigate an efficient method for a slack rescaling formulation as a starting point utilizing decomposability of the model. Then, we extend the algorithm to the bi-criteria surrogate loss, which is very efficient and also shows performance improvements. In the second part of the dissertation, another important issue of regularization is studied. Specifically, we investigate a problem of regularization in hierarchical classification when a structural imbalance exists in the label structure. We present a method to normalize the structure, as well as a new norm, namely shared Frobenius norm. It is suitable for hierarchical classification that adapts to the data in addition to the label structure.