 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Robust Canine Cardiac Diagnosis: Deep Prototype Alignment Network-Based Few-Shot Segmentation in Veterinary Medicine
Mar 11, 2024In the cutting-edge domain of medical artificial intelligence (AI), remarkable advances have been achieved in areas such as diagnosis, prediction, and therapeutic interventions. Despite these advances, the technology for image segmentation faces the significant barrier of having to produce extensively annotated datasets. To address this challenge, few-shot segmentation (FSS) has been recognized as one of the innovative solutions. Although most of the FSS research has focused on human health care, its application in veterinary medicine, particularly for pet care, remains largely limited. This study has focused on accurate segmentation of the heart and left atrial enlargement on canine chest radiographs using the proposed deep prototype alignment network (DPANet). The PANet architecture is adopted as the backbone model, and experiments are conducted using various encoders based on VGG-19, ResNet-18, and ResNet-50 to extract features. Experimental results demonstrate that the proposed DPANet achieves the highest performance. In the 2way-1shot scenario, it achieves the highest intersection over union (IoU) value of 0.6966, and in the 2way-5shot scenario, it achieves the highest IoU value of 0.797. The DPANet not only signifies a performance improvement, but also shows an improved training speed in the 2way-5shot scenario. These results highlight our model's exceptional capability as a trailblazing solution for segmenting the heart and left atrial enlargement in veterinary applications through FSS, setting a new benchmark in veterinary AI research, and demonstrating its superior potential to veterinary medicine advances.
Generative Active Learning with Variational Autoencoder for Radiology Data Generation in Veterinary Medicine
Mar 06, 2024Recently, with increasing interest in pet healthcare, the demand for computer-aided diagnosis (CAD) systems in veterinary medicine has increased. The development of veterinary CAD has stagnated due to a lack of sufficient radiology data. To overcome the challenge, we propose a generative active learning framework based on a variational autoencoder. This approach aims to alleviate the scarcity of reliable data for CAD systems in veterinary medicine. This study utilizes datasets comprising cardiomegaly radiograph data. After removing annotations and standardizing images, we employed a framework for data augmentation, which consists of a data generation phase and a query phase for filtering the generated data. The experimental results revealed that as the data generated through this framework was added to the training data of the generative model, the frechet inception distance consistently decreased from 84.14 to 50.75 on the radiograph. Subsequently, when the generated data were incorporated into the training of the classification model, the false positive of the confusion matrix also improved from 0.16 to 0.66 on the radiograph. The proposed framework has the potential to address the challenges of data scarcity in medical CAD, contributing to its advancement.
FingerNet: EEG Decoding of A Fine Motor Imagery with Finger-tapping Task Based on A Deep Neural Network
Mar 06, 2024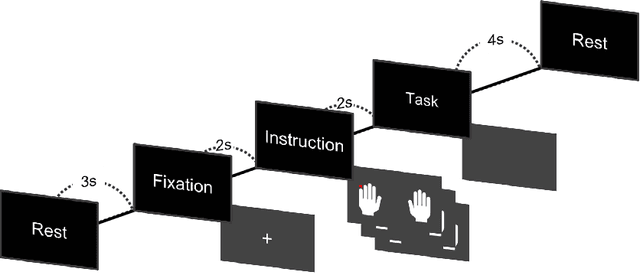
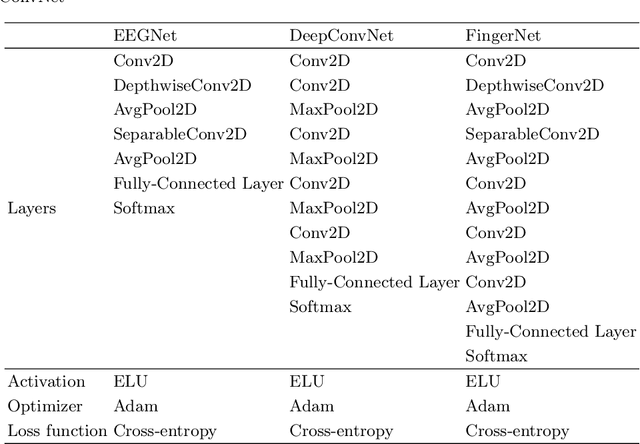

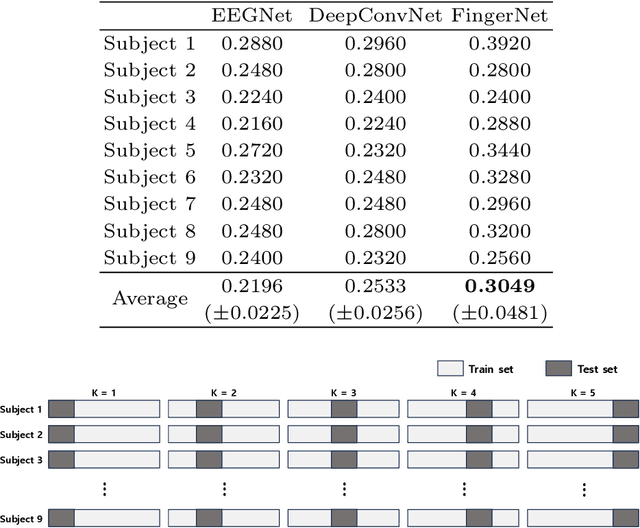
Brain-computer interface (BCI) technology facilitates communication between the human brain and computers, primarily utilizing electroencephalography (EEG) signals to discern human intentions. Although EEG-based BCI systems have been developed for paralysis individuals, ongoing studies explore systems for speech imagery and motor imagery (MI). This study introduces FingerNet, a specialized network for fine MI classification, departing from conventional gross MI studies. The proposed FingerNet could extract spatial and temporal features from EEG signals, improving classification accuracy within the same hand. The experimental results demonstrated that performance showed significantly higher accuracy in classifying five finger-tapping tasks, encompassing thumb, index, middle, ring, and little finger movements. FingerNet demonstrated dominant performance compared to the conventional baseline models, EEGNet and DeepConvNet. The average accuracy for FingerNet was 0.3049, whereas EEGNet and DeepConvNet exhibited lower accuracies of 0.2196 and 0.2533, respectively. Statistical validation also demonstrates the predominance of FingerNet over baseline networks. For biased predictions, particularly for thumb and index classes, we led to the implementation of weighted cross-entropy and also adapted the weighted cross-entropy, a method conventionally employed to mitigate class imbalance. The proposed FingerNet involves optimizing network structure, improving performance, and exploring applications beyond fine MI. Moreover, the weighted Cross Entropy approach employed to address such biased predictions appears to have broader applicability and relevance across various domains involving multi-class classification tasks. We believe that effective execution of motor imagery can be achieved not only for fine MI, but also for local muscle MI
DeepHealthNet: Adolescent Obesity Prediction System Based on a Deep Learning Framework
Aug 31, 2023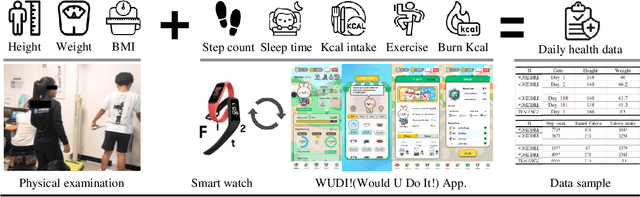
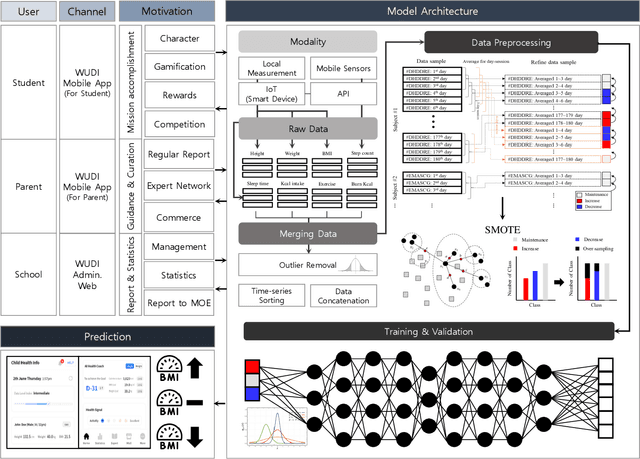

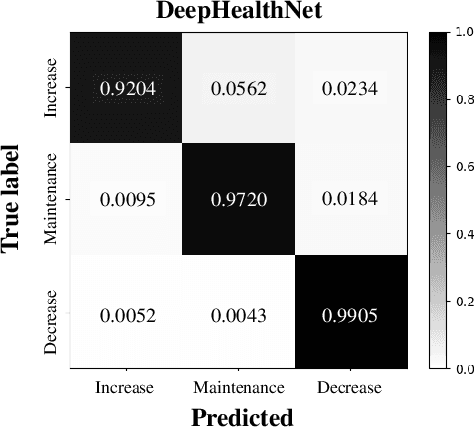
Childhood and adolescent obesity rates are a global concern because obesity is associated with chronic diseases and long-term health risks. Artificial intelligence technology has emerged as a promising solution to accurately predict obesity rates and provide personalized feedback to adolescents. This study emphasizes the importance of early identification and prevention of obesity-related health issues. Factors such as height, weight, waist circumference, calorie intake, physical activity levels, and other relevant health information need to be considered for developing robust algorithms for obesity rate prediction and delivering personalized feedback. Hence, by collecting health datasets from 321 adolescents, we proposed an adolescent obesity prediction system that provides personalized predictions and assists individuals in making informed health decisions. Our proposed deep learning framework, DeepHealthNet, effectively trains the model using data augmentation techniques, even when daily health data are limited, resulting in improved prediction accuracy (acc: 0.8842). Additionally, the study revealed variations in the prediction of the obesity rate between boys (acc: 0.9320) and girls (acc: 0.9163), allowing the identification of disparities and the determination of the optimal time to provide feedback. The proposed system shows significant potential in effectively addressing childhood and adolescent obesity.
Prototype-based Domain Generalization Framework for Subject-Independent Brain-Computer Interfaces
Apr 15, 2022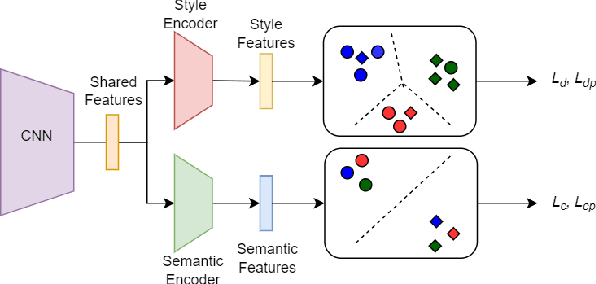
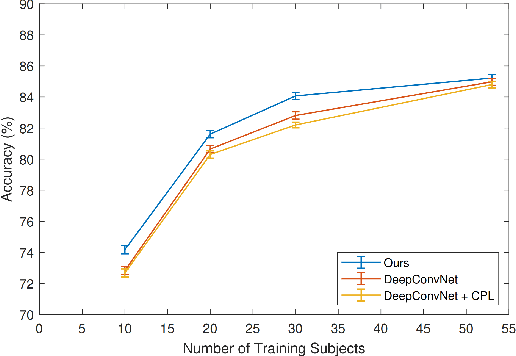
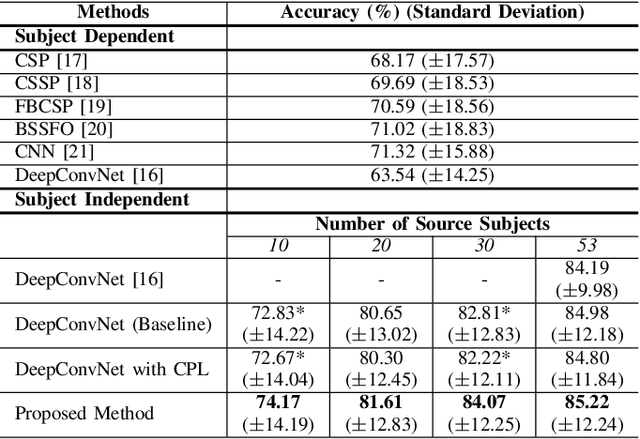
Brain-computer interface (BCI) is challenging to use in practice due to the inter/intra-subject variability of electroencephalography (EEG). The BCI system, in general, necessitates a calibration technique to obtain subject/session-specific data in order to tune the model each time the system is utilized. This issue is acknowledged as a key hindrance to BCI, and a new strategy based on domain generalization has recently evolved to address it. In light of this, we've concentrated on developing an EEG classification framework that can be applied directly to data from unknown domains (i.e. subjects), using only data acquired from separate subjects previously. For this purpose, in this paper, we proposed a framework that employs the open-set recognition technique as an auxiliary task to learn subject-specific style features from the source dataset while helping the shared feature extractor with mapping the features of the unseen target dataset as a new unseen domain. Our aim is to impose cross-instance style in-variance in the same domain and reduce the open space risk on the potential unseen subject in order to improve the generalization ability of the shared feature extractor. Our experiments showed that using the domain information as an auxiliary network increases the generalization performance.
Towards Natural Brain-Machine Interaction using Endogenous Potentials based on Deep Neural Networks
Jun 25, 2021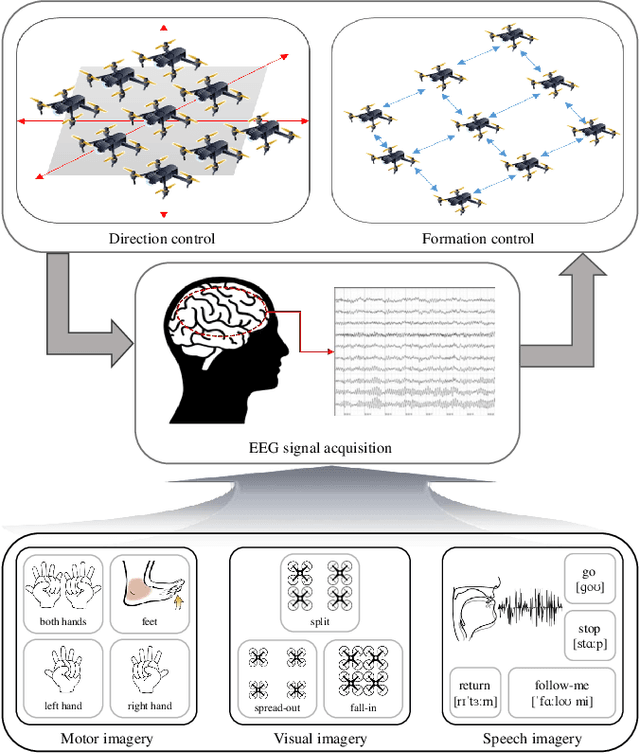
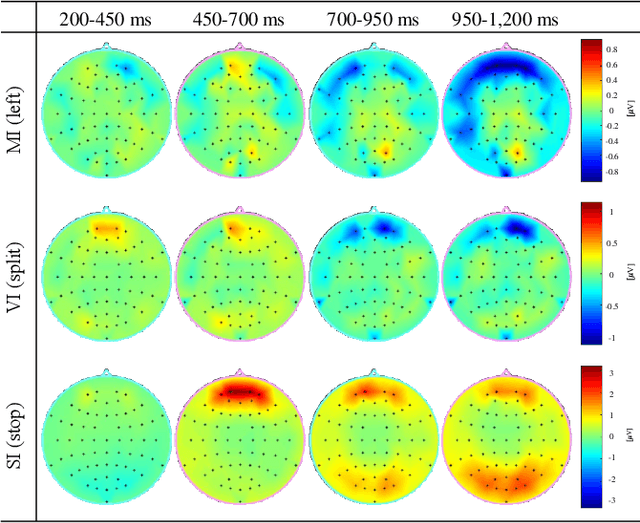
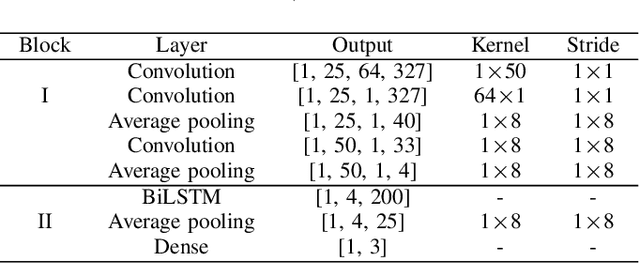
Human-robot collaboration has the potential to maximize the efficiency of the operation of autonomous robots. Brain-machine interface (BMI) would be a desirable technology to collaborate with robots since the intention or state of users can be translated from the neural activities. However, the electroencephalogram (EEG), which is one of the most popularly used non-invasive BMI modalities, has low accuracy and a limited degree of freedom (DoF) due to a low signal-to-noise ratio. Thus, improving the performance of multi-class EEG classification is crucial to develop more flexible BMI-based human-robot collaboration. In this study, we investigated the possibility for inter-paradigm classification of multiple endogenous BMI paradigms, such as motor imagery (MI), visual imagery (VI), and speech imagery (SI), to enhance the limited DoF while maintaining robust accuracy. We conducted the statistical and neurophysiological analyses on MI, VI, and SI and classified three paradigms using the proposed temporal information-based neural network (TINN). We confirmed that statistically significant features could be extracted on different brain regions when classifying three endogenous paradigms. Moreover, our proposed TINN showed the highest accuracy of 0.93 compared to the previous methods for classifying three different types of mental imagery tasks (MI, VI, and SI).
Subject-Independent Brain-Computer Interface for Decoding High-Level Visual Imagery Tasks
Jun 08, 2021
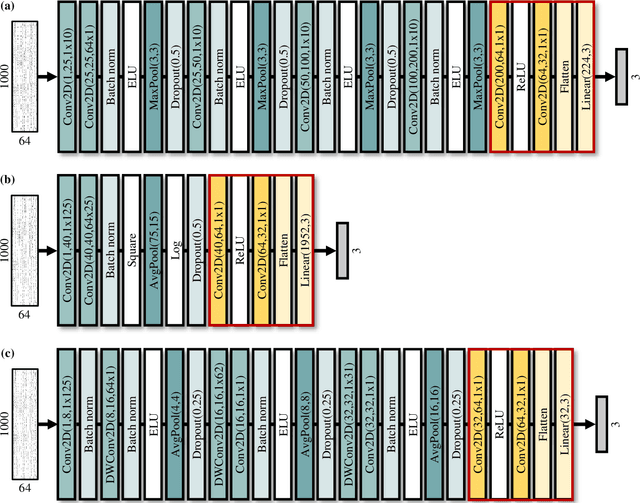
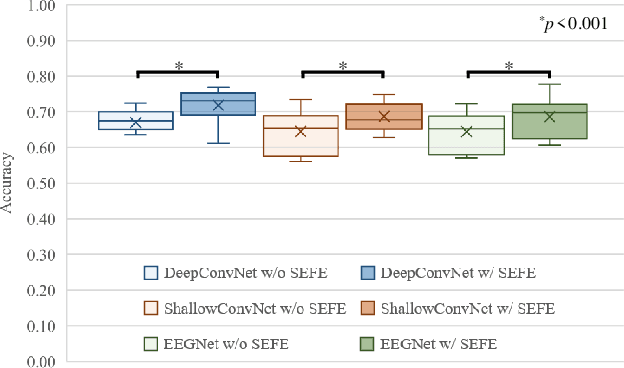
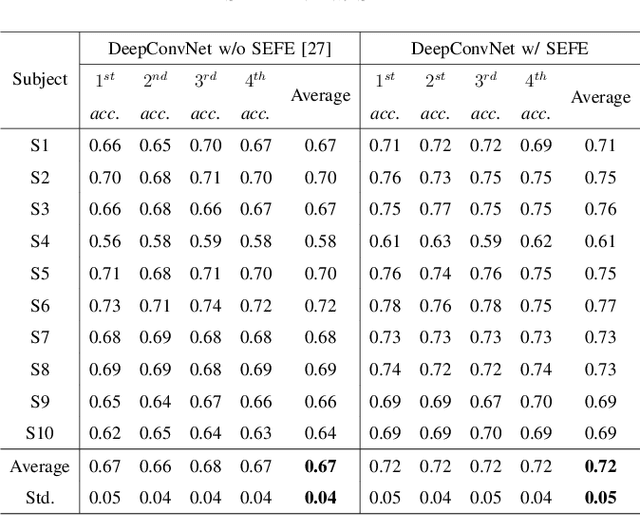
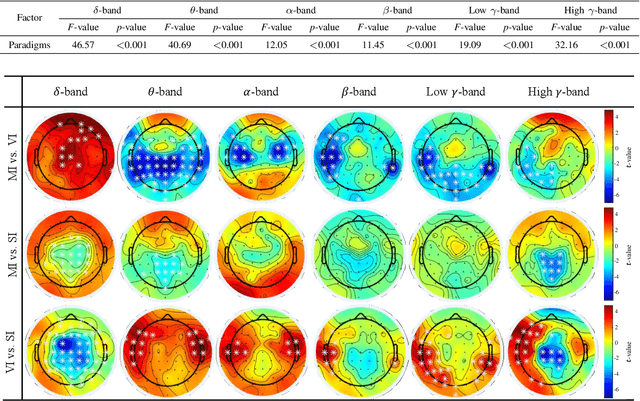
Brain-computer interface (BCI) is used for communication between humans and devices by recognizing status and intention of humans. Communication between humans and a drone using electroencephalogram (EEG) signals is one of the most challenging issues in the BCI domain. In particular, the control of drone swarms (the direction and formation) has more advantages compared to the control of a drone. The visual imagery (VI) paradigm is that subjects visually imagine specific objects or scenes. Reduction of the variability among EEG signals of subjects is essential for practical BCI-based systems. In this study, we proposed the subepoch-wise feature encoder (SEFE) to improve the performances in the subject-independent tasks by using the VI dataset. This study is the first attempt to demonstrate the possibility of generalization among subjects in the VI-based BCI. We used the leave-one-subject-out cross-validation for evaluating the performances. We obtained higher performances when including our proposed module than excluding our proposed module. The DeepConvNet with SEFE showed the highest performance of 0.72 among six different decoding models. Hence, we demonstrated the feasibility of decoding the VI dataset in the subject-independent task with robust performances by using our proposed module.
Decoding of Intuitive Visual Motion Imagery Using Convolutional Neural Network under 3D-BCI Training Environment
May 15, 2020
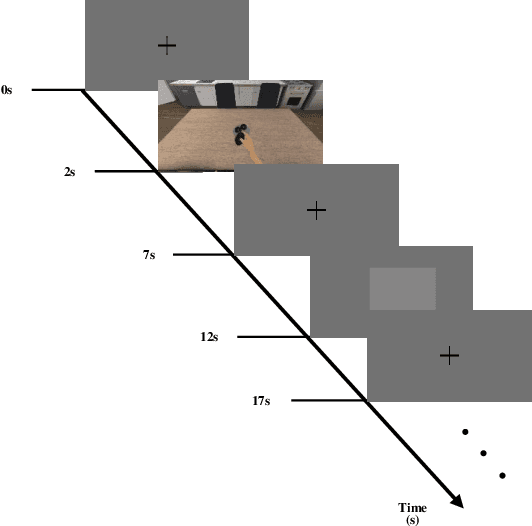
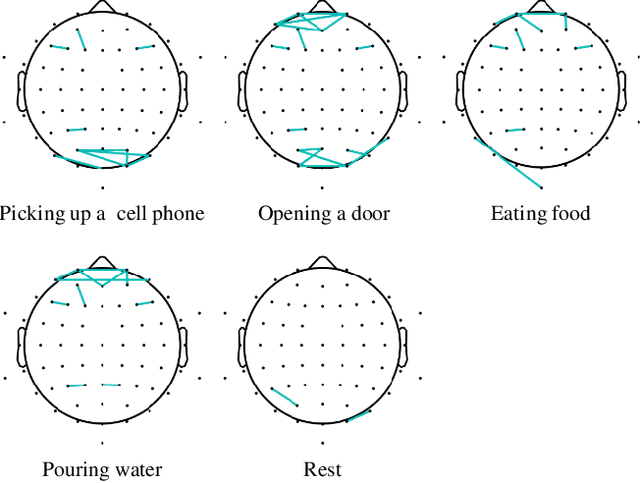
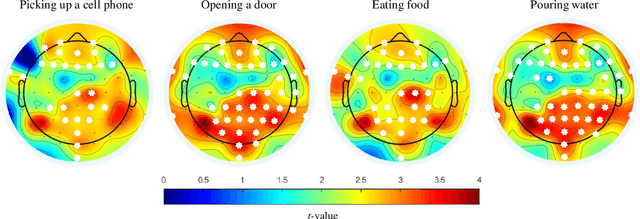
In this study, we adopted visual motion imagery, which is a more intuitive brain-computer interface (BCI) paradigm, for decoding the intuitive user intention. We developed a 3-dimensional BCI training platform and applied it to assist the user in performing more intuitive imagination in the visual motion imagery experiment. The experimental tasks were selected based on the movements that we commonly used in daily life, such as picking up a phone, opening a door, eating food, and pouring water. Nine subjects participated in our experiment. We presented statistical evidence that visual motion imagery has a high correlation from the prefrontal and occipital lobes. In addition, we selected the most appropriate electroencephalography channels using a functional connectivity approach for visual motion imagery decoding and proposed a convolutional neural network architecture for classification. As a result, the averaged classification performance of the proposed architecture for 4 classes from 16 channels was 67.50 % across all subjects. This result is encouraging, and it shows the possibility of developing a BCI-based device control system for practical applications such as neuroprosthesis and a robotic arm.
Gradual Relation Network: Decoding Intuitive Upper Extremity Movement Imaginations Based on Few-Shot EEG Learning
May 06, 2020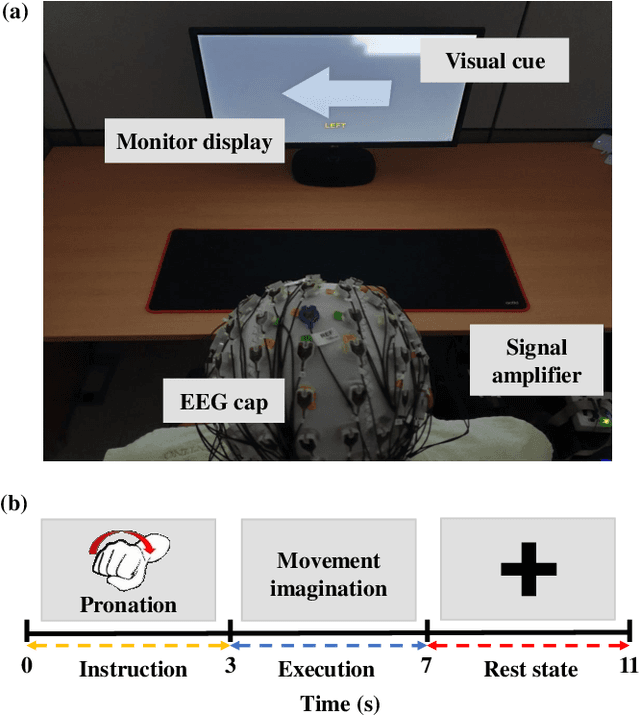
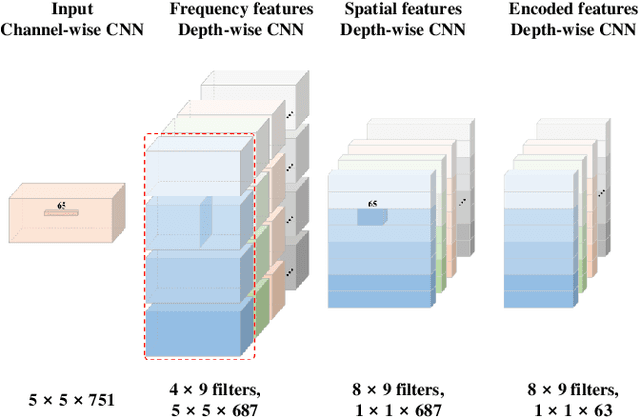
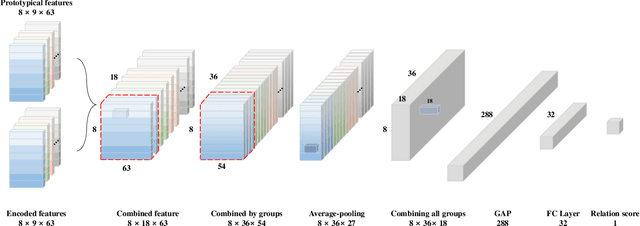
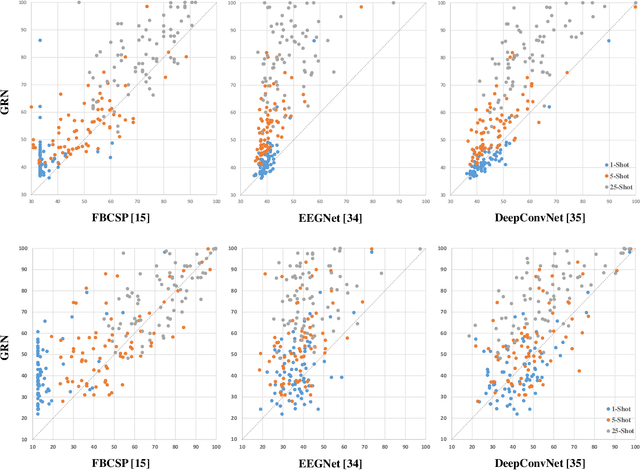
Brain-computer interface (BCI) is a communication tool that connects users and external devices. In a real-time BCI environment, a calibration procedure is particularly necessary for each user and each session. This procedure consumes a significant amount of time that hinders the application of a BCI system in a real-world scenario. To avoid this problem, we adopt the metric based few-shot learning approach for decoding intuitive upper-extremity movement imagination (MI) using a gradual relation network (GRN) that can gradually consider the combination of temporal and spectral groups. We acquired the MI data of the upper-arm, forearm, and hand associated with intuitive upper-extremity movement from 25 subjects. The grand average multiclass classification results under offline analysis were 42.57%, 55.60%, and 80.85% in 1-, 5-, and 25-shot settings, respectively. In addition, we could demonstrate the feasibility of intuitive MI decoding using the few-shot approach in real-time robotic arm control scenarios. Five participants could achieve a success rate of 78% in the drinking task. Hence, we demonstrated the feasibility of the online robotic arm control with shortened calibration time by focusing on human body parts but also the accommodation of various untrained intuitive MI decoding based on the proposed GRN.
Classification of High-Dimensional Motor Imagery Tasks based on An End-to-end role assigned convolutional neural network
Feb 04, 2020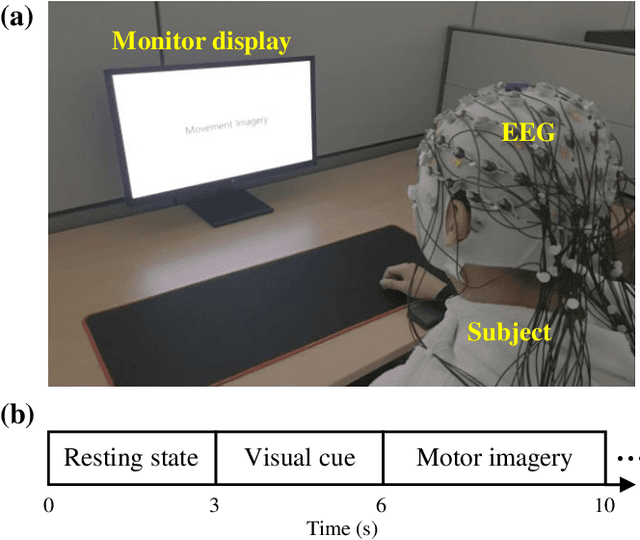
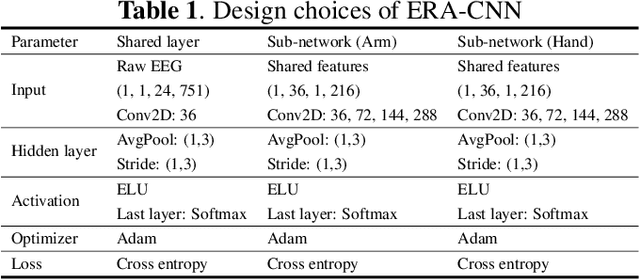
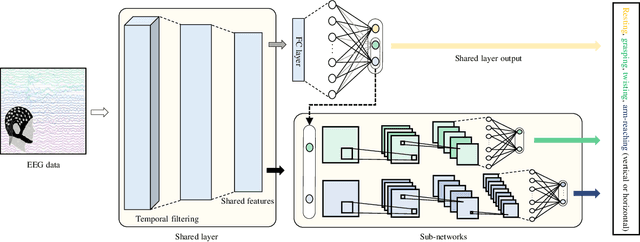
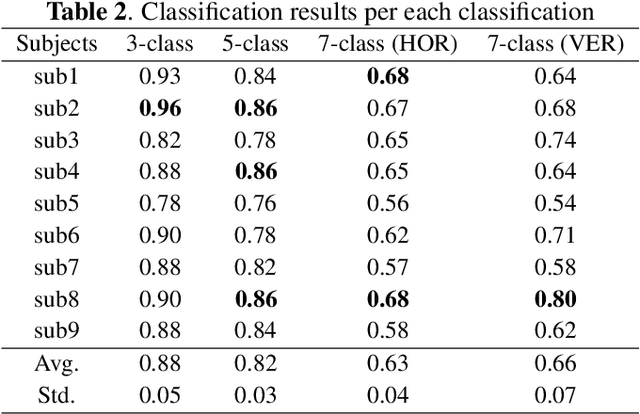
A brain-computer interface (BCI) provides a direct communication pathway between user and external devices. Electroencephalogram (EEG) motor imagery (MI) paradigm is widely used in non-invasive BCI to obtain encoded signals contained user intention of movement execution. However, EEG has intricate and non-stationary properties resulting in insufficient decoding performance. By imagining numerous movements of a single-arm, decoding performance can be improved without artificial command matching. In this study, we collected intuitive EEG data contained the nine different types of movements of a single-arm from 9 subjects. We propose an end-to-end role assigned convolutional neural network (ERA-CNN) which considers discriminative features of each upper limb region by adopting the principle of a hierarchical CNN architecture. The proposed model outperforms previous methods on 3-class, 5-class and two different types of 7-class classification tasks. Hence, we demonstrate the possibility of decoding user intention by using only EEG signals with robust performance using an ERA-CNN.