 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubject-Independent Brain-Computer Interfaces with Open-Set Subject Recognition
Jan 19, 2023A brain-computer interface (BCI) can't be effectively used since electroencephalography (EEG) varies between and within subjects. BCI systems require calibration steps to adjust the model to subject-specific data. It is widely acknowledged that this is a major obstacle to the development of BCIs. To address this issue, previous studies have trained a generalized model by removing the subjects' information. In contrast, in this work, we introduce a style information encoder as an auxiliary task that classifies various source domains and recognizes open-set domains. Open-set recognition method was used as an auxiliary task to learn subject-related style information from the source subjects, while at the same time helping the shared feature extractor map features in an unseen target. This paper compares various OSR methods within an open-set subject recognition (OSSR) framework. As a result of our experiments, we found that the OSSR auxiliary network that encodes domain information improves generalization performance.
Calibration-Free Driver Drowsiness Classification based on Manifold-Level Augmentation
Dec 14, 2022


Drowsiness reduces concentration and increases response time, which causes fatal road accidents. Monitoring drivers' drowsiness levels by electroencephalogram (EEG) and taking action may prevent road accidents. EEG signals effectively monitor the driver's mental state as they can monitor brain dynamics. However, calibration is required in advance because EEG signals vary between and within subjects. Because of the inconvenience, calibration has reduced the accessibility of the brain-computer interface (BCI). Developing a generalized classification model is similar to domain generalization, which overcomes the domain shift problem. Especially data augmentation is frequently used. This paper proposes a calibration-free framework for driver drowsiness state classification using manifold-level augmentation. This framework increases the diversity of source domains by utilizing features. We experimented with various augmentation methods to improve the generalization performance. Based on the results of the experiments, we found that deeper models with smaller kernel sizes improved generalizability. In addition, applying an augmentation at the manifold-level resulted in an outstanding improvement. The framework demonstrated the capability for calibration-free BCI.
Prototype-based Domain Generalization Framework for Subject-Independent Brain-Computer Interfaces
Apr 15, 2022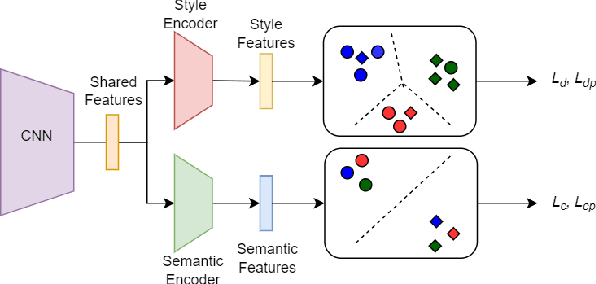
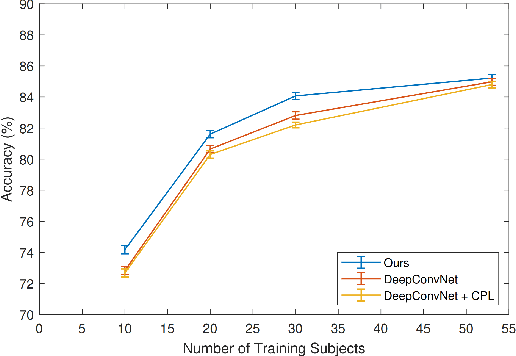
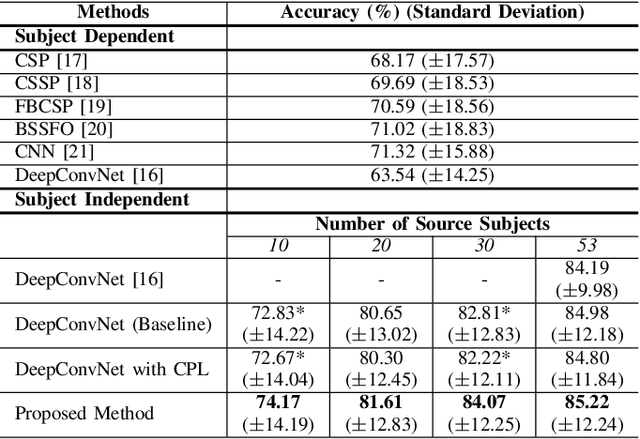
Brain-computer interface (BCI) is challenging to use in practice due to the inter/intra-subject variability of electroencephalography (EEG). The BCI system, in general, necessitates a calibration technique to obtain subject/session-specific data in order to tune the model each time the system is utilized. This issue is acknowledged as a key hindrance to BCI, and a new strategy based on domain generalization has recently evolved to address it. In light of this, we've concentrated on developing an EEG classification framework that can be applied directly to data from unknown domains (i.e. subjects), using only data acquired from separate subjects previously. For this purpose, in this paper, we proposed a framework that employs the open-set recognition technique as an auxiliary task to learn subject-specific style features from the source dataset while helping the shared feature extractor with mapping the features of the unseen target dataset as a new unseen domain. Our aim is to impose cross-instance style in-variance in the same domain and reduce the open space risk on the potential unseen subject in order to improve the generalization ability of the shared feature extractor. Our experiments showed that using the domain information as an auxiliary network increases the generalization performance.
Confidence-Aware Subject-to-Subject Transfer Learning for Brain-Computer Interface
Dec 15, 2021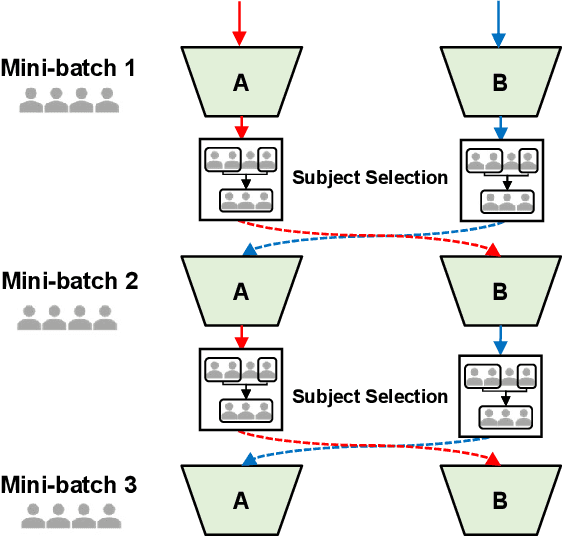

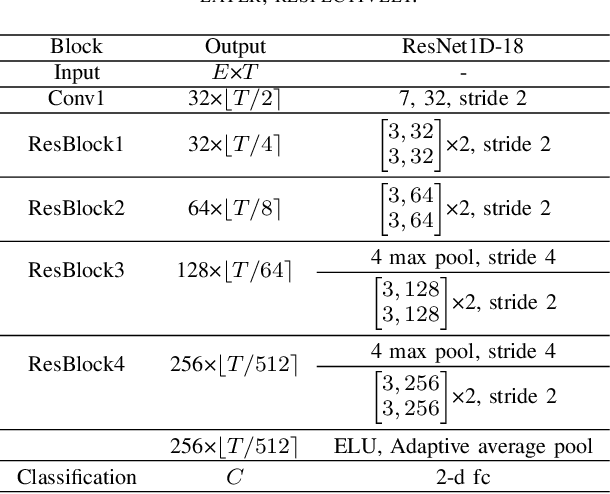
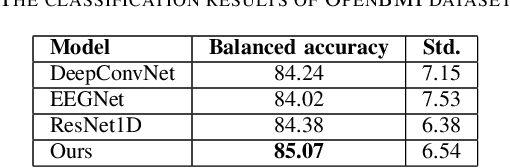
The inter/intra-subject variability of electroencephalography (EEG) makes the practical use of the brain-computer interface (BCI) difficult. In general, the BCI system requires a calibration procedure to tune the model every time the system is used. This problem is recognized as a major obstacle to BCI, and to overcome it, approaches based on transfer learning (TL) have recently emerged. However, many BCI paradigms are limited in that they consist of a structure that shows labels first and then measures "imagery", the negative effects of source subjects containing data that do not contain control signals have been ignored in many cases of the subject-to-subject TL process. The main purpose of this paper is to propose a method of excluding subjects that are expected to have a negative impact on subject-to-subject TL training, which generally uses data from as many subjects as possible. In this paper, we proposed a BCI framework using only high-confidence subjects for TL training. In our framework, a deep neural network selects useful subjects for the TL process and excludes noisy subjects, using a co-teaching algorithm based on the small-loss trick. We experimented with leave-one-subject-out validation on two public datasets (2020 international BCI competition track 4 and OpenBMI dataset). Our experimental results showed that confidence-aware TL, which selects subjects with small loss instances, improves the generalization performance of BCI.
Subject-Independent Brain-Computer Interface for Decoding High-Level Visual Imagery Tasks
Jun 08, 2021
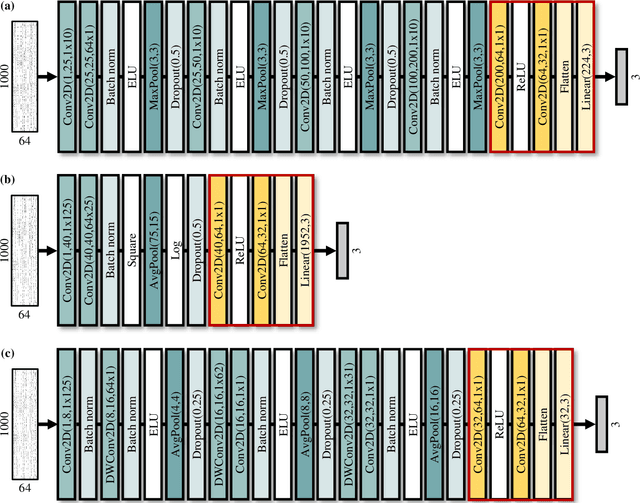
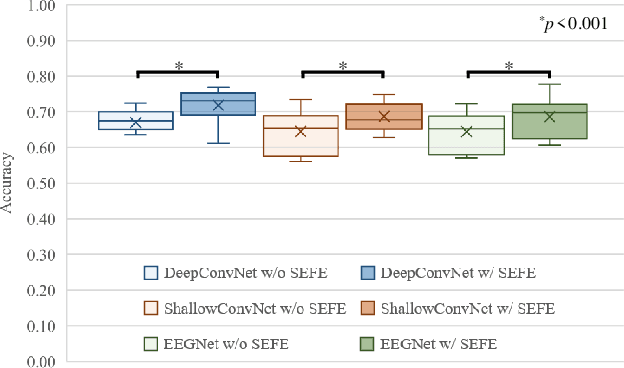
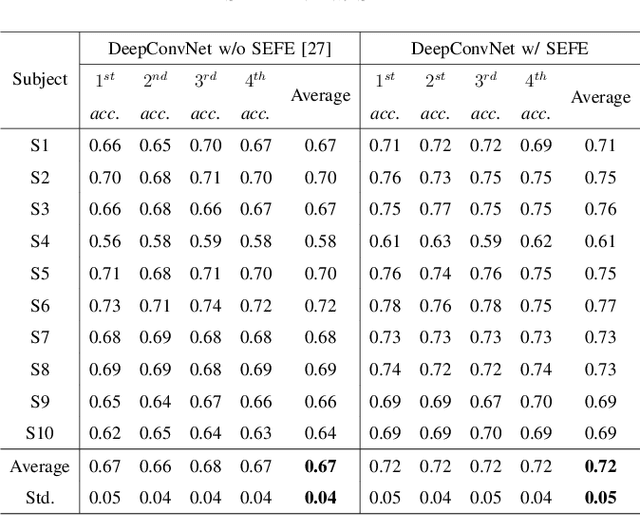
Brain-computer interface (BCI) is used for communication between humans and devices by recognizing status and intention of humans. Communication between humans and a drone using electroencephalogram (EEG) signals is one of the most challenging issues in the BCI domain. In particular, the control of drone swarms (the direction and formation) has more advantages compared to the control of a drone. The visual imagery (VI) paradigm is that subjects visually imagine specific objects or scenes. Reduction of the variability among EEG signals of subjects is essential for practical BCI-based systems. In this study, we proposed the subepoch-wise feature encoder (SEFE) to improve the performances in the subject-independent tasks by using the VI dataset. This study is the first attempt to demonstrate the possibility of generalization among subjects in the VI-based BCI. We used the leave-one-subject-out cross-validation for evaluating the performances. We obtained higher performances when including our proposed module than excluding our proposed module. The DeepConvNet with SEFE showed the highest performance of 0.72 among six different decoding models. Hence, we demonstrated the feasibility of decoding the VI dataset in the subject-independent task with robust performances by using our proposed module.