 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaDE: Improving Sparse Representations using a Dual Document Encoder for First-stage Retrieval
Sep 13, 2022
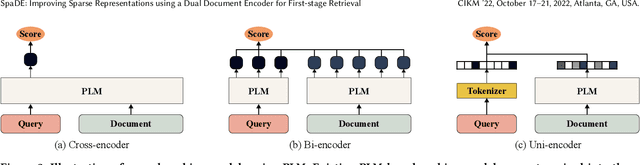
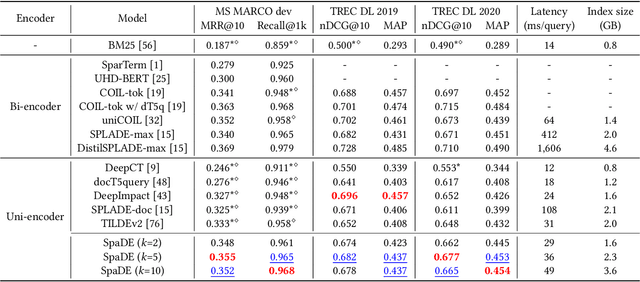
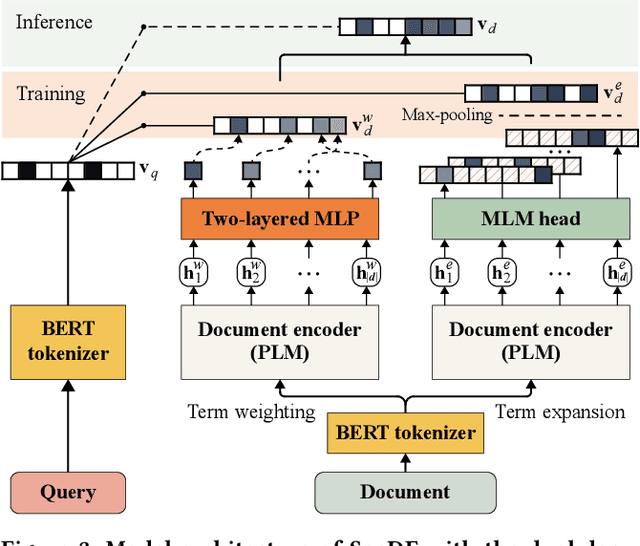
Sparse document representations have been widely used to retrieve relevant documents via exact lexical matching. Owing to the pre-computed inverted index, it supports fast ad-hoc search but incurs the vocabulary mismatch problem. Although recent neural ranking models using pre-trained language models can address this problem, they usually require expensive query inference costs, implying the trade-off between effectiveness and efficiency. Tackling the trade-off, we propose a novel uni-encoder ranking model, Sparse retriever using a Dual document Encoder (SpaDE), learning document representation via the dual encoder. Each encoder plays a central role in (i) adjusting the importance of terms to improve lexical matching and (ii) expanding additional terms to support semantic matching. Furthermore, our co-training strategy trains the dual encoder effectively and avoids unnecessary intervention in training each other. Experimental results on several benchmarks show that SpaDE outperforms existing uni-encoder ranking models.