 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Homogeneous Modality Learning and Multi-Granularity Information Exploration for Visible-Infrared Person Re-Identification
Apr 11, 2022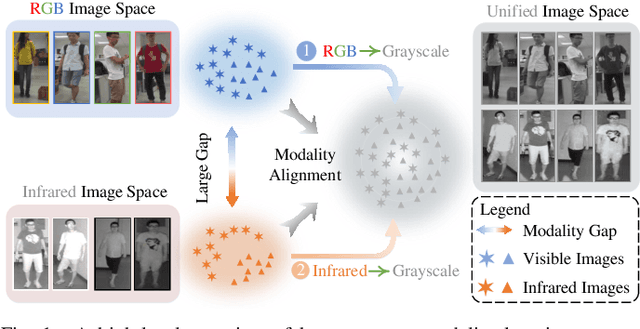

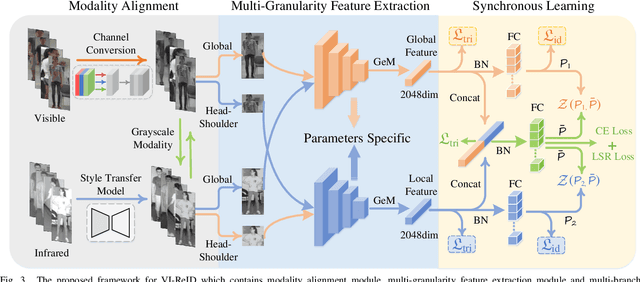

Visible-infrared person re-identification (VI-ReID) is a challenging and essential task, which aims to retrieve a set of person images over visible and infrared camera views. In order to mitigate the impact of large modality discrepancy existing in heterogeneous images, previous methods attempt to apply generative adversarial network (GAN) to generate the modality-consisitent data. However, due to severe color variations between the visible domain and infrared domain, the generated fake cross-modality samples often fail to possess good qualities to fill the modality gap between synthesized scenarios and target real ones, which leads to sub-optimal feature representations. In this work, we address cross-modality matching problem with Aligned Grayscale Modality (AGM), an unified dark-line spectrum that reformulates visible-infrared dual-mode learning as a gray-gray single-mode learning problem. Specifically, we generate the grasycale modality from the homogeneous visible images. Then, we train a style tranfer model to transfer infrared images into homogeneous grayscale images. In this way, the modality discrepancy is significantly reduced in the image space. In order to reduce the remaining appearance discrepancy, we further introduce a multi-granularity feature extraction network to conduct feature-level alignment. Rather than relying on the global information, we propose to exploit local (head-shoulder) features to assist person Re-ID, which complements each other to form a stronger feature descriptor. Comprehensive experiments implemented on the mainstream evaluation datasets include SYSU-MM01 and RegDB indicate that our method can significantly boost cross-modality retrieval performance against the state of the art methods.
SFANet: A Spectrum-aware Feature Augmentation Network for Visible-Infrared Person Re-Identification
Feb 24, 2021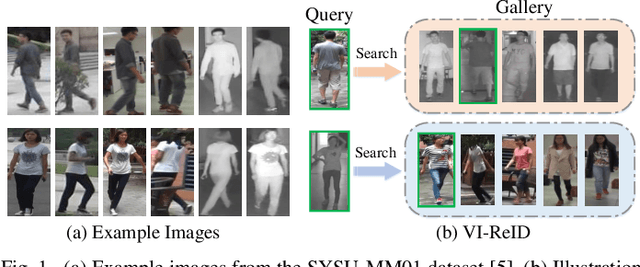
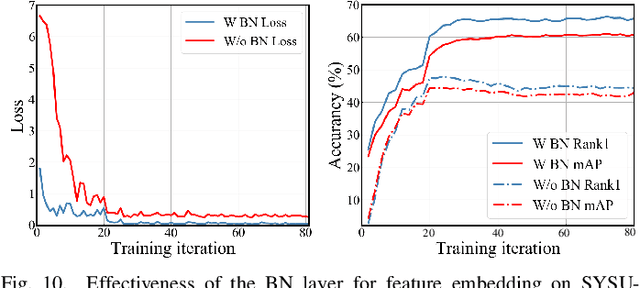

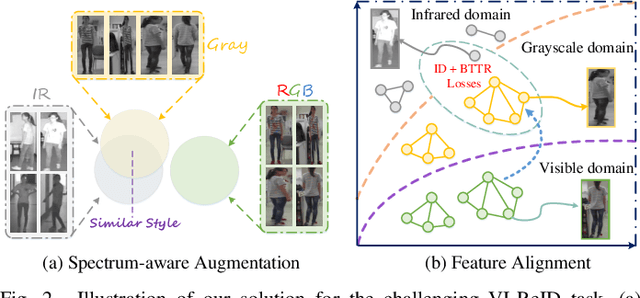
Visible-Infrared person re-identification (VI-ReID) is a challenging matching problem due to large modality varitions between visible and infrared images. Existing approaches usually bridge the modality gap with only feature-level constraints, ignoring pixel-level variations. Some methods employ GAN to generate style-consistent images, but it destroys the structure information and incurs a considerable level of noise. In this paper, we explicitly consider these challenges and formulate a novel spectrum-aware feature augementation network named SFANet for cross-modality matching problem. Specifically, we put forward to employ grayscale-spectrum images to fully replace RGB images for feature learning. Learning with the grayscale-spectrum images, our model can apparently reduce modality discrepancy and detect inner structure relations across the different modalities, making it robust to color variations. In feature-level, we improve the conventional two-stream network through balancing the number of specific and sharable convolutional blocks, which preserve the spatial structure information of features. Additionally, a bi-directional tri-constrained top-push ranking loss (BTTR) is embedded in the proposed network to improve the discriminability, which efficiently further boosts the matching accuracy. Meanwhile, we further introduce an effective dual-linear with batch normalization ID embedding method to model the identity-specific information and assits BTTR loss in magnitude stabilizing. On SYSU-MM01 and RegDB datasets, we conducted extensively experiments to demonstrate that our proposed framework contributes indispensably and achieves a very competitive VI-ReID performance.