 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPPN: Future Pseudo-LiDAR Frame Prediction for Autonomous Driving
Paper and Code
Dec 08, 2021
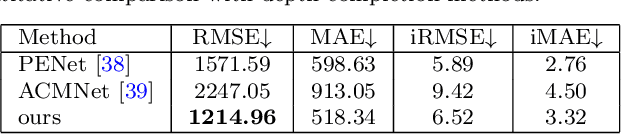


LiDAR sensors are widely used in autonomous driving due to the reliable 3D spatial information. However, the data of LiDAR is sparse and the frequency of LiDAR is lower than that of cameras. To generate denser point clouds spatially and temporally, we propose the first future pseudo-LiDAR frame prediction network. Given the consecutive sparse depth maps and RGB images, we first predict a future dense depth map based on dynamic motion information coarsely. To eliminate the errors of optical flow estimation, an inter-frame aggregation module is proposed to fuse the warped depth maps with adaptive weights. Then, we refine the predicted dense depth map using static contextual information. The future pseudo-LiDAR frame can be obtained by converting the predicted dense depth map into corresponding 3D point clouds. Experimental results show that our method outperforms the existing solutions on the popular KITTI benchmark.