 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline identification of nonlinear time-varying systems with uncertain information
Jan 15, 2026Digital twins (DTs), serving as the core enablers for real-time monitoring and predictive maintenance of complex cyber-physical systems, impose critical requirements on their virtual models: high predictive accuracy, strong interpretability, and online adaptive capability. However, existing techniques struggle to meet these demands simultaneously: Bayesian methods excel in uncertainty quantification but lack model interpretability, while interpretable symbolic identification methods (e.g., SINDy) are constrained by their offline, batch-processing nature, which make real-time updates challenging. To bridge this semantic and computational gap, this paper proposes a novel Bayesian Regression-based Symbolic Learning (BRSL) framework. The framework formulates online symbolic discovery as a unified probabilistic state-space model. By incorporating sparse horseshoe priors, model selection is transformed into a Bayesian inference task, enabling simultaneous system identification and uncertainty quantification. Furthermore, we derive an online recursive algorithm with a forgetting factor and establish precise recursive conditions that guarantee the well-posedness of the posterior distribution. These conditions also function as real-time monitors for data utility, enhancing algorithmic robustness. Additionally, a rigorous convergence analysis is provided, demonstrating the convergence of parameter estimates under persistent excitation conditions. Case studies validate the effectiveness of the proposed framework in achieving interpretable, probabilistic prediction and online learning.
PARL: Position-Aware Relation Learning Network for Document Layout Analysis
Jan 12, 2026Document layout analysis aims to detect and categorize structural elements (e.g., titles, tables, figures) in scanned or digital documents. Popular methods often rely on high-quality Optical Character Recognition (OCR) to merge visual features with extracted text. This dependency introduces two major drawbacks: propagation of text recognition errors and substantial computational overhead, limiting the robustness and practical applicability of multimodal approaches. In contrast to the prevailing multimodal trend, we argue that effective layout analysis depends not on text-visual fusion, but on a deep understanding of documents' intrinsic visual structure. To this end, we propose PARL (Position-Aware Relation Learning Network), a novel OCR-free, vision-only framework that models layout through positional sensitivity and relational structure. Specifically, we first introduce a Bidirectional Spatial Position-Guided Deformable Attention module to embed explicit positional dependencies among layout elements directly into visual features. Second, we design a Graph Refinement Classifier (GRC) to refine predictions by modeling contextual relationships through a dynamically constructed layout graph. Extensive experiments show PARL achieves state-of-the-art results. It establishes a new benchmark for vision-only methods on DocLayNet and, notably, surpasses even strong multimodal models on M6Doc. Crucially, PARL (65M) is highly efficient, using roughly four times fewer parameters than large multimodal models (256M), demonstrating that sophisticated visual structure modeling can be both more efficient and robust than multimodal fusion.
FocalOrder: Focal Preference Optimization for Reading Order Detection
Jan 12, 2026Reading order detection is the foundation of document understanding. Most existing methods rely on uniform supervision, implicitly assuming a constant difficulty distribution across layout regions. In this work, we challenge this assumption by revealing a critical flaw: \textbf{Positional Disparity}, a phenomenon where models demonstrate mastery over the deterministic start and end regions but suffer a performance collapse in the complex intermediate sections. This degradation arises because standard training allows the massive volume of easy patterns to drown out the learning signals from difficult layouts. To address this, we propose \textbf{FocalOrder}, a framework driven by \textbf{Focal Preference Optimization (FPO)}. Specifically, FocalOrder employs adaptive difficulty discovery with exponential moving average mechanism to dynamically pinpoint hard-to-learn transitions, while introducing a difficulty-calibrated pairwise ranking objective to enforce global logical consistency. Extensive experiments demonstrate that FocalOrder establishes new state-of-the-art results on OmniDocBench v1.0 and Comp-HRDoc. Our compact model not only outperforms competitive specialized baselines but also significantly surpasses large-scale general VLMs. These results demonstrate that aligning the optimization with intrinsic structural ambiguity of documents is critical for mastering complex document structures.
Semi-supervised Optimal Transport with Self-paced Ensemble for Cross-hospital Sepsis Early Detection
Jun 18, 2021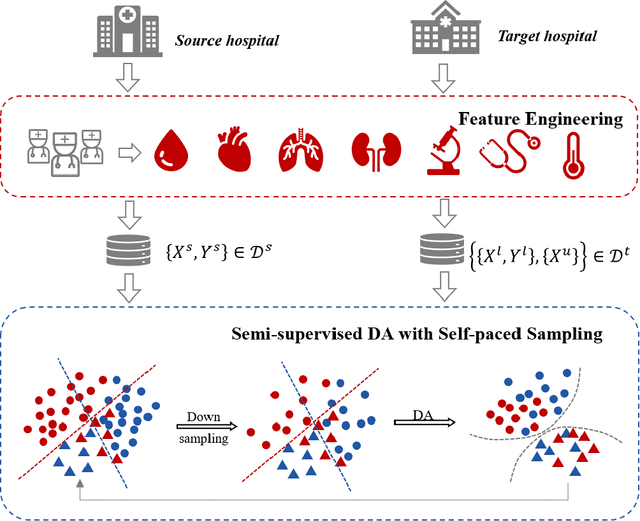


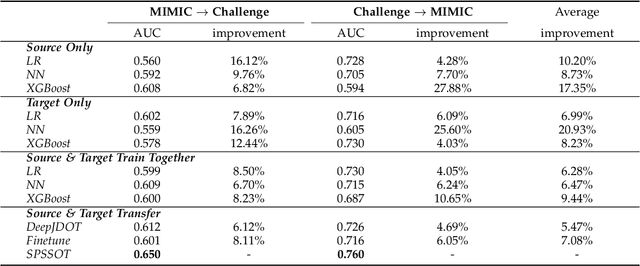
The utilization of computer technology to solve problems in medical scenarios has attracted considerable attention in recent years, which still has great potential and space for exploration. Among them, machine learning has been widely used in the prediction, diagnosis and even treatment of Sepsis. However, state-of-the-art methods require large amounts of labeled medical data for supervised learning. In real-world applications, the lack of labeled data will cause enormous obstacles if one hospital wants to deploy a new Sepsis detection system. Different from the supervised learning setting, we need to use known information (e.g., from another hospital with rich labeled data) to help build a model with acceptable performance, i.e., transfer learning. In this paper, we propose a semi-supervised optimal transport with self-paced ensemble framework for Sepsis early detection, called SPSSOT, to transfer knowledge from the other that has rich labeled data. In SPSSOT, we first extract the same clinical indicators from the source domain (e.g., hospital with rich labeled data) and the target domain (e.g., hospital with little labeled data), then we combine the semi-supervised domain adaptation based on optimal transport theory with self-paced under-sampling to avoid a negative transfer possibly caused by covariate shift and class imbalance. On the whole, SPSSOT is an end-to-end transfer learning method for Sepsis early detection which can automatically select suitable samples from two domains respectively according to the number of iterations and align feature space of two domains. Extensive experiments on two open clinical datasets demonstrate that comparing with other methods, our proposed SPSSOT, can significantly improve the AUC values with only 1% labeled data in the target domain in two transfer learning scenarios, MIMIC $rightarrow$ Challenge and Challenge $rightarrow$ MIMIC.