 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.
Scaling Up Models and Data with $\texttt{t5x}$ and $\texttt{seqio}$
Mar 31, 2022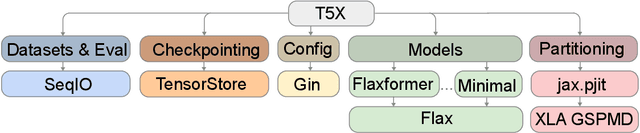
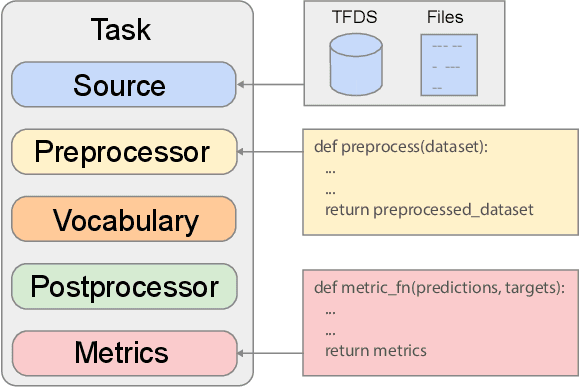
Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: $\texttt{t5x}$ simplifies the process of building and training large language models at scale while maintaining ease of use, and $\texttt{seqio}$ provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. $\texttt{t5x}$ and $\texttt{seqio}$ are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio, respectively.
Pathways: Asynchronous Distributed Dataflow for ML
Mar 23, 2022

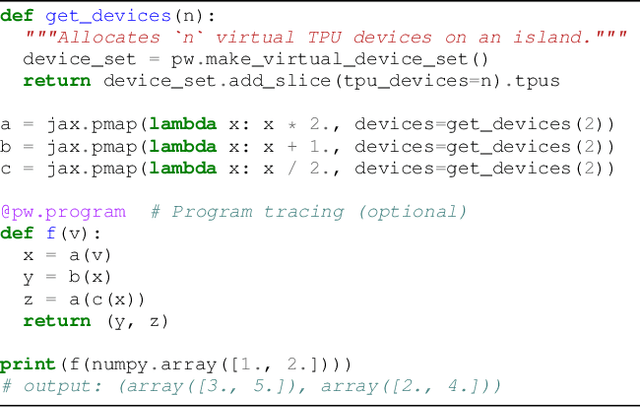

We present the design of a new large scale orchestration layer for accelerators. Our system, Pathways, is explicitly designed to enable exploration of new systems and ML research ideas, while retaining state of the art performance for current models. Pathways uses a sharded dataflow graph of asynchronous operators that consume and produce futures, and efficiently gang-schedules heterogeneous parallel computations on thousands of accelerators while coordinating data transfers over their dedicated interconnects. Pathways makes use of a novel asynchronous distributed dataflow design that lets the control plane execute in parallel despite dependencies in the data plane. This design, with careful engineering, allows Pathways to adopt a single-controller model that makes it easier to express complex new parallelism patterns. We demonstrate that Pathways can achieve performance parity (~100% accelerator utilization) with state-of-the-art systems when running SPMD computations over 2048 TPUs, while also delivering throughput comparable to the SPMD case for Transformer models that are pipelined across 16 stages, or sharded across two islands of accelerators connected over a data center network.
Model-Based Reinforcement Learning for Atari
Mar 05, 2019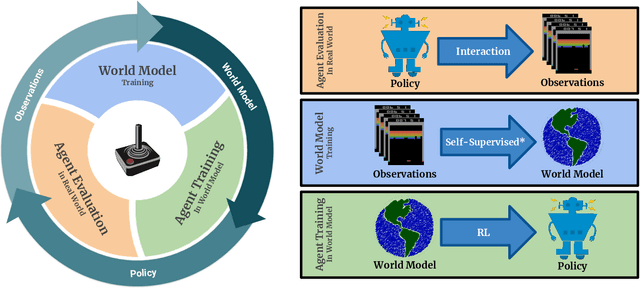
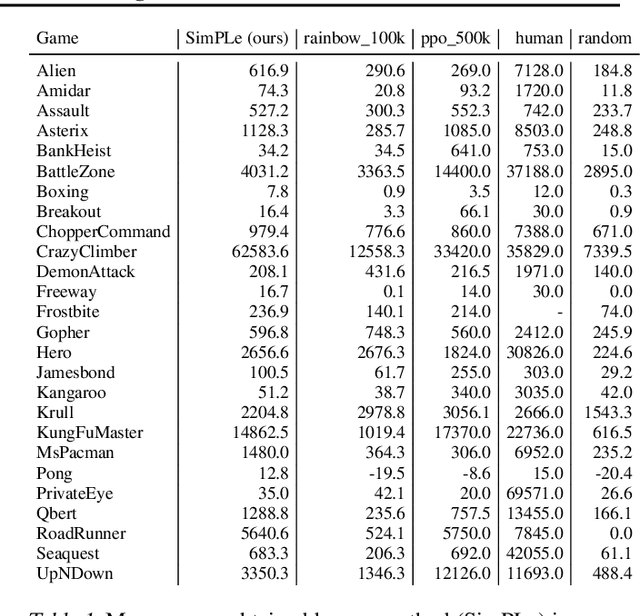
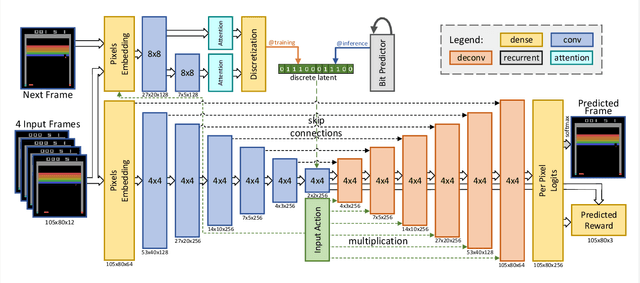
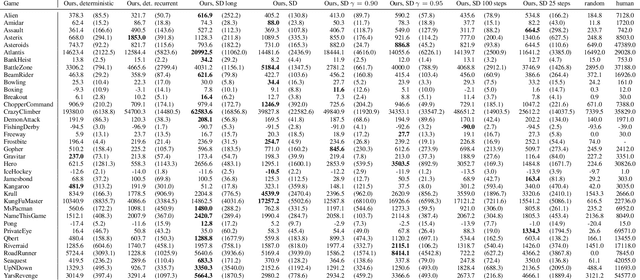
Model-free reinforcement learning (RL) can be used to learn effective policies for complex tasks, such as Atari games, even from image observations. However, this typically requires very large amounts of interaction -- substantially more, in fact, than a human would need to learn the same games. How can people learn so quickly? Part of the answer may be that people can learn how the game works and predict which actions will lead to desirable outcomes. In this paper, we explore how video prediction models can similarly enable agents to solve Atari games with orders of magnitude fewer interactions than model-free methods. We describe Simulated Policy Learning (SimPLe), a complete model-based deep RL algorithm based on video prediction models and present a comparison of several model architectures, including a novel architecture that yields the best results in our setting. Our experiments evaluate SimPLe on a range of Atari games and achieve competitive results with only 100K interactions between the agent and the environment (400K frames), which corresponds to about two hours of real-time play.
Mesh-TensorFlow: Deep Learning for Supercomputers
Nov 05, 2018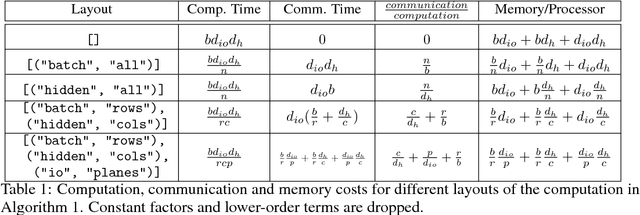
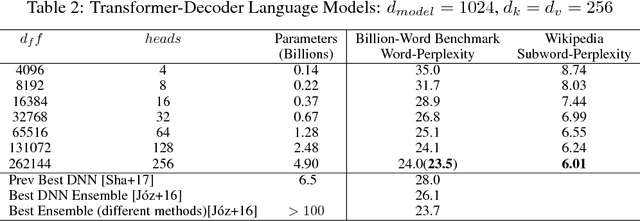
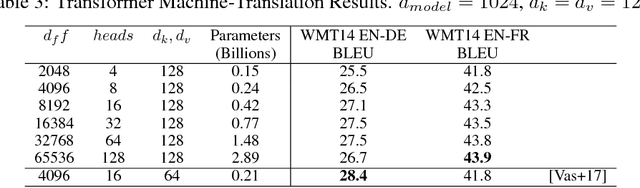
Batch-splitting (data-parallelism) is the dominant distributed Deep Neural Network (DNN) training strategy, due to its universal applicability and its amenability to Single-Program-Multiple-Data (SPMD) programming. However, batch-splitting suffers from problems including the inability to train very large models (due to memory constraints), high latency, and inefficiency at small batch sizes. All of these can be solved by more general distribution strategies (model-parallelism). Unfortunately, efficient model-parallel algorithms tend to be complicated to discover, describe, and to implement, particularly on large clusters. We introduce Mesh-TensorFlow, a language for specifying a general class of distributed tensor computations. Where data-parallelism can be viewed as splitting tensors and operations along the "batch" dimension, in Mesh-TensorFlow, the user can specify any tensor-dimensions to be split across any dimensions of a multi-dimensional mesh of processors. A Mesh-TensorFlow graph compiles into a SPMD program consisting of parallel operations coupled with collective communication primitives such as Allreduce. We use Mesh-TensorFlow to implement an efficient data-parallel, model-parallel version of the Transformer sequence-to-sequence model. Using TPU meshes of up to 512 cores, we train Transformer models with up to 5 billion parameters, surpassing state of the art results on WMT'14 English-to-French translation task and the one-billion-word language modeling benchmark. Mesh-Tensorflow is available at https://github.com/tensorflow/mesh .
Tensor2Tensor for Neural Machine Translation
Mar 16, 2018
Tensor2Tensor is a library for deep learning models that is well-suited for neural machine translation and includes the reference implementation of the state-of-the-art Transformer model.
Generating Wikipedia by Summarizing Long Sequences
Jan 30, 2018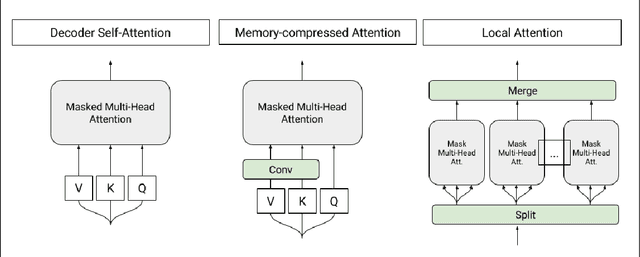

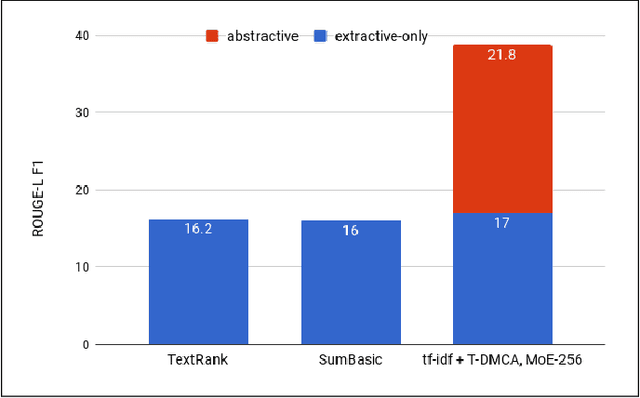

We show that generating English Wikipedia articles can be approached as a multi- document summarization of source documents. We use extractive summarization to coarsely identify salient information and a neural abstractive model to generate the article. For the abstractive model, we introduce a decoder-only architecture that can scalably attend to very long sequences, much longer than typical encoder- decoder architectures used in sequence transduction. We show that this model can generate fluent, coherent multi-sentence paragraphs and even whole Wikipedia articles. When given reference documents, we show it can extract relevant factual information as reflected in perplexity, ROUGE scores and human evaluations.