 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating Emergent Properties of Human Driving Behavior Using Multi-Agent Reward Augmented Imitation Learning
Mar 14, 2019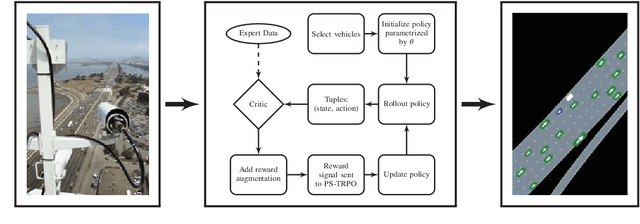
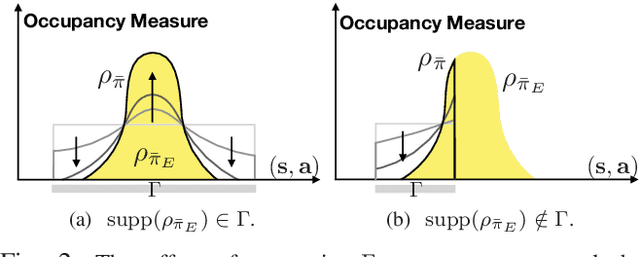
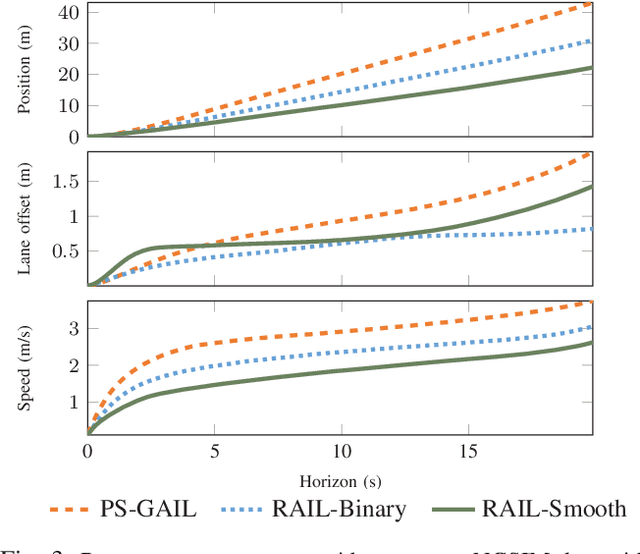
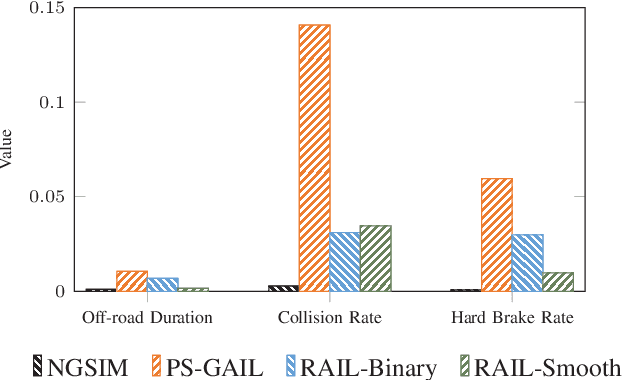
Recent developments in multi-agent imitation learning have shown promising results for modeling the behavior of human drivers. However, it is challenging to capture emergent traffic behaviors that are observed in real-world datasets. Such behaviors arise due to the many local interactions between agents that are not commonly accounted for in imitation learning. This paper proposes Reward Augmented Imitation Learning (RAIL), which integrates reward augmentation into the multi-agent imitation learning framework and allows the designer to specify prior knowledge in a principled fashion. We prove that convergence guarantees for the imitation learning process are preserved under the application of reward augmentation. This method is validated in a driving scenario, where an entire traffic scene is controlled by driving policies learned using our proposed algorithm. Further, we demonstrate improved performance in comparison to traditional imitation learning algorithms both in terms of the local actions of a single agent and the behavior of emergent properties in complex, multi-agent settings.
Real-time Prediction of Automotive Collision Risk from Monocular Video
Feb 04, 2019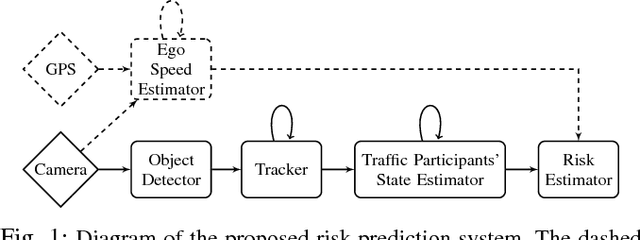
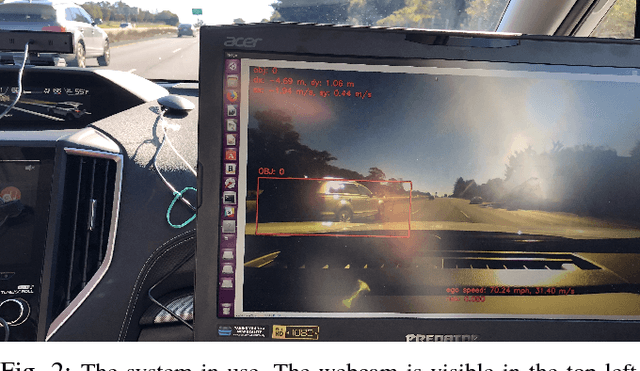
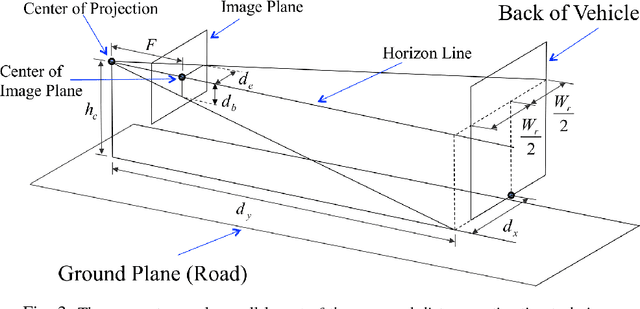
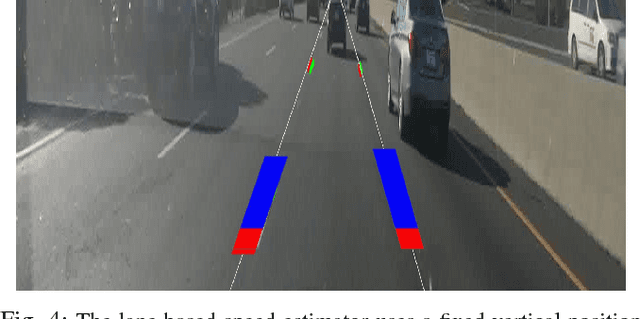
Many automotive applications, such as Advanced Driver Assistance Systems (ADAS) for collision avoidance and warnings, require estimating the future automotive risk of a driving scene. We present a low-cost system that predicts the collision risk over an intermediate time horizon from a monocular video source, such as a dashboard-mounted camera. The modular system includes components for object detection, object tracking, and state estimation. We introduce solutions to the object tracking and distance estimation problems. Advanced approaches to the other tasks are used to produce real-time predictions of the automotive risk for the next 10 s at over 5 Hz. The system is designed such that alternative components can be substituted with minimal effort. It is demonstrated on common physical hardware, specifically an off-the-shelf gaming laptop and a webcam. We extend the framework to support absolute speed estimation and more advanced risk estimation techniques.
Multi-Agent Imitation Learning for Driving Simulation
Mar 02, 2018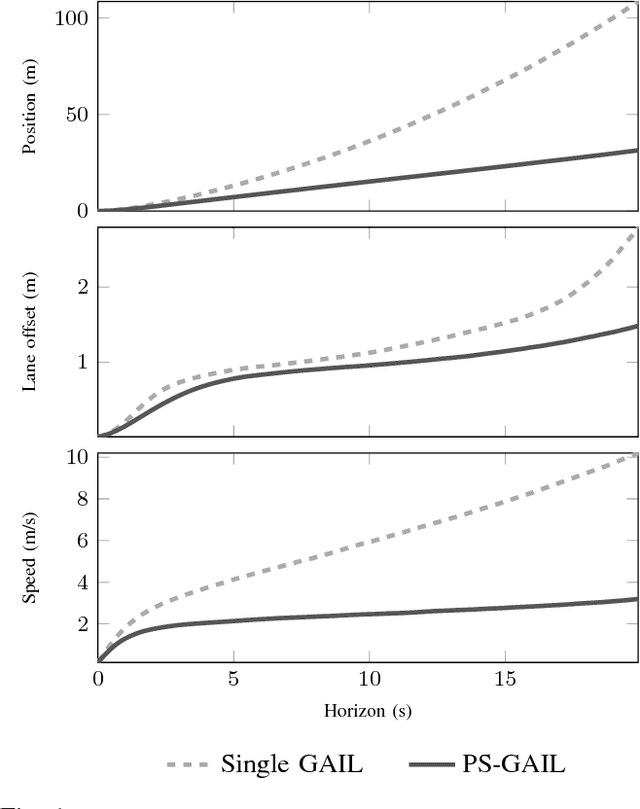
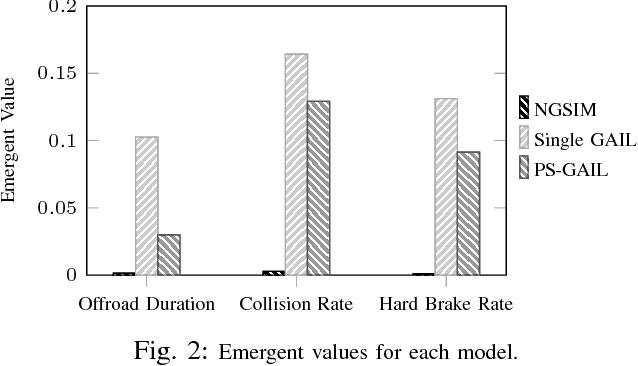
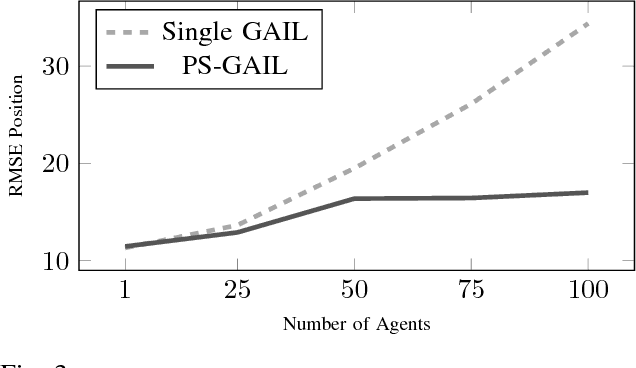
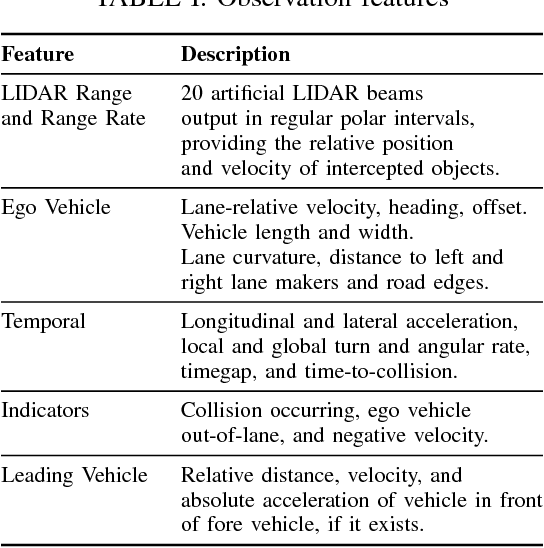
Simulation is an appealing option for validating the safety of autonomous vehicles. Generative Adversarial Imitation Learning (GAIL) has recently been shown to learn representative human driver models. These human driver models were learned through training in single-agent environments, but they have difficulty in generalizing to multi-agent driving scenarios. We argue these difficulties arise because observations at training and test time are sampled from different distributions. This difference makes such models unsuitable for the simulation of driving scenes, where multiple agents must interact realistically over long time horizons. We extend GAIL to address these shortcomings through a parameter-sharing approach grounded in curriculum learning. Compared with single-agent GAIL policies, policies generated by our PS-GAIL method prove superior at interacting stably in a multi-agent setting and capturing the emergent behavior of human drivers.