 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting ICU In-Hospital Mortality Using Adaptive Transformer Layer Fusion
Jun 06, 2025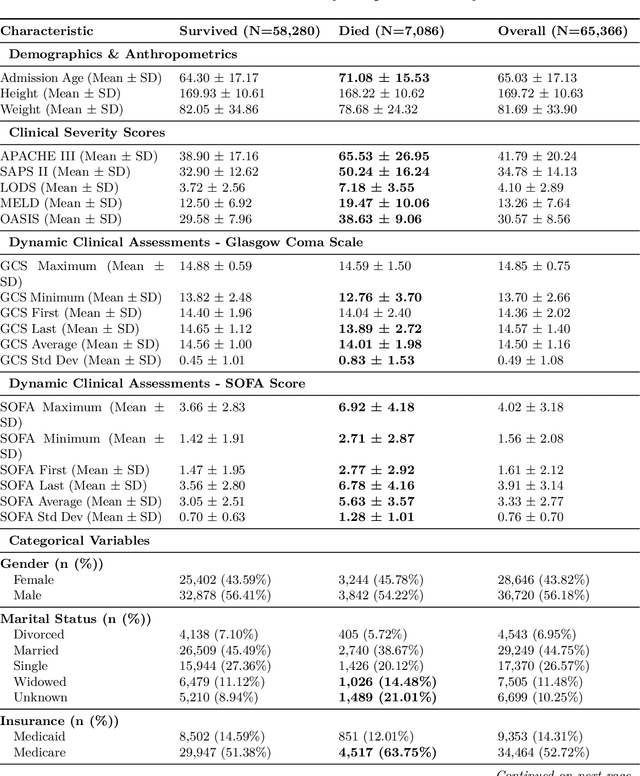
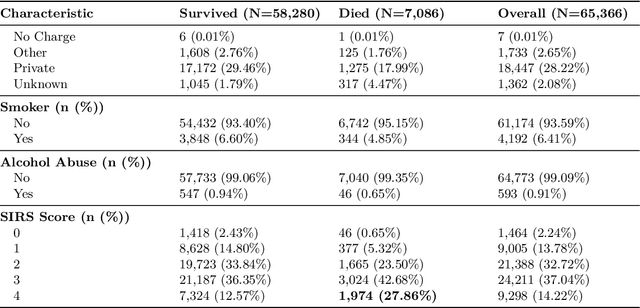
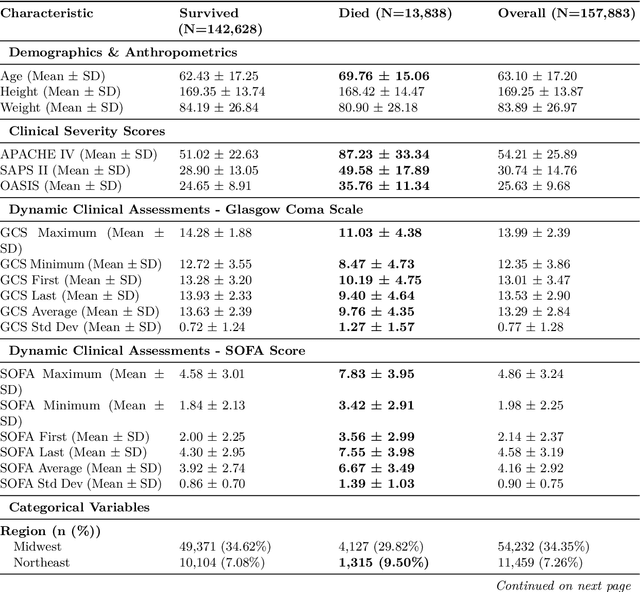
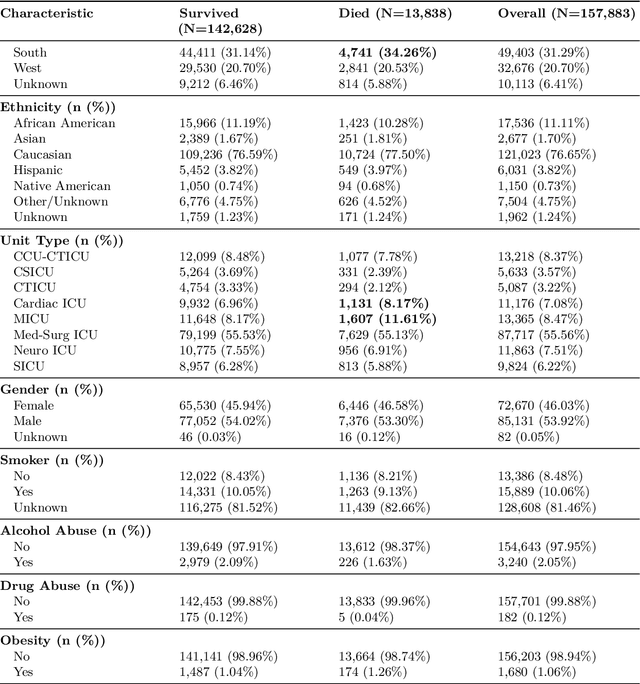
Early identification of high-risk ICU patients is crucial for directing limited medical resources. We introduce ALFIA (Adaptive Layer Fusion with Intelligent Attention), a modular, attention-based architecture that jointly trains LoRA (Low-Rank Adaptation) adapters and an adaptive layer-weighting mechanism to fuse multi-layer semantic features from a BERT backbone. Trained on our rigorous cw-24 (CriticalWindow-24) benchmark, ALFIA surpasses state-of-the-art tabular classifiers in AUPRC while preserving a balanced precision-recall profile. The embeddings produced by ALFIA's fusion module, capturing both fine-grained clinical cues and high-level concepts, enable seamless pairing with GBDTs (CatBoost/LightGBM) as ALFIA-boost, and deep neuro networks as ALFIA-nn, yielding additional performance gains. Our experiments confirm ALFIA's superior early-warning performance, by operating directly on routine clinical text, it furnishes clinicians with a convenient yet robust tool for risk stratification and timely intervention in critical-care settings.
Sketch2Scene: Automatic Generation of Interactive 3D Game Scenes from User's Casual Sketches
Aug 08, 2024



3D Content Generation is at the heart of many computer graphics applications, including video gaming, film-making, virtual and augmented reality, etc. This paper proposes a novel deep-learning based approach for automatically generating interactive and playable 3D game scenes, all from the user's casual prompts such as a hand-drawn sketch. Sketch-based input offers a natural, and convenient way to convey the user's design intention in the content creation process. To circumvent the data-deficient challenge in learning (i.e. the lack of large training data of 3D scenes), our method leverages a pre-trained 2D denoising diffusion model to generate a 2D image of the scene as the conceptual guidance. In this process, we adopt the isometric projection mode to factor out unknown camera poses while obtaining the scene layout. From the generated isometric image, we use a pre-trained image understanding method to segment the image into meaningful parts, such as off-ground objects, trees, and buildings, and extract the 2D scene layout. These segments and layouts are subsequently fed into a procedural content generation (PCG) engine, such as a 3D video game engine like Unity or Unreal, to create the 3D scene. The resulting 3D scene can be seamlessly integrated into a game development environment and is readily playable. Extensive tests demonstrate that our method can efficiently generate high-quality and interactive 3D game scenes with layouts that closely follow the user's intention.
3D Backbone Network for 3D Object Detection
Jan 24, 2019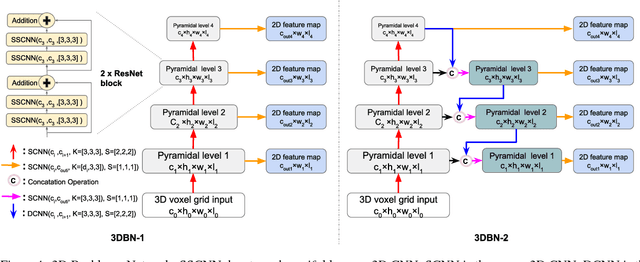
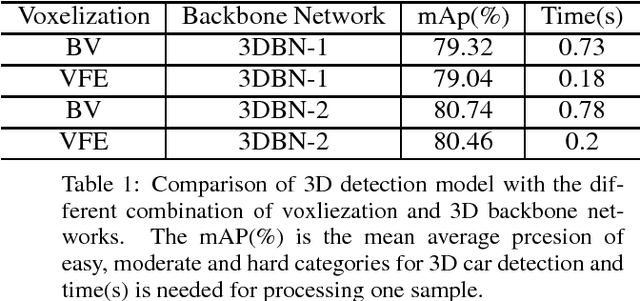
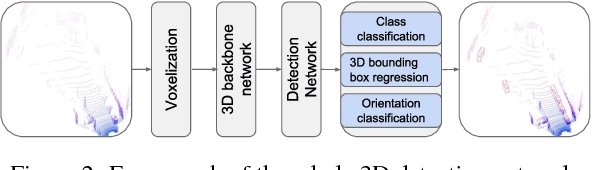
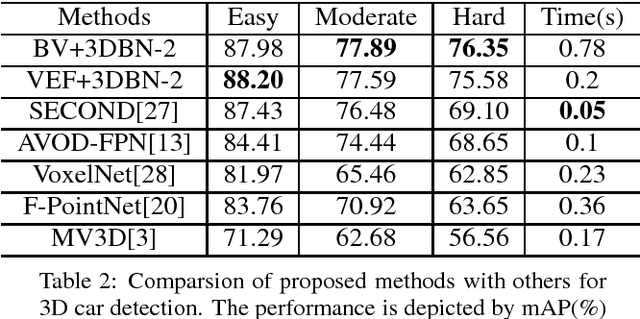
The task of detecting 3D objects in point cloud has a pivotal role in many real-world applications. However, 3D object detection performance is behind that of 2D object detection due to the lack of powerful 3D feature extraction methods. In order to address this issue, we propose to build a 3D backbone network to learn rich 3D feature maps by using sparse 3D CNN operations for 3D object detection in point cloud. The 3D backbone network can inherently learn 3D features from almost raw data without compressing point cloud into multiple 2D images and generate rich feature maps for object detection. The sparse 3D CNN takes full advantages of the sparsity in the 3D point cloud to accelerate computation and save memory, which makes the 3D backbone network achievable. Empirical experiments are conducted on the KITTI benchmark and results show that the proposed method can achieve state-of-the-art performance for 3D object detection.