 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Switch: Composing Controllers to Traverse a Sequence of Terrain Artifacts
Paper and Code
Nov 01, 2020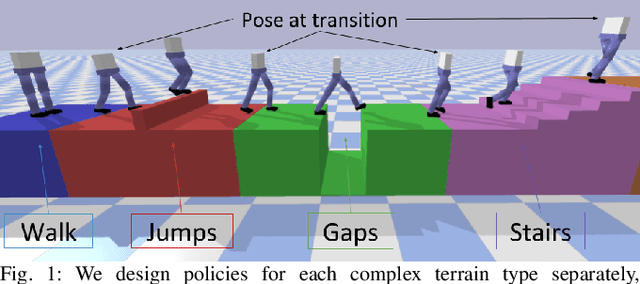
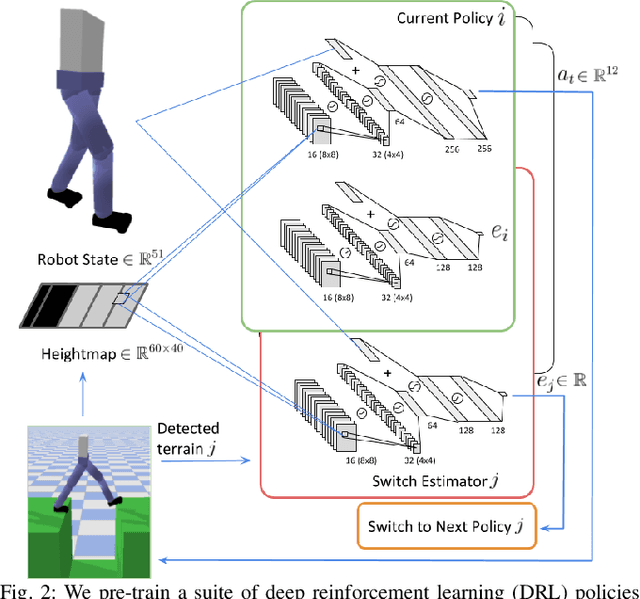
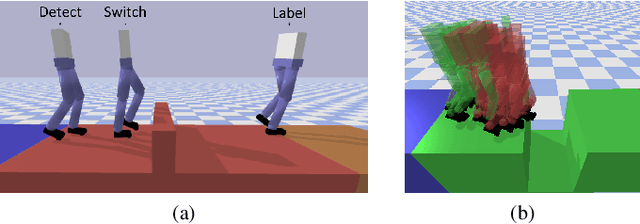
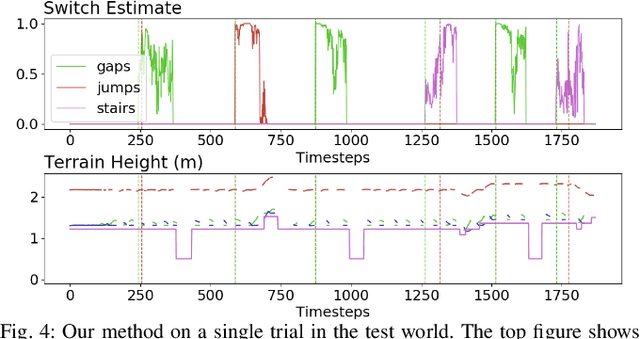
Legged robots often use separate control policies that are highly engineered for traversing difficult terrain such as stairs, gaps, and steps, where switching between policies is only possible when the robot is in a region that is common to adjacent controllers. Deep Reinforcement Learning (DRL) is a promising alternative to hand-crafted control design, though typically requires the full set of test conditions to be known before training. DRL policies can result in complex (often unrealistic) behaviours that have few or no overlapping regions between adjacent policies, making it difficult to switch behaviours. In this work we develop multiple DRL policies with Curriculum Learning (CL), each that can traverse a single respective terrain condition, while ensuring an overlap between policies. We then train a network for each destination policy that estimates the likelihood of successfully switching from any other policy. We evaluate our switching method on a previously unseen combination of terrain artifacts and show that it performs better than heuristic methods. While our method is trained on individual terrain types, it performs comparably to a Deep Q Network trained on the full set of terrain conditions. This approach allows the development of separate policies in constrained conditions with embedded prior knowledge about each behaviour, that is scalable to any number of behaviours, and prepares DRL methods for applications in the real world