 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Setup Policies: Reliable Transition Between Locomotion Behaviours
Paper and Code
Jan 23, 2021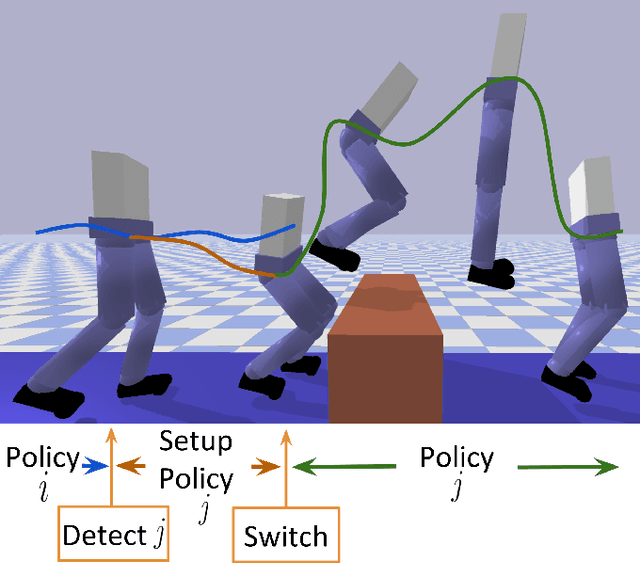
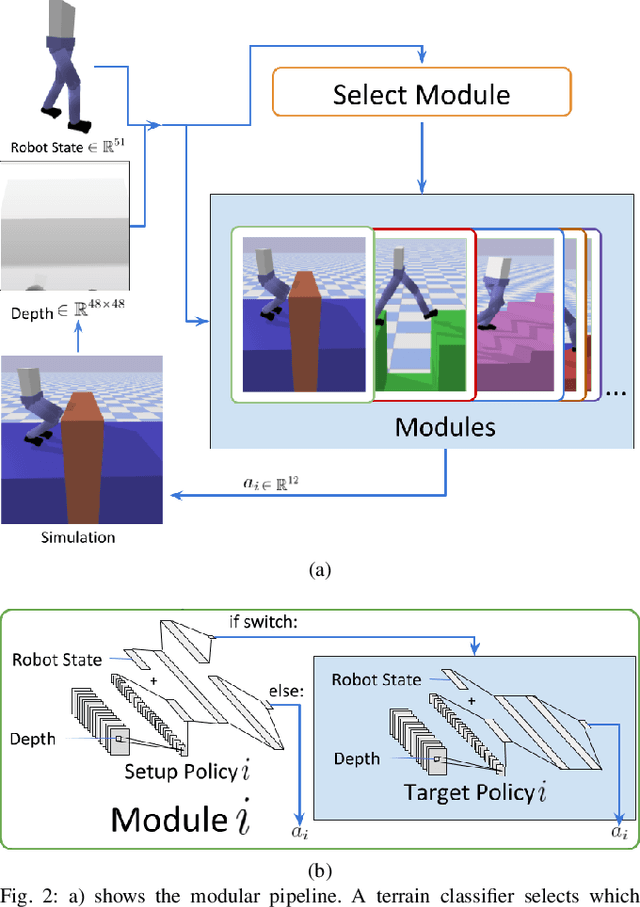
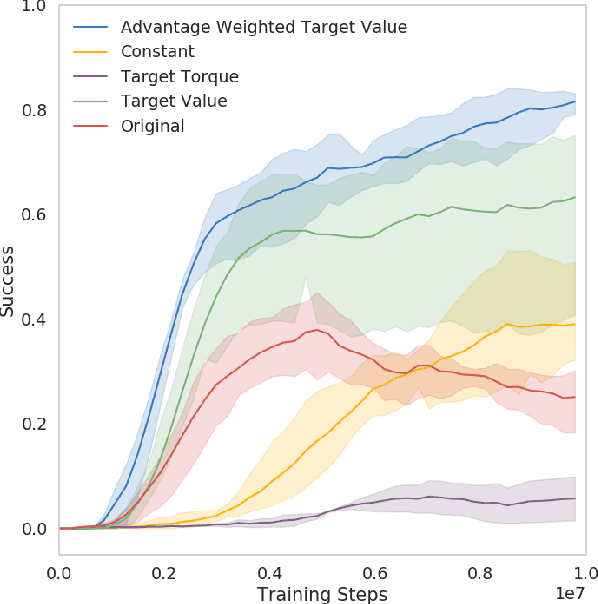

Dynamic platforms that operate over manyunique terrain conditions typically require multiple controllers.To transition safely between controllers, there must be anoverlap of states between adjacent controllers. We developa novel method for training Setup Policies that bridge thetrajectories between pre-trained Deep Reinforcement Learning(DRL) policies. We demonstrate our method with a simulatedbiped traversing a difficult jump terrain, where a single policyfails to learn the task, and switching between pre-trainedpolicies without Setup Policies also fails. We perform anablation of key components of our system, and show thatour method outperforms others that learn transition policies.We demonstrate our method with several difficult and diverseterrain types, and show that we can use Setup Policies as partof a modular control suite to successfully traverse a sequence ofcomplex terrains. We show that using Setup Policies improvesthe success rate for traversing a single difficult jump terrain(from 1.5%success rate without Setup Policies to 82%), and asequence of various terrains (from 6.5%without Setup Policiesto 29.1%).