 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Pause Information for More Accurate Entity Recognition
Sep 27, 2021
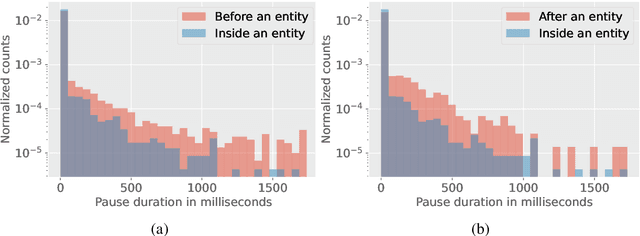

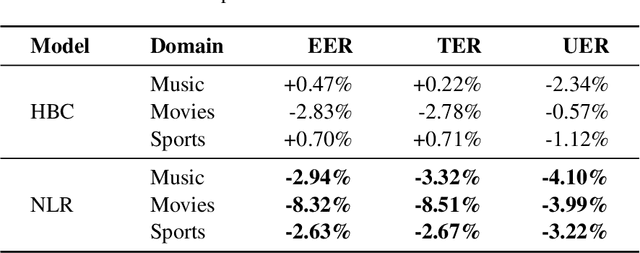
Entity tags in human-machine dialog are integral to natural language understanding (NLU) tasks in conversational assistants. However, current systems struggle to accurately parse spoken queries with the typical use of text input alone, and often fail to understand the user intent. Previous work in linguistics has identified a cross-language tendency for longer speech pauses surrounding nouns as compared to verbs. We demonstrate that the linguistic observation on pauses can be used to improve accuracy in machine-learnt language understanding tasks. Analysis of pauses in French and English utterances from a commercial voice assistant shows the statistically significant difference in pause duration around multi-token entity span boundaries compared to within entity spans. Additionally, in contrast to text-based NLU, we apply pause duration to enrich contextual embeddings to improve shallow parsing of entities. Results show that our proposed novel embeddings improve the relative error rate by up to 8% consistently across three domains for French, without any added annotation or alignment costs to the parser.