 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising-based Contractive Imitation Learning
Mar 20, 2025A fundamental challenge in imitation learning is the \emph{covariate shift} problem. Existing methods to mitigate covariate shift often require additional expert interactions, access to environment dynamics, or complex adversarial training, which may not be practical in real-world applications. In this paper, we propose a simple yet effective method (DeCIL) to mitigate covariate shift by incorporating a denoising mechanism that enhances the contraction properties of the state transition mapping. Our approach involves training two neural networks: a dynamics model ( f ) that predicts the next state from the current state, and a joint state-action denoising policy network ( d ) that refines this state prediction via denoising and outputs the corresponding action. We provide theoretical analysis showing that the denoising network acts as a local contraction mapping, reducing the error propagation of the state transition and improving stability. Our method is straightforward to implement and can be easily integrated with existing imitation learning frameworks without requiring additional expert data or complex modifications to the training procedure. Empirical results demonstrate that our approach effectively improves success rate of various imitation learning tasks under noise perturbation.
Neural SDEs as a Unified Approach to Continuous-Domain Sequence Modeling
Jan 31, 2025



Inspired by the ubiquitous use of differential equations to model continuous dynamics across diverse scientific and engineering domains, we propose a novel and intuitive approach to continuous sequence modeling. Our method interprets time-series data as \textit{discrete samples from an underlying continuous dynamical system}, and models its time evolution using Neural Stochastic Differential Equation (Neural SDE), where both the flow (drift) and diffusion terms are parameterized by neural networks. We derive a principled maximum likelihood objective and a \textit{simulation-free} scheme for efficient training of our Neural SDE model. We demonstrate the versatility of our approach through experiments on sequence modeling tasks across both embodied and generative AI. Notably, to the best of our knowledge, this is the first work to show that SDE-based continuous-time modeling also excels in such complex scenarios, and we hope that our work opens up new avenues for research of SDE models in high-dimensional and temporally intricate domains.
Safe adaptation in multiagent competition
Mar 14, 2022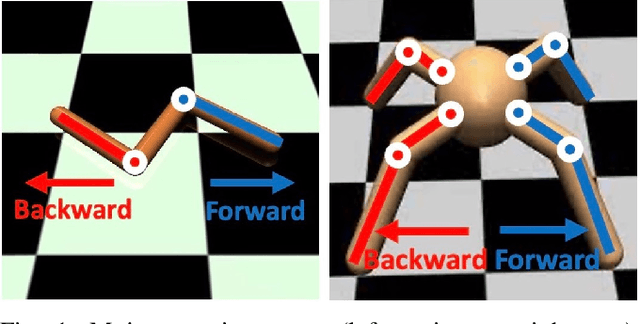
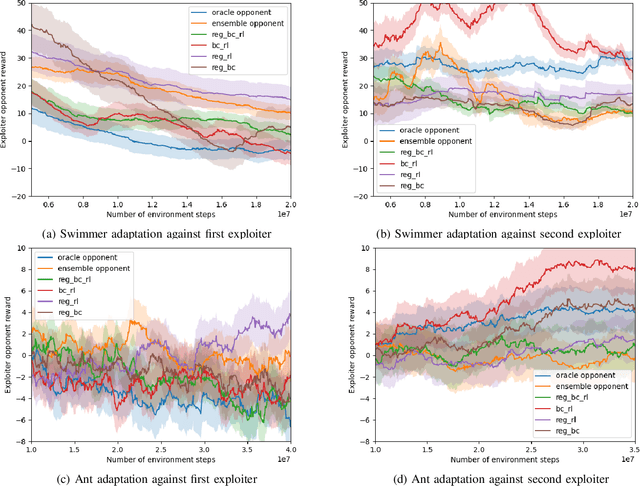
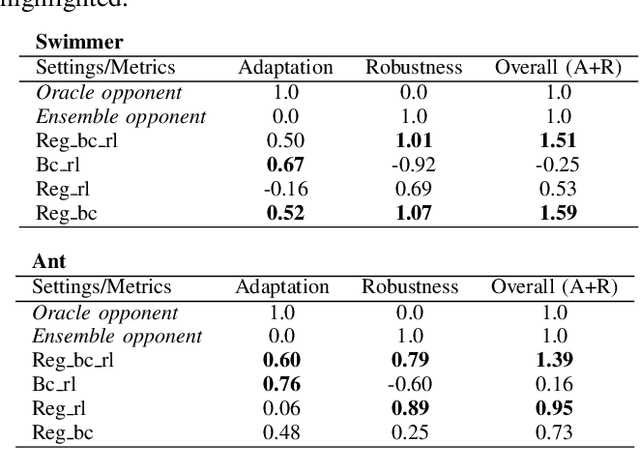

Achieving the capability of adapting to ever-changing environments is a critical step towards building fully autonomous robots that operate safely in complicated scenarios. In multiagent competitive scenarios, agents may have to adapt to new opponents with previously unseen behaviors by learning from the interaction experiences between the ego-agent and the opponent. However, this adaptation is susceptible to opponent exploitation. As the ego-agent updates its own behavior to exploit the opponent, its own behavior could become more exploitable as a result of overfitting to this specific opponent's behavior. To overcome this difficulty, we developed a safe adaptation approach in which the ego-agent is trained against a regularized opponent model, which effectively avoids overfitting and consequently improves the robustness of the ego-agent's policy. We evaluated our approach in the Mujoco domain with two competing agents. The experiment results suggest that our approach effectively achieves both adaptation to the specific opponent that the ego-agent is interacting with and maintaining low exploitability to other possible opponent exploitation.
Scaling Up Multiagent Reinforcement Learning for Robotic Systems: Learn an Adaptive Sparse Communication Graph
Mar 03, 2020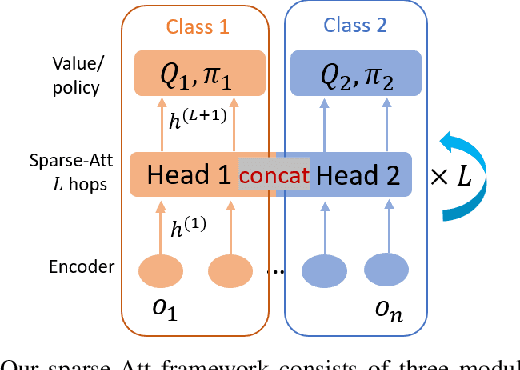
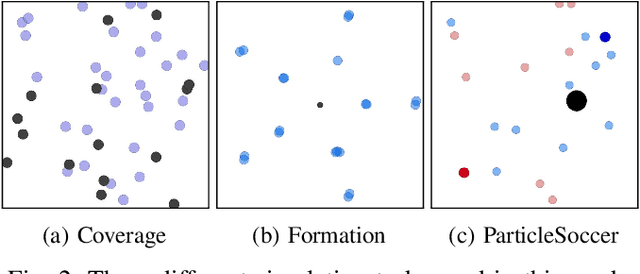
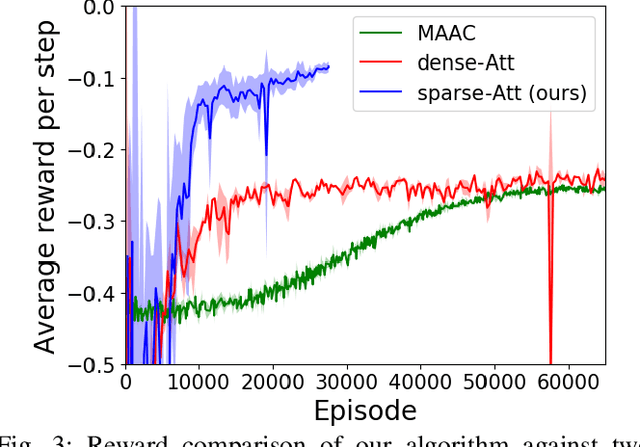
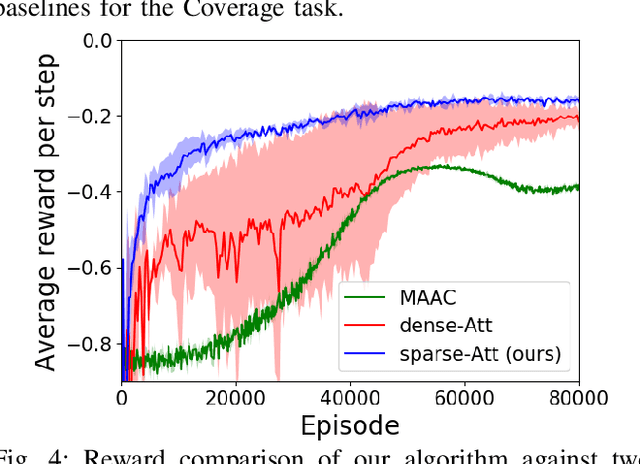
The complexity of multiagent reinforcement learning (MARL) in multiagent systems increases exponentially with respect to the agent number. This scalability issue prevents MARL from being applied in large-scale multiagent systems. However, one critical feature in MARL that is often neglected is that the interactions between agents are quite sparse. Without exploiting this sparsity structure, existing works aggregate information from all of the agents and thus have a high sample complexity. To address this issue, we propose an adaptive sparse attention mechanism by generalizing a sparsity-inducing activation function. Then a sparse communication graph in MARL is learned by graph neural networks based on this new attention mechanism. Through this sparsity structure, the agents can communicate in an effective as well as efficient way via only selectively attending to agents that matter the most and thus the scale of the MARL problem is reduced with little optimality compromised. Comparative results show that our algorithm can learn an interpretable sparse structure and outperforms previous works by a significant margin on applications involving a large-scale multiagent system.
Robust Opponent Modeling via Adversarial Ensemble Reinforcement Learning in Asymmetric Imperfect-Information Games
Oct 28, 2019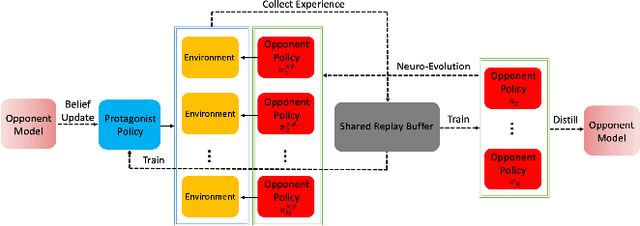
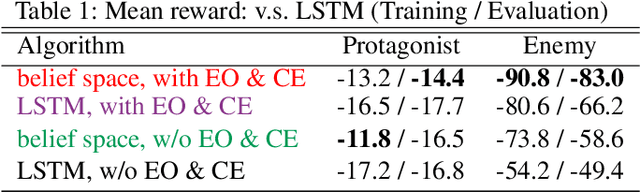

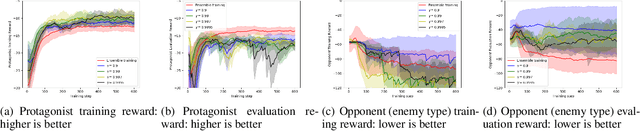
This paper presents an algorithmic framework for learning robust policies in asymmetric imperfect-information games, where the joint reward could depend on the uncertain opponent type (a private information known only to the opponent itself and its ally). In order to maximize the reward, the protagonist agent has to infer the opponent type through agent modeling. We use multiagent reinforcement learning (MARL) to learn opponent models through self-play, which captures the full strategy interaction and reasoning between agents. However, agent policies learned from self-play can suffer from mutual overfitting. Ensemble training methods can be used to improve the robustness of agent policy against different opponents, but it also significantly increases the computational overhead. In order to achieve a good trade-off between the robustness of the learned policy and the computation complexity, we propose to train a separate opponent policy against the protagonist agent for evaluation purposes. The reward achieved by this opponent is a noisy measure of the robustness of the protagonist agent policy due to the intrinsic stochastic nature of a reinforcement learner. To handle this stochasticity, we apply a stochastic optimization scheme to dynamically update the opponent ensemble to optimize an objective function that strikes a balance between robustness and computation complexity. We empirically show that, under the same limited computational budget, the proposed method results in more robust policy learning than standard ensemble training.
Active Perception in Adversarial Scenarios using Maximum Entropy Deep Reinforcement Learning
Feb 14, 2019
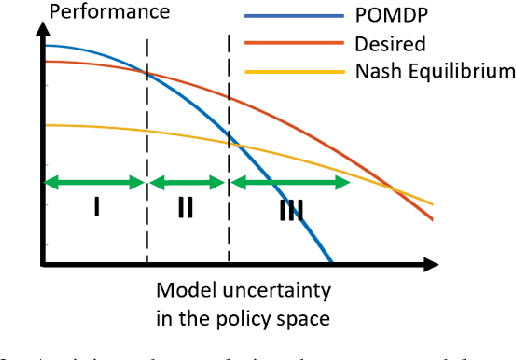
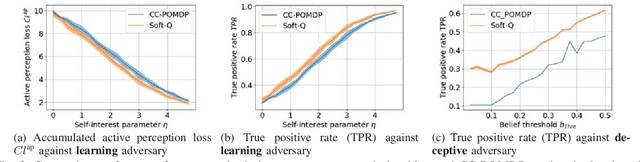
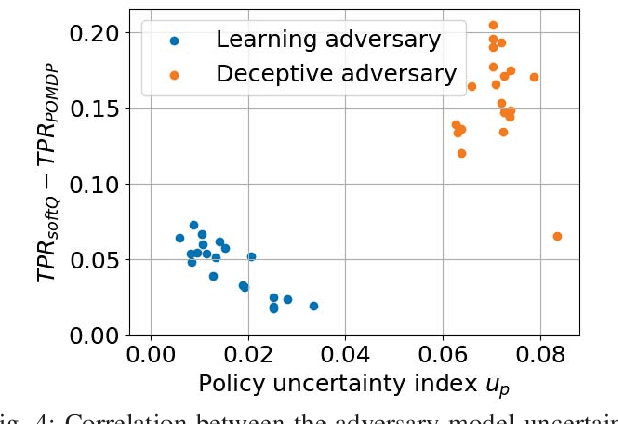
We pose an active perception problem where an autonomous agent actively interacts with a second agent with potentially adversarial behaviors. Given the uncertainty in the intent of the other agent, the objective is to collect further evidence to help discriminate potential threats. The main technical challenges are the partial observability of the agent intent, the adversary modeling, and the corresponding uncertainty modeling. Note that an adversary agent may act to mislead the autonomous agent by using a deceptive strategy that is learned from past experiences. We propose an approach that combines belief space planning, generative adversary modeling, and maximum entropy reinforcement learning to obtain a stochastic belief space policy. By accounting for various adversarial behaviors in the simulation framework and minimizing the predictability of the autonomous agent's action, the resulting policy is more robust to unmodeled adversarial strategies. This improved robustness is empirically shown against an adversary that adapts to and exploits the autonomous agent's policy when compared with a standard Chance-Constraint Partially Observable Markov Decision Process robust approach.
A Probe Towards Understanding GAN and VAE Models
Dec 17, 2018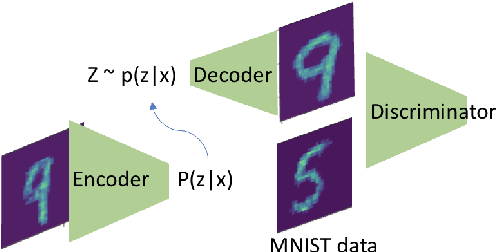
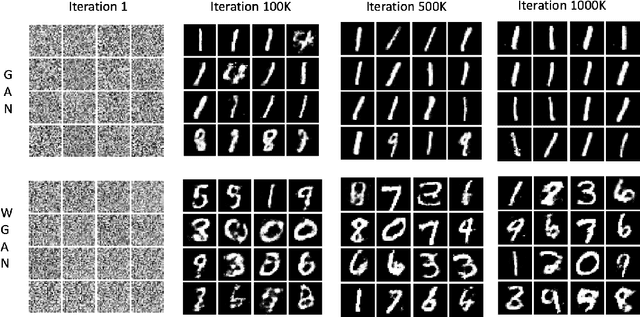


This project report compares some known GAN and VAE models proposed prior to 2017. There has been significant progress after we finished this report. We upload this report as an introduction to generative models and provide some personal interpretations supported by empirical evidence. Both generative adversarial network models and variational autoencoders have been widely used to approximate probability distributions of data sets. Although they both use parametrized distributions to approximate the underlying data distribution, whose exact inference is intractable, their behaviors are very different. We summarize our experiment results that compare these two categories of models in terms of fidelity and mode collapse. We provide a hypothesis to explain their different behaviors and propose a new model based on this hypothesis. We further tested our proposed model on MNIST dataset and CelebA dataset.
Transferable Pedestrian Motion Prediction Models at Intersections
Mar 15, 2018
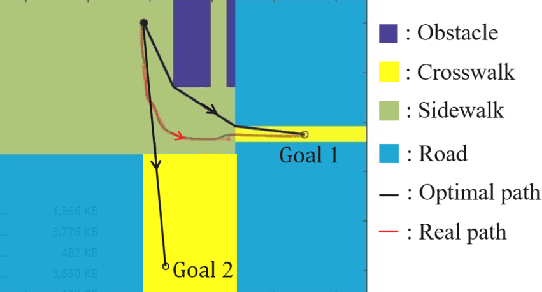


One desirable capability of autonomous cars is to accurately predict the pedestrian motion near intersections for safe and efficient trajectory planning. We are interested in developing transfer learning algorithms that can be trained on the pedestrian trajectories collected at one intersection and yet still provide accurate predictions of the trajectories at another, previously unseen intersection. We first discussed the feature selection for transferable pedestrian motion models in general. Following this discussion, we developed one transferable pedestrian motion prediction algorithm based on Inverse Reinforcement Learning (IRL) that infers pedestrian intentions and predicts future trajectories based on observed trajectory. We evaluated our algorithm on a dataset collected at two intersections, trained at one intersection and tested at the other intersection. We used the accuracy of augmented semi-nonnegative sparse coding (ASNSC), trained and tested at the same intersection as a baseline. The result shows that the proposed algorithm improves the baseline accuracy by 40% in the non-transfer task, and 16% in the transfer task.
Enhancement of Low-cost GNSS Localization in Connected Vehicle Networks Using Rao-Blackwellized Particle Filters
Aug 31, 2016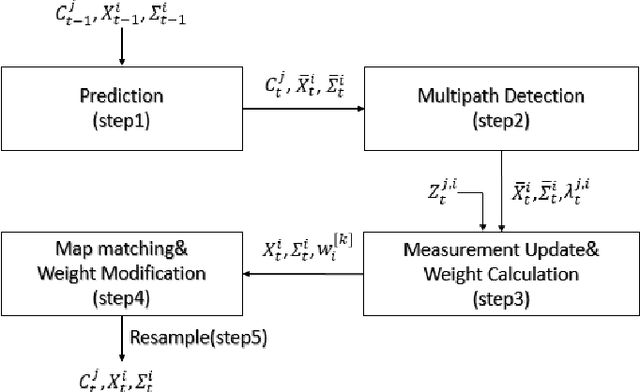
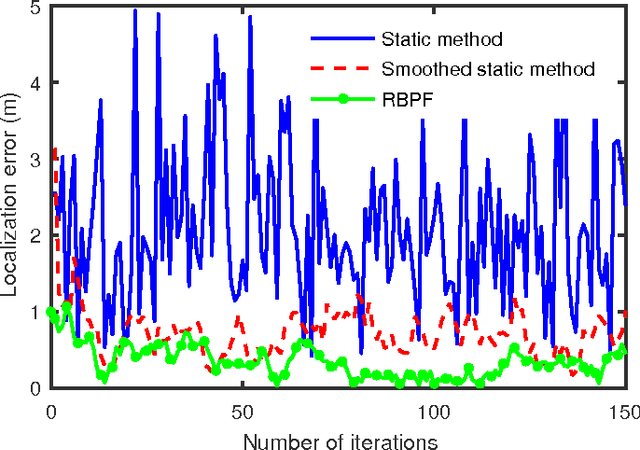
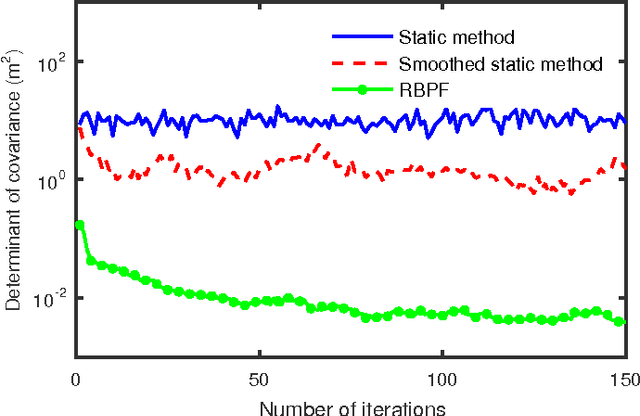
An essential function for automated vehicle technologies is accurate localization. It is difficult, however, to achieve lane-level accuracy with low-cost Global Navigation Satellite System (GNSS) receivers due to the biased noisy pseudo-range measurements. Approaches such as Differential GNSS can improve the accuracy, but usually require an enormous amount of investment in base stations. The emerging connected vehicle technologies provide an alternative approach to improving the localization accuracy. It has been shown in this paper that localization accuracy can be enhanced by fusing GNSS information within a group of connected vehicles and matching the configuration of the group to a digital map to eliminate the common bias in localization. A Rao-Blackwellized particle filter (RBPF) was used to jointly estimate the common biases of the pseudo-ranges and the vehicles positions. Multipath biases, which are non-common to vehicles, were mitigated by a multi-hypothesis detection-rejection approach. The temporal correlation was exploited through the prediction-update process. The proposed approach was compared to the existing static and smoothed static methods in the intersection scenario. Simulation results show that the proposed algorithm reduced the estimation error by fifty percent and reduced the estimation variance by two orders of magnitude.