 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuance Matters: Probing Epistemic Consistency in Causal Reasoning
Paper and Code
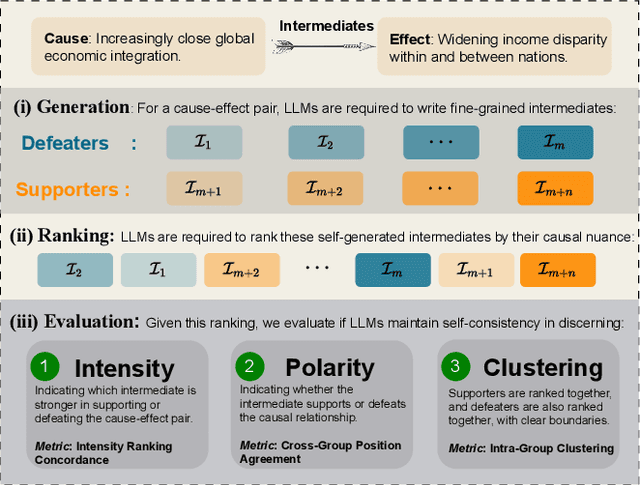
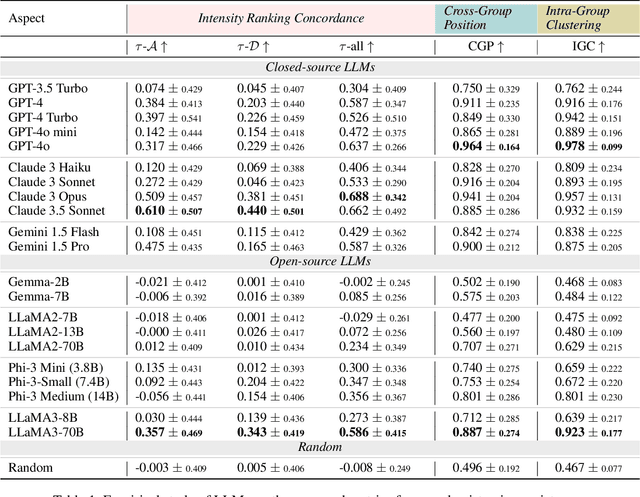
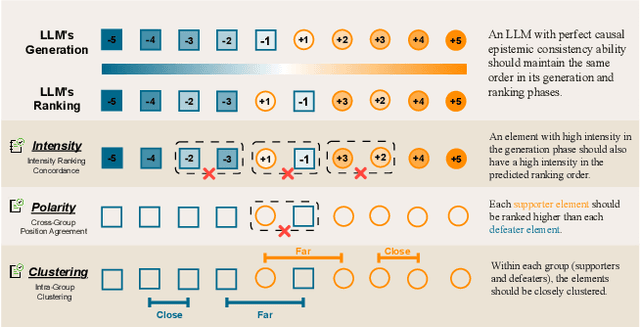
To address this gap, our study introduces the concept of causal epistemic consistency, which focuses on the self-consistency of Large Language Models (LLMs) in differentiating intermediates with nuanced differences in causal reasoning. We propose a suite of novel metrics -- intensity ranking concordance, cross-group position agreement, and intra-group clustering -- to evaluate LLMs on this front. Through extensive empirical studies on 21 high-profile LLMs, including GPT-4, Claude3, and LLaMA3-70B, we have favoring evidence that current models struggle to maintain epistemic consistency in identifying the polarity and intensity of intermediates in causal reasoning. Additionally, we explore the potential of using internal token probabilities as an auxiliary tool to maintain causal epistemic consistency. In summary, our study bridges a critical gap in AI research by investigating the self-consistency over fine-grained intermediates involved in causal reasoning.