 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLARE: Towards Universal Dataset Purification against Backdoor Attacks
Nov 29, 2024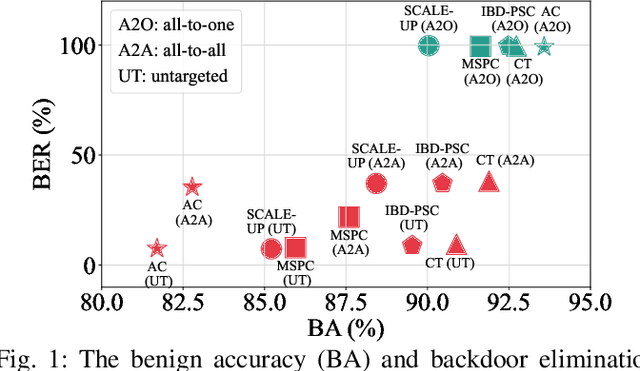
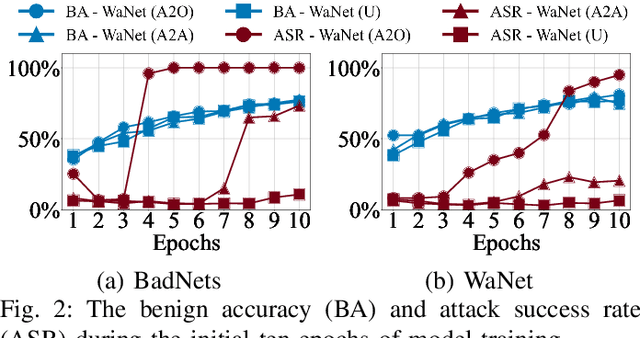
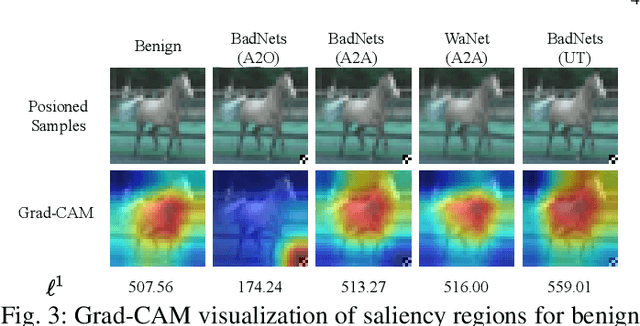
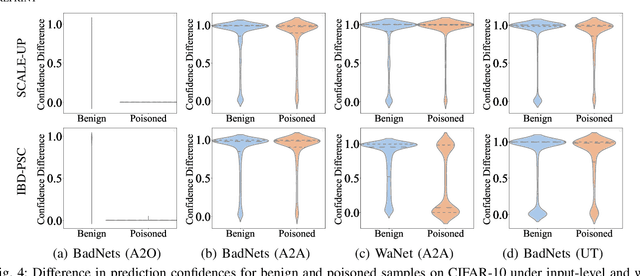
Deep neural networks (DNNs) are susceptible to backdoor attacks, where adversaries poison datasets with adversary-specified triggers to implant hidden backdoors, enabling malicious manipulation of model predictions. Dataset purification serves as a proactive defense by removing malicious training samples to prevent backdoor injection at its source. We first reveal that the current advanced purification methods rely on a latent assumption that the backdoor connections between triggers and target labels in backdoor attacks are simpler to learn than the benign features. We demonstrate that this assumption, however, does not always hold, especially in all-to-all (A2A) and untargeted (UT) attacks. As a result, purification methods that analyze the separation between the poisoned and benign samples in the input-output space or the final hidden layer space are less effective. We observe that this separability is not confined to a single layer but varies across different hidden layers. Motivated by this understanding, we propose FLARE, a universal purification method to counter various backdoor attacks. FLARE aggregates abnormal activations from all hidden layers to construct representations for clustering. To enhance separation, FLARE develops an adaptive subspace selection algorithm to isolate the optimal space for dividing an entire dataset into two clusters. FLARE assesses the stability of each cluster and identifies the cluster with higher stability as poisoned. Extensive evaluations on benchmark datasets demonstrate the effectiveness of FLARE against 22 representative backdoor attacks, including all-to-one (A2O), all-to-all (A2A), and untargeted (UT) attacks, and its robustness to adaptive attacks.