 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncrypted Large Model Inference: The Equivariant Encryption Paradigm
Feb 03, 2025Large scale deep learning model, such as modern language models and diffusion architectures, have revolutionized applications ranging from natural language processing to computer vision. However, their deployment in distributed or decentralized environments raises significant privacy concerns, as sensitive data may be exposed during inference. Traditional techniques like secure multi-party computation, homomorphic encryption, and differential privacy offer partial remedies but often incur substantial computational overhead, latency penalties, or limited compatibility with non-linear network operations. In this work, we introduce Equivariant Encryption (EE), a novel paradigm designed to enable secure, "blind" inference on encrypted data with near zero performance overhead. Unlike fully homomorphic approaches that encrypt the entire computational graph, EE selectively obfuscates critical internal representations within neural network layers while preserving the exact functionality of both linear and a prescribed set of non-linear operations. This targeted encryption ensures that raw inputs, intermediate activations, and outputs remain confidential, even when processed on untrusted infrastructure. We detail the theoretical foundations of EE, compare its performance and integration complexity against conventional privacy preserving techniques, and demonstrate its applicability across a range of architectures, from convolutional networks to large language models. Furthermore, our work provides a comprehensive threat analysis, outlining potential attack vectors and baseline strategies, and benchmarks EE against standard inference pipelines in decentralized settings. The results confirm that EE maintains high fidelity and throughput, effectively bridging the gap between robust data confidentiality and the stringent efficiency requirements of modern, large scale model inference.
Meta-Learning for Speeding Up Large Model Inference in Decentralized Environments
Oct 28, 2024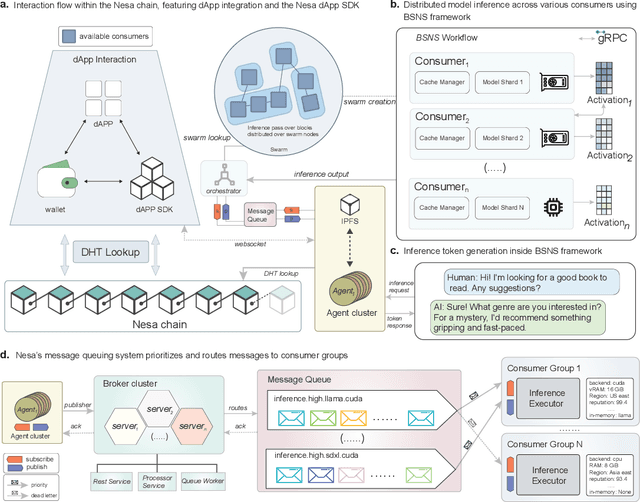
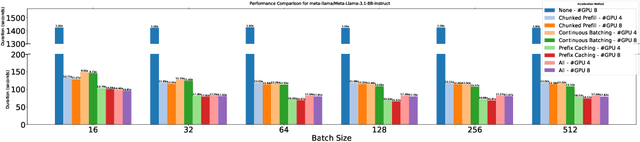
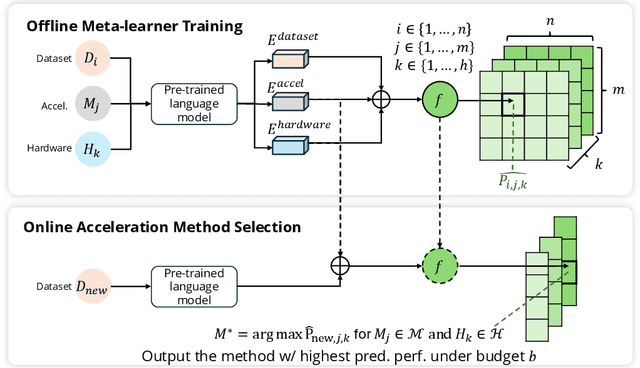
The deployment of large-scale models, such as large language models (LLMs) and sophisticated image generation systems, incurs substantial costs due to their computational demands. To mitigate these costs and address challenges related to scalability and data security, there is a growing shift towards decentralized systems for deploying such models. In these decentralized environments, efficient inference acceleration becomes crucial to manage computational resources effectively and enhance system responsiveness. In this work, we address the challenge of selecting optimal acceleration methods in decentralized systems by introducing a meta-learning-based framework. This framework automates the selection process by learning from historical performance data of various acceleration techniques across different tasks. Unlike traditional methods that rely on random selection or expert intuition, our approach systematically identifies the best acceleration strategies based on the specific characteristics of each task. We demonstrate that our meta-learning framework not only streamlines the decision-making process but also consistently outperforms conventional methods in terms of efficiency and performance. Our results highlight the potential of meta-learning to revolutionize inference acceleration in decentralized AI systems, offering a path towards more democratic and economically feasible artificial intelligence solutions.
Model Agnostic Hybrid Sharding For Heterogeneous Distributed Inference
Jul 29, 2024The rapid growth of large-scale AI models, particularly large language models has brought significant challenges in data privacy, computational resources, and accessibility. Traditional centralized architectures often struggle to meet required data security and scalability needs which hinders the democratization of AI systems. Nesa introduces a model-agnostic sharding framework designed for decentralized AI inference. Our framework uses blockchain-based sequential deep neural network sharding to distribute computational tasks across a diverse network of nodes based on a personalised heuristic and routing mechanism. This enables efficient distributed training and inference for recent large-scale models even on consumer-grade hardware. We use compression techniques like dynamic blockwise quantization and mixed matrix decomposition to reduce data transfer and memory needs. We also integrate robust security measures, including hardware-based trusted execution environments to ensure data integrity and confidentiality. Evaluating our system across various natural language processing and vision tasks shows that these compression strategies do not compromise model accuracy. Our results highlight the potential to democratize access to cutting-edge AI technologies by enabling secure and efficient inference on a decentralized network.
Complete Security and Privacy for AI Inference in Decentralized Systems
Jul 28, 2024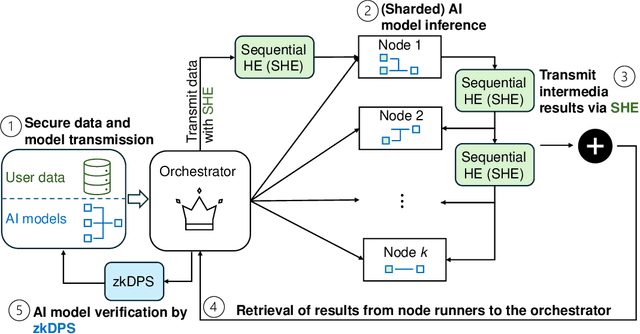

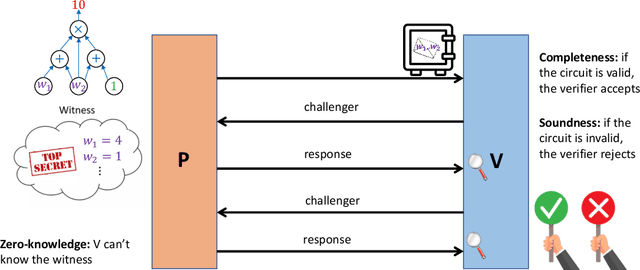

The need for data security and model integrity has been accentuated by the rapid adoption of AI and ML in data-driven domains including healthcare, finance, and security. Large models are crucial for tasks like diagnosing diseases and forecasting finances but tend to be delicate and not very scalable. Decentralized systems solve this issue by distributing the workload and reducing central points of failure. Yet, data and processes spread across different nodes can be at risk of unauthorized access, especially when they involve sensitive information. Nesa solves these challenges with a comprehensive framework using multiple techniques to protect data and model outputs. This includes zero-knowledge proofs for secure model verification. The framework also introduces consensus-based verification checks for consistent outputs across nodes and confirms model integrity. Split Learning divides models into segments processed by different nodes for data privacy by preventing full data access at any single point. For hardware-based security, trusted execution environments are used to protect data and computations within secure zones. Nesa's state-of-the-art proofs and principles demonstrate the framework's effectiveness, making it a promising approach for securely democratizing artificial intelligence.