 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugMask: Training Diffusion Models on Incomplete Tabular Data via Stochastic Augmentation and Masking
Jun 02, 2026Score-based diffusion models have emerged as prominent deep generative models; however, their application to tabular data remains challenging because their backbones assume fully specified inputs, whereas real-world tabular data often contain missing values. We propose AugMask, a plug-and-play training framework that adapts missing-unaware backbones to incomplete data by separating conditioning from supervision. AugMask 1) constructs numeric inputs via conditional stochastic augmentation using lightweight auxiliary models, and 2) applies denoising supervision only to observed coordinates. In effect, augmented missing entries serve as uncertain conditioning context rather than training targets. We connect this training rule to a Rao--Blackwellized objective and show that marginalizing missing entries yields a variance-weighted sensitivity penalty, discouraging over-reliance on uncertain completions. Across diverse datasets and missingness regimes, AugMask enables standard diffusion-based tabular generators to outperform specialized missing-aware baselines.
To Predict or Not To Predict? Proportionally Masked Autoencoders for Tabular Data Imputation
Dec 26, 2024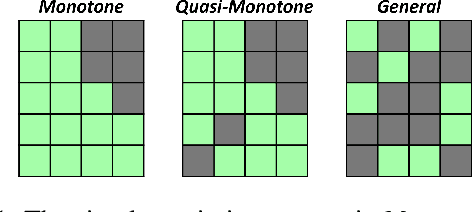
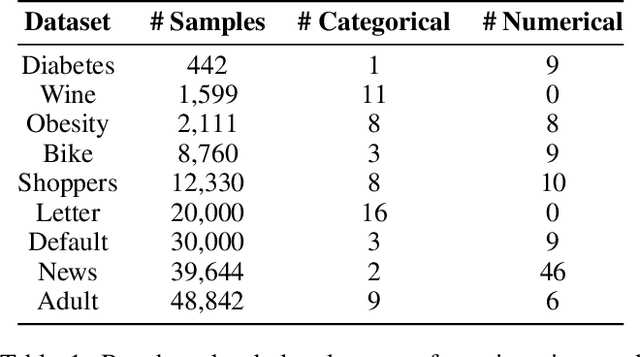
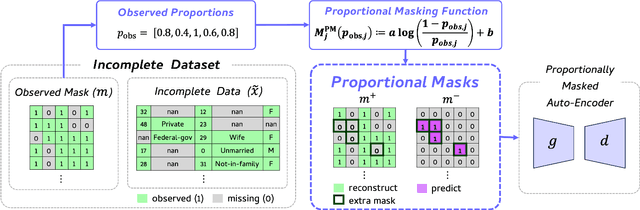
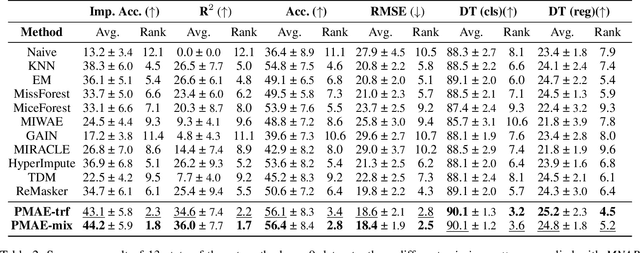
Masked autoencoders (MAEs) have recently demonstrated effectiveness in tabular data imputation. However, due to the inherent heterogeneity of tabular data, the uniform random masking strategy commonly used in MAEs can disrupt the distribution of missingness, leading to suboptimal performance. To address this, we propose a proportional masking strategy for MAEs. Specifically, we first compute the statistics of missingness based on the observed proportions in the dataset, and then generate masks that align with these statistics, ensuring that the distribution of missingness is preserved after masking. Furthermore, we argue that simple MLP-based token mixing offers competitive or often superior performance compared to attention mechanisms while being more computationally efficient, especially in the tabular domain with the inherent heterogeneity. Experimental results validate the effectiveness of the proposed proportional masking strategy across various missing data patterns in tabular datasets. Code is available at: \url{https://github.com/normal-kim/PMAE}.
Partial Channel Dependence with Channel Masks for Time Series Foundation Models
Oct 30, 2024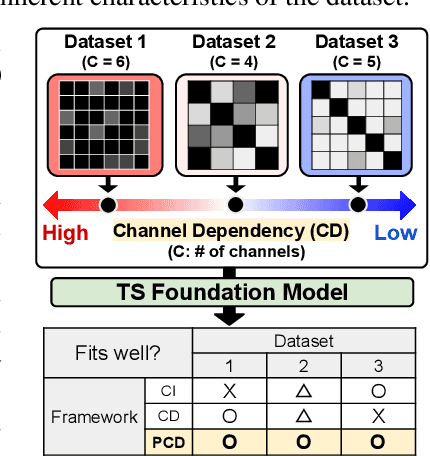
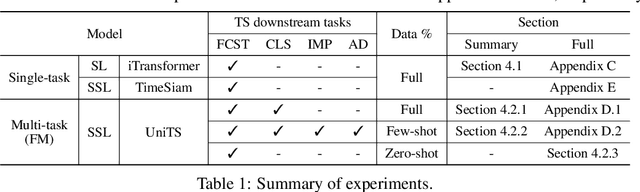
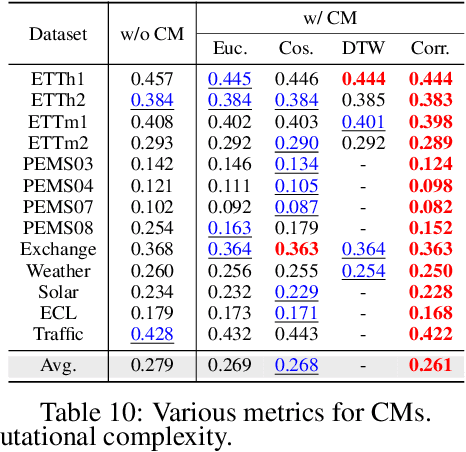
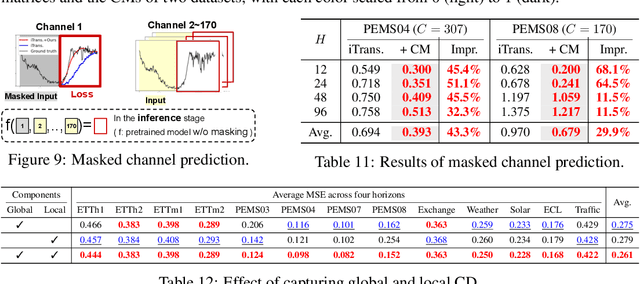
Recent advancements in foundation models have been successfully extended to the time series (TS) domain, facilitated by the emergence of large-scale TS datasets. However, previous efforts have primarily focused on designing model architectures to address explicit heterogeneity among datasets such as various numbers of channels, while often overlooking implicit heterogeneity such as varying dependencies between channels. In this work, we introduce the concept of partial channel dependence (PCD), which enables a more sophisticated adjustment of channel dependencies based on dataset-specific information. To achieve PCD, we propose a channel mask that captures the relationships between channels within a dataset using two key components: 1) a correlation matrix that encodes relative dependencies between channels, and 2) domain parameters that learn the absolute dependencies specific to each dataset, refining the correlation matrix. We validate the effectiveness of PCD across four tasks in TS including forecasting, classification, imputation, and anomaly detection, under diverse settings, including few-shot and zero-shot scenarios with both TS foundation models and single-task models. Code is available at https://github.com/seunghan96/CM.
Sequential Order-Robust Mamba for Time Series Forecasting
Oct 30, 2024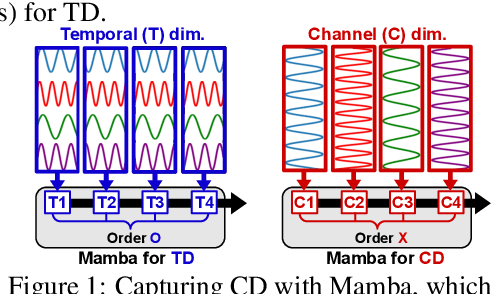
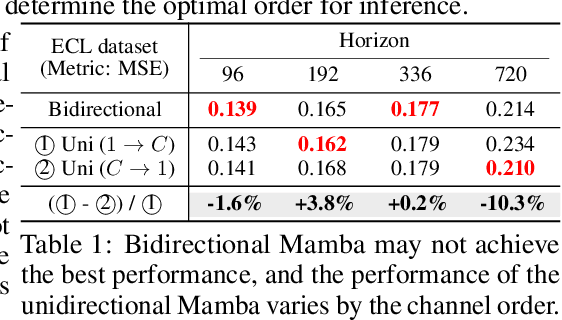
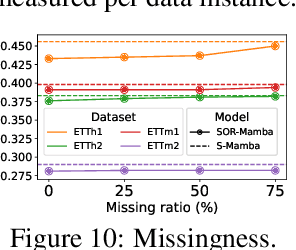
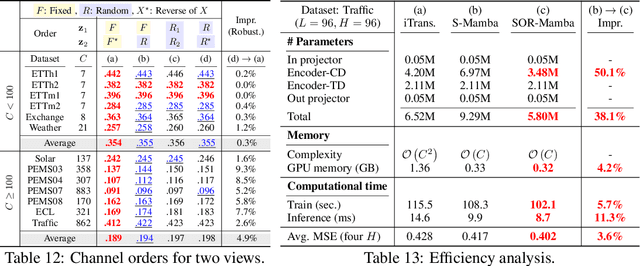
Mamba has recently emerged as a promising alternative to Transformers, offering near-linear complexity in processing sequential data. However, while channels in time series (TS) data have no specific order in general, recent studies have adopted Mamba to capture channel dependencies (CD) in TS, introducing a sequential order bias. To address this issue, we propose SOR-Mamba, a TS forecasting method that 1) incorporates a regularization strategy to minimize the discrepancy between two embedding vectors generated from data with reversed channel orders, thereby enhancing robustness to channel order, and 2) eliminates the 1D-convolution originally designed to capture local information in sequential data. Furthermore, we introduce channel correlation modeling (CCM), a pretraining task aimed at preserving correlations between channels from the data space to the latent space in order to enhance the ability to capture CD. Extensive experiments demonstrate the efficacy of the proposed method across standard and transfer learning scenarios. Code is available at https://github.com/seunghan96/SOR-Mamba.
ANT: Adaptive Noise Schedule for Time Series Diffusion Models
Oct 18, 2024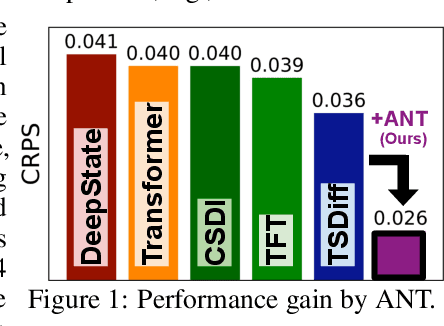
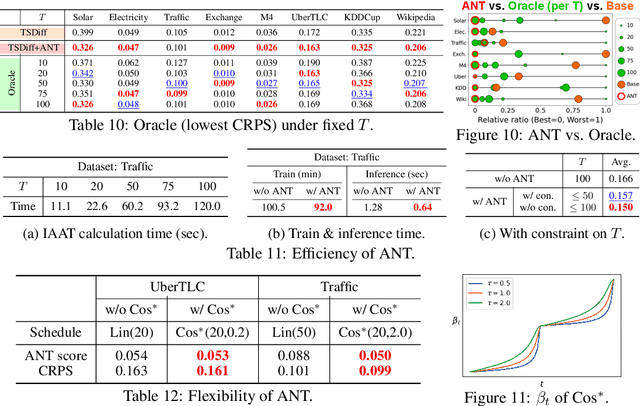
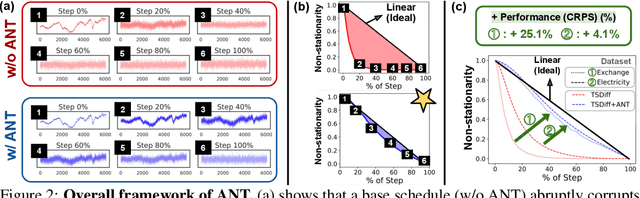
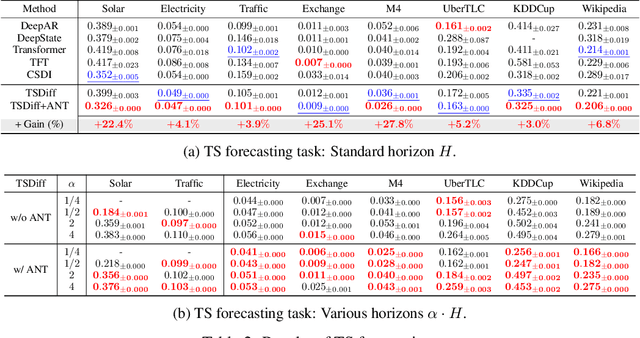
Advances in diffusion models for generative artificial intelligence have recently propagated to the time series (TS) domain, demonstrating state-of-the-art performance on various tasks. However, prior works on TS diffusion models often borrow the framework of existing works proposed in other domains without considering the characteristics of TS data, leading to suboptimal performance. In this work, we propose Adaptive Noise schedule for Time series diffusion models (ANT), which automatically predetermines proper noise schedules for given TS datasets based on their statistics representing non-stationarity. Our intuition is that an optimal noise schedule should satisfy the following desiderata: 1) It linearly reduces the non-stationarity of TS data so that all diffusion steps are equally meaningful, 2) the data is corrupted to the random noise at the final step, and 3) the number of steps is sufficiently large. The proposed method is practical for use in that it eliminates the necessity of finding the optimal noise schedule with a small additional cost to compute the statistics for given datasets, which can be done offline before training. We validate the effectiveness of our method across various tasks, including TS forecasting, refinement, and generation, on datasets from diverse domains. Code is available at this repository: https://github.com/seunghan96/ANT.
Soft Contrastive Learning for Time Series
Dec 27, 2023
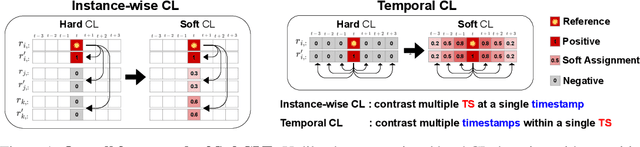
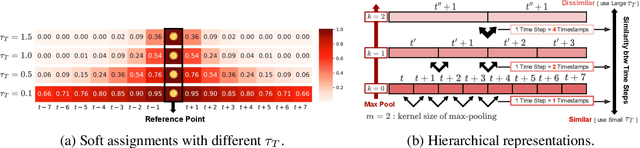
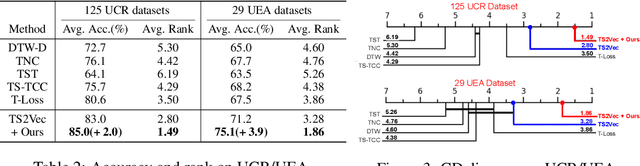
Contrastive learning has shown to be effective to learn representations from time series in a self-supervised way. However, contrasting similar time series instances or values from adjacent timestamps within a time series leads to ignore their inherent correlations, which results in deteriorating the quality of learned representations. To address this issue, we propose SoftCLT, a simple yet effective soft contrastive learning strategy for time series. This is achieved by introducing instance-wise and temporal contrastive loss with soft assignments ranging from zero to one. Specifically, we define soft assignments for 1) instance-wise contrastive loss by the distance between time series on the data space, and 2) temporal contrastive loss by the difference of timestamps. SoftCLT is a plug-and-play method for time series contrastive learning that improves the quality of learned representations without bells and whistles. In experiments, we demonstrate that SoftCLT consistently improves the performance in various downstream tasks including classification, semi-supervised learning, transfer learning, and anomaly detection, showing state-of-the-art performance. Code is available at this repository: https://github.com/seunghan96/softclt.
Learning to Embed Time Series Patches Independently
Dec 27, 2023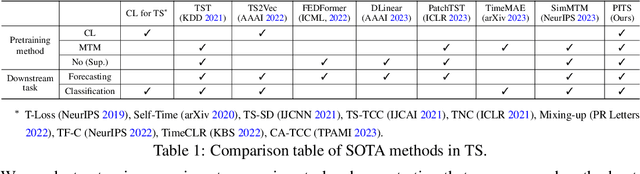
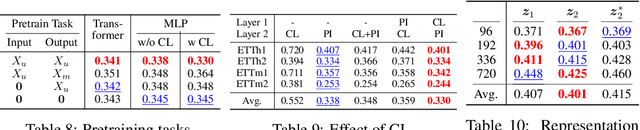
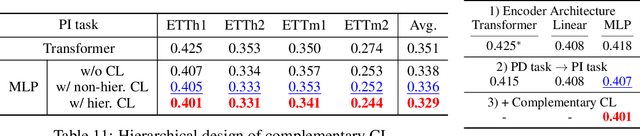
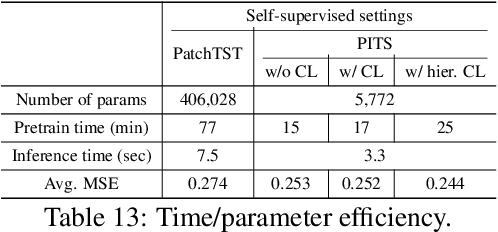
Masked time series modeling has recently gained much attention as a self-supervised representation learning strategy for time series. Inspired by masked image modeling in computer vision, recent works first patchify and partially mask out time series, and then train Transformers to capture the dependencies between patches by predicting masked patches from unmasked patches. However, we argue that capturing such patch dependencies might not be an optimal strategy for time series representation learning; rather, learning to embed patches independently results in better time series representations. Specifically, we propose to use 1) the simple patch reconstruction task, which autoencode each patch without looking at other patches, and 2) the simple patch-wise MLP that embeds each patch independently. In addition, we introduce complementary contrastive learning to hierarchically capture adjacent time series information efficiently. Our proposed method improves time series forecasting and classification performance compared to state-of-the-art Transformer-based models, while it is more efficient in terms of the number of parameters and training/inference time. Code is available at this repository: https://github.com/seunghan96/pits.